Welcome to the kriha.org weblog

- First Security Day at HDM - from platforms to applications
-
The Security Day will cover roughly four areas of security: platforms (which become increasingly important as we get the internet threat models under control), infrastructure (which shows limits, e.g. firewalls), applications (currently the hottest topic of security research and threats) and last but not least crpyto-related research.
HDM members as well as external specialists will demonstrate the latest in security research and development. How do you apply electronic signatures in real-live applications? How do you run a host-based IDS and what will you gain by doing so? What are the consequences for maintenance and application development? What's new in Windows Vista with respect to security? How do mobile DRM systems work? How do you run the security of a large provider?
There should be something for everybody interested in security and there will be time for discussions on current threats, developments and countermeasures. Viewers on the internet can use a live chat channel to raise their questions.
This is the first security related event at HDM, organized by the CS&M faculty. There was a huge number of speakers interested in participating and we could only select a few this time. So you can expect another Security Day in the near future.
Note
You will find the program for the Security Day at HDM homepage. We will start at 9.00 on the 12th of January. As usually the event will be streamed to the internet.
- The problem of many speakers...
-
Events with a large number of guests currently suffer from our inability to capture the voices from speakers besides the main speaker(s) in front of the audience. Right now I am running around with a microphone and in the case somebody just starts to talk (like in a lively discussion) we need to yell "stop" and the speaker has to wait for the microphone to be brought to him.
I would love to see a solution for this problem because it is both tiring and kills every discussion just for the benefit of our internet viewers. Our audience would not need a microphone in most cases as the rooms are not this big. But the internet viewers do no hear the questions if we do not keep strict microphone discipline.
Unfortunately there seems to be no good and affordable solution to this problem. The solution should also be mobile btw. as we won't be in the same room with every event.
Video seems to be so much easier than audio - just point the camera at somebody. But how do we capture audio? I have seen long sticks with microphones attached. Really ugly because it threatens participants which are sitting under those sticks. Permanent installations are too expensive and we would need them in several rooms.
The following ideas try to solve this problem. The first one is based on balloons floating at the ceiling of a room. The microphone is attached to an extensible string that hangs down from the balloon. A speaker can grab the cord and pull the microphone to him.

There need to be several of those ballon-microphones in a larger room so that all speakers have a chance to talk. Each microphone should be able to work like a phone-conference microphone (which means it should serve around 4 people in one position concurrently). Around 6-10 people should have easy access to the microphone dangling from the ceiling.
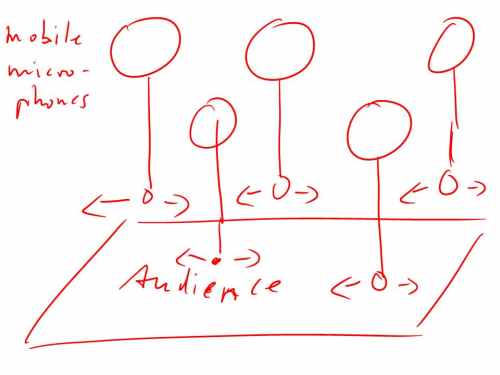
Another idea is a throwable microphone. It has the same group conference abilities as described above but can be thrown (better: easy and fast hand-off to other speakers) around. Typically discussions evolve between groups and throwable microphones would reach those groups quickly.

An important aspect of both solutions is how the sound engineer can identifiy which microphone is in use. The throwable microphone would have a button that needs to be pressed while speaking. This will automatically suppress all others and signal the working microphone to the sound engineer. The balloon solution could do the signaling via coloured lights.

Anyway - if you know a better solution for this problem, please let me know. But before I forget: the requirements are as follows:
Affordable on a university budget (which means in our days: dirt-cheap) Mobile - we need to use it in different rooms and cannot go for a permanent installation Superior usability - this goes with mobile and the fact that students and myself need to run it after a few minutes of introduction. Easy to build and store does not require personnel (as the stick approach e.g. does) - Things learned on Games Day
-
Our so called "days" at HDM are supposed to bring new ideas and developments into our faculty. The second Games Day was no different in this respect. But this time new trends and developments became very visible - like the need for distributed development - and the last presentation might even push the faculty into new ways to organize learning in projects: cross-faculty, cross-university teams of different areas working on one goal. But let's tale ot step by step.
If there was any doubt about how professional games development has become Louis Natanson from our partner-university at Abertay Dundee was able to destroy it quickly. He showed the structure and organization of a bsc and master program of game development. It is clearly based on a very good knowledge in general computer science topics. On top of that students learn (mostly in groups) the key factors of modern games development: concept art, business functions and last but not least how to create large games.
And there is more: students all over the world can compete in Abertay games competitions. (see: Daretobedigital) Louis is also trying to get a collaboration between universities going that would allow students to get the finishing touch of game development at Abertay while laying the foundation at their home universities - definitely something we will look into here at HDM.
Another interesting thing are the certifications students of games development can get in the UK. Looks like the games industrie and universities like Abertay really have established a core concept of what it takes to be a games developer.
Like the computer science and media department at HDM the games department at Abertay strongly believes in team based projects and a strong foundation in comuter science.
This is another lesson to be learned from our Games Day and it was delivered through Stefan Baier of Streamline Software in Amsterdam: the future of multi-media productions already IS very much a distributed process - both with respect to programming and content. Stefan Baier gave a very interesting talk on the demands of those development teams: they consist of a large number of specialists in different areas and work together from different locations. The production process seems to be closer to movie productions and IT project management may not be the right methodology to cover the whole process
Artists and technical people need to form ad-hoc virtual organizations. They need to communicate frequently and open. Tool standards are important but not a reality nowadays. The degree of outsourcing is mind boggling: one company renders buildings while the other renders the roads and traffic signs for the same frame.
Distributed content production does not stop there. Different content from different media is now integrated into games via wikis, homepages etc. and become part of the game.
How can we prepare our students for this type of environment? Perhaps the answer will come from the last presentation of the day - our own games project at HDM (see below).
Stefan Baier mentioned that consumers have ever increasing expectations on games, especially the 3D graphics. Some game companies are getting scared and fear that they cannot answer those expectations in the future. But help might come from hardware sides: Michael Engler of IBM Böblingen demonstrated the powerful features of the new Cell chip - which e.g. powers the new Sony Playstation 3. It is a mean machine: a general purpose risc core (power Pc) and 8 vector units which achive around 200 Gflops/sec.
Michael Engler demonstrated realtime ray-tracing, realtime CT slicing etc. - but the core question is: how difficult is it to adjust to this new hardware? It looks like that it won't be very difficult because many standard interfaces (opengl e.g.) have been ported to the platform. The new SDK2.0 has just been released and if we are lucky we will have a project for the Cell chip beginning next term at CS&M.
Then the next "aha" effects where just around the corner: Jan Hofmann and Oliver Szczypula, professional sound designers, have just finished their studies of audio-visual media at HDM and they gave us an introduction into sound and music development for games. They showed lots of examples for sound icons, atmo music etc. from their own production "Ankh" (which received lots of prices and honours) and other current games. The level of quality achieved is amazing and they showed how hardware evolved to deliver this quality in realtime.
Before the talk audio and sound in games was not really a concern for me (I am not even sure whether I distinguised properly between them). I learned a lot from this talk. The most important piece being that audio is the major factor not only for emotions in games but also for steering players through levels, transporting game events, making players aware of game things etc. Audio and sound for games are completely different from regular productions - even though e.g. the audio parts are more and more created through professional orchestras like in the case of Gothic3. Audio and sound in games needs to follow the camera position and needs to be dynamic therefore. On top of this problem audio and sound can start fighting with each other. In those cases the speakers may become hard to understand. This means audio and sound need to be carefully aligned with game flow - stop when big things happen or carry players across changing scenes. Audio and sound are core game elements and the existence of audio engines or sound engines is therefore simply a necessity. Unfortunately many gamers and players just think about the 3D games engines and forget about the audio.
Another interesting result of their talk was the idea to involve the games company both are currently working for in our third Games Day in the summer term. I will be looking forward to some interesting demos.
After a lot of technology and games economy stuff we took a dive into the social consequences of gaming. Petra Reinhard-Hauck showed positive aspects of games (better motion control, social experiences, computer know-how) as a result of current studies in media. The numbers Dr. Reinhard-Hauck showed where very interesting as they also showed a big difference between girls and boys in the way the computer is used. Is the reason for the low numbers of women in IT somewhere hidden behind those numbers? Looks like the next Games Day should have a talk on "women in games"...
Dr. Reinhard-Hauck caused quite a number of lively discussions between our guests and students on the effects of games. There was a number of students which emphasized negative aspects as well like the loss of social skills and the dangers of getting lost in the virtual world. Most attendends agreed though on the statement that games alone cannot be blamed for school shootings. The fact that the Stuttgarter Zeitung sent a journalist to our event and ran an article on Dr. Reinhard-Hauck in todays SZ just demonstrates the social and political importance of computer games.
The last presentation of the day was on our own large-scale games project "the city of Noah". Started by Thomas Fuchsmann and Stefan Radicke (who also got us in touch with the previous speaker Dr. Reinhard-Hauck - many thanks!) the project has now attracted specialists from different areas: story design, sound, music, programming and last but not least project management. 30 students from HDM and University of Stuttgart are working together on this ongoing project.
Besides all the artistic and technical elements of this project there is one point that seems to stick out because of its importance for the project overall: project management. The students reported that the skill learnt in IT-Project Management (by my friend Mathias Hinkelmann) were an invaluable asset for this type of project. The high degree of parallel development (programming, concept arts, music) is certainly a problem because all these parts somehow depend on each other. In this case it meant that the musicians have to image most of the game flow and create sound and music in advance.
A very interesting fact that the students pointed out was that the overall management of such a projects seems to require the skills of movie directors - something Stefan Baier hat mentioned before in his talk as well. IT is only a part of such a project and perhaps not even the most important one. Much to the surprise of Louis Natanson the students did not have any problems between the "artists" and the "programmers" in this project. Many projects are plagued by differences between the creative and the constructive (;-) groups. There is perhaps another lesson to learn behind this fact: does open (source) organization prevent some of the typical fightings?
Given the current problems of organizing such a big project the next idea seems to be rather crazy: the next goal could be to start distributed games development as a grass-roots effort between universities. Because you can only learn distributed development in a truly distributed environment. We would have to acknowledge the cost of communication overhead in those types of environements - but that is just what needs to be learned.
At HDM we have to do some homework now: how can we support such cross-faculty teams better? Students of all faculties should have the option to participate in such projects and get their respective ECTS points for this. How does faculty staff interface with those projects? How can we help and guide while still letting the students decide?
The games project has the potential of changing the way we study and work at HDM. It could change this toward even more collaboration between students and staff and between students - beginning with the first term. The future definitely is collaborative and an important part of this is the language to understand each other. In most cases nowadays this will be english -whether you like it or not. And I was quite pleased that the first three talks were in english because it demonstrated what sill one needs to have to be successful in our business. Which leads to the next question: how do we increase language skills with our students?
- In the name of security - or how your past will haunt you
-
My friend Sam Anderegg pointed me recently to an interview with a representative of a security company specializing in "background" checks on personnel. The case in question was a security incident that happened at Paine-Webber a couple of years ago. A disgruntled sys-admin quit but nor before placing some malware on more than 2000 server machines. Paine-Webber had a hard time to fix their machines and to guarantee the correct releases of software being installed.
The representative from the security company claimed that a simple "background check" would have revealed so much information on the employee that he would have never become a sys-admin with root privileges within Paine-Webber. He mentioned a drug offense in the SIXTIES!! as one of the facts that could be found easily within 24 hours using public information from the web.
But the representative went way beyond that. He told that not only criminal records should be locked at. Also private credit information, educational records etc. should be evaluated by companies. And not only once but repeatedly because employees might get promoted.
This story has some well known ingredients: an abundance of private information that is not protected from abuse. Private theories on what makes a person unreliable (how old can an offense be to still be of value? What are "critical" offenses? A security company trying to make money by distributing fear (what, you don't do "background" checks in your company?) and so on.
In the name of security there seems to be no stopping companies from violating even basic human rights. Last night I read that the CIA tapped Princess Dianas phone in the Hotel the night she died. Is there still anybody around to question the practices of those secret services? Or does the (remote) threat of terrorism justify anything?
Discussion on Slashot: Slashdot
But there is also a technical part to the story: how could one person control ALL the IT infrastructure of the company? Banks use clever mechanisms in case one person alone cannot be completely trusted: the famous four-eye-principle e.g. or the use of several keys for a safe. Why aren't those mechanisms used in IT? As long as we use the concept of a global admin we will inevitably have the danger of disgruntled employees to cause havoc with our systems. And no amount of secreening will prevent this as we cannot predict a human beings actions.
This means that our systems need to apply POLA on all layers. Once the damage one person can do is reduced the social and political dangers of the screening process described above can be easily avoided. Right now - based on our vulnerable systems - the screening gives a false sense of security and is a danger for our society at the same time. Time to put pressure on our platform vendors.
- 2. Games Day at HDM - Technology, Arts and Economics of Computer Games
-
Politics and media seem to have found the final culprit behind troubled students: computer games. Of course it is easier to blame a couple of games for shootings at schools than to fix the many problems that plague our schools nowadays. Lack of money, social problems of the new "Unterschicht" which has been carefully created in the years of Kohl and Schröder and so on.
The second games day offers an enticing mix of talk on various aspects of games development, including positive aspects of computer games, cell chip internals, game economics and sound in games. Louis Natanson from Abertay University will present their studies on games and creativity. The program is designed for a larger audience from different faculties, the industry or even game fans.
Note
You will find the program for the Games Day at HDM homepage. We will start at 9.00 on the 15th of December.
- WEB2.0 at HDM - get ready for your dose of tag soup
-
The event coming friday is very special for several reasons: it has an excellent list of speakers ranging from social sciences to hard-core technology. But that is not all. This event has both external specialists (e.g. STSM's from IBM, Adobe specialists etc.) but also some very good internal members of CS&M who will demonstrate the level of knowledge available at HDM. And but not least the event is a WEB2.0 event: it has been planned collaboratively with students and collaborative WEB2.0 tools have been used extensively (writeboard, project management).
When I look at the program and how it got created it is absolutely clear to me that our approach of organizing such events together with our students is the right approach. It avoids me becoming a bottleneck due to a lack of time and it teaches event-organization effectively - something our students will need when they work in technical areas later. The approach got started with our first games day last semester and it seems like it would be able to continue for a long time.
Note
You will find the program for the Web2.0 day at HDM homepage. We will start at 8.30 on the 1st of December.
- Beyond SOA - event-driven architectures
-
Our SOA seminar with IBM had lots of good talks on enterprise architectures and problems. The knowledge needed to work within the bounds of a large, international enterprise is staggering but where do you learn the terminology and technology needed? From past experience I'd say there is a lot of learning by doing involved. But how do you prepare in a systematic way?
There is some good literature available and I'd like to discuss two very special books on the topic of enterprise software. The first one is the seminal work by Martin Fowler (who I met years ago in Basle) "Patterns of Enterprise Architectures". Fowler knows business patterns very well and this book will take you through all the tiers of enterprise software. It will teach you how to organize GUIs, business logic and data storage. It has a lot of information on how to structure information and objects to create fast and flexible applications.
The second book is quite the opposite with respect to structure: it has its focus on interaction patterns. "Enterprise Application Integration patterns" is a treasure chest for people in need of integration know-how. Gregor Hohpe and his colleague take you through all the technologies needed to decouple applications and create maintainable but secure and reliable software based on messages. The icons shown at the IBM SOA seminar did remind me about Hohpe's book and I am glad I had a look at the Enterprise Integration patterns homepage because I found a wealth of very good articles on event-driven architectures. Hohpe's paper on EDA is on of the best introductions to this topic that I saw yet. It discusses the following topics:
Call stack architectures and the hidden assumptions behind them (speed, sequential processing, coupling between caller/callee) , coodination, continuation and context as the core principles of call stack architectures Assumptions as the major tool to analyze de-coupling (do you know what creates coupling between components?) The different way state is handled in EDA systems: participants store events they think they will need later. This creates replicated state automatically. I loved his example of an order received: The posting of this event creates a number of related postings, e.g. the shipping address. The shipping service will collect those postings and use them later. Speaking of events: the abstraction level of event-driven architectures can be higher than SOA systems: In SOA services are explicitely called. Callers may not need to know the components behind the service (e.g. checkCreditCard) but they need to call that service from within their code. A simple posting on a higher abstraction level (e.g. "Order received" avoids this tight coupling. Take a look at the diagram of call abstractions ranging from calling a component over calling a service to just posting an event. The power of asynchronous systems shows in many of Hope's examples (e.g. plug in tracing and monitor components into an enterprise bus or replay events in case of compensating actions. But his Starbucks example is hilarious. By a happy coincidence I use the "Sutter-begg" in Basle SBB on a regular base and it works almost like Starbucks: Once you arrive you need to yell you choice of coffee to the casher who in turn yells it to the baristas working in the back. But unlike Starbucks the casher seems to remember who ordered what and in most cases you are correlated with you choice of coffee properly. When you get your coffee you will pay - not before. This is good because only once you get the coffee you will need access to the (scarce) resource tablespace (no, not Oracles, Sutter-beggs tables) to prepare it (sugar etc.). And then you are right in front of the casher and might pay as well.
This example shows different strategies to handle the orders (half-sync/half-async) and different failure strategies (throw coffee away if delivered wronly - its not expensive to use this strategy but it speeds up things a lot compared to a two-phase-commit protocol. So take a look at the article "Starbucks does not use two-phase-commit".
Hohpe is not just painting a pretty picture: there are still subtle dependencies between communication partners in an EDA system and somebody will need to keep track on message formats and semantics, on subscriptions and postings to e.g. avoid registering for queues and topics which do not exist in the system. Another nice case where abstraction and information hiding (and de-coupling is a rather strong way of information hiding) needs to be balanced for the reasons of system management and security.
Speaking of which - I am currently pondering over mixing object capabilities with event-driven architectures. It seems to be the case that we absolutely need the concept of information besides capabilities - as it is e.g. modeled in the theoretical apporaches of Fred Spiessens et.al. The capability will control the channels and topics available to subjects.
- XLINK or AJAX?
-
I have not been following the XML-DEV list or XML development in general for a long time so please forgive me if I am beating a dead horse here...
Working on a book on software security I took a look at some Ajax technologies and their security implications. There are many different ways to contact servers and embed content into pages (XMLHttpRequest, dynamically added script tags etc.). And I was wondering: lots of code - and no tags?
That reminded me about Xlink - the one standard that surprised me completely by taking a long time to get finished and then to disappear (or did I miss something here?).
I was a big fan of HyTime and its powerful addressing and linking expressions. Looks like we got the addressing part (Xpath) but where is the linking? I guess the linking and embedding is now done with AJAX - in other words with code instead of a descriptive way.
I am not saying that all things in Web 2.0 could be done descriptively.But I am disappointed that it is not used at all (am I wrong here?)
Some ideas about the reasons: Did XLink in browsers raise too many security issues? (Cross-domain, same origing etc) If so, I don't see anything different if this is done in code instead of tags.
Tags would allow us to express the intentions more clearly and the implementations in agents are probably more stable than individual script code. (testability etc.). And there is the social side as well: many who publish today on the web learned it from looking at HTML source of other sites and copying the tags. But the skills to master large code bases in Javascript are not available to everybody.
Don't get me wrong: I sure like what can be done in Web2.0 today. But I am not so sure about the way it is done with code. To me it looks a bit like we have given up on the idea of information aggregation through tags. But if descriptive HyTime was too complex - doesn't the code have the same complexity just hidden somewhere?
If somebody could point me to some discussions on this topic I'd really appreciate it.
- Latest Awards for CS&M Students at HDM
-
Ron Kutschke - co-author of tradingservice - has received an award as the best graduate at HDM in 2006. His thesis has been advised by Stephan Rupp (now Kontron) and myself. Matthias Feilhauer has won the Carl Düisberg Gesellschaft (CDG) price for his thesis on electronic waste exports in developing countries (mentored by my friend Prof. Rafael Capurro)
- Web2.0 security and Google Maps, how does it work?
-
Google Maps is clearly a Web2.0 application which is loved by many. And many site owners integrate their content with Google Maps. Look at this example from sk8mag.de. But it also raises a couple of questions on the security behind Web2.0. A core element of AJAX or Web2.0 is the XMLHttpRequest - an asynchronous way to contact a server and get data for the current DOM, without the need to re-load the page. Following the "same origin principle" XMLHttpRequest is restricted by browsers to only call back to the server where the page came from.
But this would not allow sk8mag to integrate the maps. So google must do something else. Now there is a thing called dynamic script tags. In connection with JSON (javascript object notation - a way to serialize java objects) there is supposedly a way to contact ANY server from within a page and get data. But istn't this dangerous?
The two most common risks in such a case are about credentials (e.g. cookies) of the current page being exposed. And whether it would be possible to use a browser as a bridge between intranet and internet. lets say a user opens a browser window on the Internet, downloads Javascript with XMLHttpRequest code which then goes to a URL in the intranet and extracts data. Authentication requirements for the intranet would not help because the user is already logged in when SSO is used (the dangers behind automatic and transparent sign-in are a topic for usable security as well).
To make a long talk short: is there anybody out there who can explain to me how google maps works in the context of Web2.0 technologies? Any help would be seriously appreciated as I still got a lot of other things to do for our security book.....
To me it looks like we need to redefine browser security completely in the context of Web2.0 techniques. And do security inspections differently since now it is possible to change javascript code AFTER page load. I have collected a number of interesting links about AJAX security:
The whole topic seems to be a mixture of usability (seamless integration of different sites) and security (credentials, authority etc.) and while users might love the aggregation power of AJAX it needs a re-thinking of browser security in general. It can't be that servers completely take over the responsibility for the security of clients...
- Lyin' eyes: how they take our freedom away, more...
-
The cat jumps out of the bag:data from the german toll system are going to be used by "law enforcement" (police, bnd, mad, cia and so on). NOOOOOOOOOO! Toll data will never be available to "law enforcement" - that was when the toll system was introduced. The data were protected by law - and laws can change (look at the job card design - it suffers from the same weakness). The whole approach is called the domino system: step by step, piece by piece data are first collected and then (ab)used. First only in "severe cases of criminality", then always. And of course, "law enforcement" is quick in finding reasons for data access and how much better they could protect us if they only could.... This has always been the case and the public laws were made to protect us FROM "law enforcement". Schneier is right: whenever data are collected they will be used for other purposes as well. That is WHY THE LAW DOES NOT ALLOW DATA COLLECTION AND POLICE ACTIVITY WITHOUT DUE CAUSE! This was one of the most important principles put in place when states changed from monarchies and tyrannies to democracies!
Now the political caste wants to do away with this principle. Beckstein is the best as always (closely followed by the always agreeing SPD politicians which seem to change their position without any problems. Remember: this is supposedly the same party that had an Otto Wels take a stand against Hitler in the Reichstag and who's members suffered badly from Gestapo and police in the third reich.) Beckstein argues that telephone surveillance is leagal too. Yes, but at least today "law enforcement" still needs a due cause and in most cases even the approval of a judge to do so. And people are entitled to know about the surveillance at a later point in time.
But perhaps Beckstein simply thinks ahead: the EU wants to collect data WITHOUT cause for three years: Telephone, internet, you name it. So one could say that using toll data for "law enformcement" is just to make us compliant with future EU laws (;-). I wonder why they don't use this argument yet.
Did I mention that Becktein also wants a toll system for cars? Yes, but ONLY with vignettes - for now....
There is a massive shift underway to allow "law enforcement" general activities without due cause - something that has been reserved for secret services till now and carefully protected as it is a dangerous right. The Nazis introduced the famous "Blockwart" system: Every block/street had a person assigned to watch and spy over the inhabitants of this block. This spying happened without due cause, every day. The Gestapo used the data collected for their purposes. I wonder when Beckstein is going to propose a "democratic" version of the Blockwart system.
Armin Jäger CDU said: it has always been a principle of the CDU to put security and law-enforcement above data protection. Don't they ever learn a thing from history?
- Modeling of operational aspects and how to get wheel chairs mobile
those where two recent thesis works I'd like to present here. Mirko Bley developed a domain specific language to cover operational aspects (deployment, runtime) in the large PAI infrastructure project at DaimlerChrysler. He shows the modeling problems behind a DSL, how a DSL is used to generate artifacts using eclipse tools and shows how constraints are currently handled. The thesis gave me a lot to think about, e.g. whether we could use the same approach to model security aspects and how we could use the large infrastructure project in systems management and generative computing classes of our computer science master. The title of the thesis is "Modeling of operational aspects in System Infrastructures" and is an excellent way to learn about DSL development and associated tools. BTW: Mirko decided to not use UML as it does not cover operational aspects currently. SysML seems to be much more geared toward system architectures and desing and not so much towards operating systems.
Verena Schlegel has been working on usability problems for quite a while now. In the past she and her colleagues had won prices for re-engineering large applications for usability. For her thesis she decided to work at Fraunhofer IAO in the ambient intelligence project. Her job was to develop and test a user centered design for wheel chair users and their mobility problems. She designed a site which aggregated information important for wheel chair users (like transportation, toilets, information etc.) and tested it empirically with specially created test materials. Tons of ideas about this as well: how to integrate web 2.0 technologies here? How to model and test user conceptual models? Every picture, term and process in this design had to be tested for usability. A special problem are complex planning processes, e.g. planning a larger trip. We don't want to overwhelm the users or let them drown in steps and towers of information. The techniques Verena Schlegel used to reduce the complexity of planning processes should be studied be every student working in process modelling.
- On war, criminals and talking straight
A good friend and colleague of mine - a very gentle person - took his family to Lebanon two days before Israel started the war against the Lebanese nation. He and his wife are from Lebanon and every year they go back to see their parents which live in the southern part of lebanon. He is back now - after spending two days hiding from bombs he took his wife and three year old daughter on a dangerous trip to Damaskus and left as soon as possible. No chance to see his parents which are now living in cellars. And now Israel announced that the people in southern Lebanon have to leave: "leave now or get killed - it is your choice".
I talked to my friend yesterday and got a real-life account on what is going on in Lebanon right now. Not what google news is telling us currently, but I get to this later. My friend told me that this is an outright war against the lebanese people. The Israelis do not distinguish between civilians and hizbullah or army. The death count under civilians is rising every day and is now already exceeding 400 (including UN personnel which is attacked nevertheless). And this is before the ground war really started. (Even though I read in german media that soldiers from israel are already "working" (yes! they media called it working) since days in Lebanon)
The infrastructure in Lebanon - built in many years after the last devastating war -is purposefully destroyed by Isreal. Wells, bridges, everything. A whole generation of Lebaneese young will have to work soleyly to rebuild what is destroyed now. This is NOT a military attack. This is the same war crime as the allies committed against Hamburg, Dresden and other places in world war II.
US backed Isreal seems to have lost all reason. No - the actions are very much planned and make a lot of sense given the right perspective: It is unknown what will happen in the US elections in fall. Perhaps the current elite of oil/military/religious leaders will lose the election. Better to hit now.
The strategy: it is well known and it has two components. The first component was executed successfully during the last couple of month: It is called destabilization. Make a few spectaculars concessions but at the same time do new settlements on foreign land and declare that you will never get out of other illegal settlements. Allow an election but when you don't like the outcome just throttle the palestinian money supplies. Ever seen a government run a country successfully without money? And this on top of the permanant humiliation that Palestinians receive through israelian forces. Klaus Theweleit ("der Knall") describes such strategies of de-stabilization used by western politicians in the war at the balkan.
Another excellent work on how to start a war is Manfred Messerschmidts study on how the US entered WWII in the pacific area. We all know Pearl Harbor - but who talks about the US cutting the Japanese off from their oil supplies first? Can you survive without OIL being an industrialized nation?
The second component is to claim self-defense as the reason for attack. This has been executed beautifully by Hitler ("Vorwärtsverteidigung", Bush, Isreal and many others in the past. Take some minor event (carefully nurtured during the first phase of de-stabilization) and blow it completely out of proportion. Did you ever compare the number of people killed in the so called 9/11 event with the current death toll in Irak? Two kidnapped soldiers against hundreds of dead civilians? The number of Israeli killed vs. the number of Palestinians? This will at least show you who REALLY is in power.
Strategies are based on long-term socio-economic developments - a thinking that german historician Hans-Ulrich Wehler has made very popular in the german historical science. One of those developments is the lack of an enemy after the eastern block broke down. This is not socio-economic? Yes it is: it directly translated into a and spending problem for the military and industrial elites which currently rule the US. And of course the same goes for the european military and defense industry. Luckily a new enemy could be built within the last 20 years: terrorism. Remember - it always takes two to tango. Terrorism is easily created by simply suppressing others to the point where they are helpless and have no other option left. Just what Isreal does in Palestine.
The other big development is the fight for oil. China needs it desperately to sustain its growth and the US can throttle China through access to oil. And here we see the bigger interests behind the war on Lebanon: it is a way to carry war into Syria and Iran - just do some air raids into their territory and wait for the results.
Another long term development is of course the occupation of palestine after WWII. Started as a terrorist operation (at one time Israel wanted to kill Adenauer as has been recently uncovered) it is now calling everybody else terrorists. Three years ago I talked to a jewish priest on a train ride (strangely he was also a catholic priest!). He gave me the Israelian view on ownership and rights in the middle east: TWO THOUSAND YEARS AGO this area was jewish and thats why Isreal owns it now. It is hard to say something against such a raging nonsense. But as with many so called religious people I have met I noticed that below the (religious) surface there is an abolute brutality against non-consenting people.
Given the historical context it always strikes me as strange how easily politicians talk about the "undeniable right of existence for Israel" - is there a natural right for violent occupation somewhere hidden in human rights?
So where does this put us germans in the whole mess? Is it OK to be anti-Israel - given our "special historical relation" as it is usually called by german politicians? It is not only OK it is right. Isreal is an aggressive state that uses torture and brutal military power against civilians. It is NOT interested in self-defense. It has NO interest in peace in the middle east. Peace would also conflict with the US goals in that area.
Being a prof. who talks to students every day the cowardice of german politicians pisses me off extremely. Politicians seem to be low-lifes by nature (just look at the recent Röttger debate: a member of parliament who was also elected head of the german industry lobby and did not want to give back his MP mandate. He saw no conflict between roles here. The funny thing is: there really IS no conflict: all MPs are lobbyists in the german parliament and they don't even have to declare their money sources. He got criticized because his dual role made the way german democracy is constructed so very visible: A people with almost no democratic rights (representative democracy) and an allmighty elite of lobbyists in the parliament. Another jewel of german politics is Reinhard Göhner. Head of the german employer lobby and MP he has never been in a conflict of interests . Sure always on the side of his lobby, never on the side of the people he should represent as a MP.). I just love the way our lobbyists are trying to hide the fact that as members of parliament they are always in a conflict of interests with their lobby: they try to reduce this conflict to the question of "can you do two jobs at the same time? - as in daily hours or travel time..." As if this were the question. The head of the german CDU Kander must really think we are complete idiots. But given all that the way Angela Merkel appeases Bush and the Isrealis sets a new record even for german politics. German Chancellors seem to have a weak spot for dictators and criminals of war: Schröder had Putin as a friend who is famous for his brutality in the Tchechnya conflict.
I guess it is time to talk straight: to call Guantanmo what it is: A KZ (concentration camp) where people are held without any form of human rights being accessible to them. A thing the Nazis would be proud of.
And its time to say that the US are aggressors also against us. Their secret services are conducting their dirty business within the EU just as well as outside. They disrespect our data protection and privacy laws and use economic force to get those data (airlines, SWIFT, Transportation companies). It is time to recognize that what we once heard as so called communist propaganda has been the truth: the US don't give a shit about democracy and human rights outside their border - and if Bush and his crooks can get their way much longer it is questionable what happens inside the US.
And it is time to say that Israel took the land from the palestines illegaly and has been killing the palestinians ever since. Being german does not change historical facts. If more people would say so - and stop doing projects with Isrealian companies e.g. - this might force Isreal into a strategy of piece. Even against the US strategy of war in the middle east.
So what are the good news in this whole mess? I noticed more of my students wearing t-shirts with a clear political statement: the US aggressions against other nations during the last 60 years are listed for example (this is a VERY long list). And the question is raised why acts of brutality against civilians are not called terrorism when conducted by the US. So there is hope yet. And we computer science people might not be so blind with respect to political and social issues as ohters believe.
- A politically correct - distributed - search engine, more
-
In the context of the Lebanon war I had some rather disturbing feelings about the way the war is covered by some media. It is not the generally very tame way every aggression from Isreal is handled by the western media. The media seem to never really explain the context of military actions: That Isreal does everything to prevent peace in this region - it would stop them from acquiring more land. This is pretty much a given: no critical background analysis. But I noticed something strange during the last weeks on the way even the news themselves seem to get filtered: google-news usually does a good job of giving me an overview of the days events. In this case though it does not report a lot on this new war. After a few days media coverage on the Lebanon war was dropped either completely or the news went very much down on the page. This may be coincidance but it made me think about the role of search engines again.
Google, Microsoft and Yahoo are well known for putting money above morals when it comes to business deals with China, offering data to the CIA and so on. Could we build an alternative based strictly on peer-to-peer technologies? The hardware base of large search engines surely is impressive but it is dwarfed by the overall amount of information processing capabilities present across homes. Not to forget the HUGE bandwidth available there if we take all the ADLS, ISDN and modem connections together. Seriously - emule and ohters do a fine job in finding files. What stops us from building a completely distributed search engine?
In one of our software projects Markus Block and Ron Kutschke built the so called e-bay killer: a p2p applications called tradingcenter (find it on jxta homepage) that allowed distributed auctions to be conducted. It included security concepts. Could we build a distributed search engine based on federation and social software? Could the success of wikipedia be repeated in the search area?
- SOA in the INTRANET - an exchange
-
On the occasion of an experience exchange between two large scale enterprises several statements where made that seem to contradict many things which are typically claimed in the context of SOA and Webservices.
Just as a reminder: SOA and Webservices are supposed to
-
allow easy and flexible use of services across enterprises
-
allow different security and transaction systems to operate across company borders
-
reduce complexity by outsorcing
-
allow concentration on core abilities
-
XML everywhere allows for fast and easy interoperability across languages
-
Web Services security allows for federation of trust and easier B2B
-
make re-engineering of processes possible and allows a specification of IT services in BUSINESS Language terms
-
A top down business process modelling approach is well suited to get SOA started.
-
distributed business services are supported by new transaction models (like compensation, long running TAs)
-
and for the pure intranet afficionado: enterprise service bus technology will go way beyond EAI apps with respect to ease of data conversion, reliable transport and change support via pub-sub mechanisms.
The two enterprises had already started using service orientation in their intranets but their experiences where different to what the SOA PR claims:
-
absolute governance is a must: Without elaborated tools and procedures to ensure service compatibility nothing will work together
-
Absolute high-availability required: organisations become absolutely dependent on services being available.
-
Re-use of services increases dependencies and emphasizes the need of high-availability
-
Complexity increases as dependencies grow
-
life-cycle management becomes increasingly hard and costly
-
Webservice use increases only at the border of the enterprise. Their use requires lots of manual tweaking due to incompatibilites etc. in the area of security.
-
Web service security will probably mostly consist of a XML firewall
-
XML data conversions are VERY costly
-
Remoting is VERY costly and SOA design and architecture is DEEPLY influenced by the choice of remote interfaces and locations
-
Workflow and process management require deep organizational changes and there is no business case for it or the organizations are not ready for it.
-
J2EE and .NET interoperability is possible but cumbersome to do.
-
Bottom up component and service definition is quite possible too.
-
Atomic transactions are still the dominant way to ensure data consistency in intranet environments
-
At least two, sometimes three or more versions of a service need to be maintained
and the Enterprise Service Bus:
-
not used yet due to performance issues
-
unclear semantics of data
-
hidden complexity
-
high cost of conversions which need to be avoided by all means
If governance is so critical, how will service design work across companies? Dito for life-cycle issues, complexity etc. How will webservices gain support if they fail exactly where they should shine - at the company border? Remoting and XML processing seem to be intransparent for the architecture - how will it be reflected in SOA analysis and design?
Things we need to learn more about:
proper interface design for SOA services proper ways to do domain decomposition proper ways to communicate interfaces and to achieve a collaborative effect (avoid redundancies) how to align remoting and XML conversion with service decomposition Now for a nice contrast: Mashups - ajax driven aggregation of information at clients, using simple web interfaces like the ones from amazon and google. Why are those aggregations and re-use kind of emergent, self-organized efforts? What makes them different to SOA approaches? Perhaps it is the intranet perspective that makes SOA and webservices look bad because they require different business models. Mashups are pure internet community things - social efforts per se. Using those technologies to the fullest extent would mean to re-create the internet climate within companies: free, collaborative, non-hierarchical ways to interact. Is this going to happen?
-
- Security Madness
-
Another bad day for civil rights and real democracy. The german parliament is discussion new legislation that would give secret services (yes, we have several of them and they are well known for violating civil rights (or attacking prisons with bombs in Celle e.g.). If you follow the ARD Report to the Interview with Hans-Peter Uhl (CSU) you will find this gem of polit-speak: “ Uhl: Das Gesetzespaket, das damals gemacht wurde, hat sich bewährt. tageschau.de: Können Sie Beispiele nennen, in welchen Punkten sich die Gesetze bewährt haben? Uhl: Die überwachung der terrorismusverdächtigen Szene hat konkrete Anhaltspunkte über Gefährdungslagen gebracht. Die haben dazu geführt, dass die Sicherheitsorgane tätig werden und Festnahmen durchgeführt werden konnten. Möglicherweise konnten auch Vorbereitungshandlungen für mögliche Anschläge, sei es im Inland oder Ausland, unterbunden oder gestört werden. tageschau.de: Können Sie ein konkretes Beispiel nennen? Uhl: Mir ist kein Fall bekannt.(sic!!!!, WK) Aber ich kann nicht ausschließen, dass es Fälle geben hat, wo Anschläge oder deren Planung aufgrund von Verfasssungsschutz-Informationen verhindert worden sind. tageschau.de: Warum sollen die Befugnisse der Dienste ausgeweitet werden? Uhl: Diese Maßnahmen sind gerechtfertigt und unablässlich. Ein feiger, terroristischer Bombenanschlag lässt sich in einer mobilen Gesellschaft, wie wir sie vor allem in Großstädten leben, nicht mit letztendlicher Sicherheit (sic !!!!, WK) verhindern. Das bedeutet, es gibt nur eine Chance: Man muss während der Vorbereitung der Handlung den Tätern mit nachrichtendienstlichen Mitteln zuvorkommen (sic !!!! WK). Wenn der Täter mit der Bombe unterwegs ist, dann ist es in aller Regel zu spät.”
So he has not a single example of where the snooping-laws (from 2001) really helped but he wants more of them. And the rationale is quite simple: because terrorism is hard to prevent the security forces need to be pro-active and start snooping even earlier.-
Ok. So murder is also hard to prevent - every day people get killed. This did not lead us to monitor children, to do DNA analysis on innocent youth or to track anybody in this society without cause. I believe the murder argument shows the bureaucratic madness of the terrorism argument.
But the bad day is not finished yet. Have you heard about the Karlsruhe conference on security research - with a keynote by Anette Schavan, former secretary of schools in BW and now responsible for research in Berlin. The conference deals with technical means to detect bombs, explosives etc. Take a look at the toys of those researchers here: Future Security - Program. It is depressing to see that security is only seen as a technical problem. Every political dimension has been removed from the discussion.
The szenarios presented at the conference are quite interesting:
loss of energy infrastructure panic between people of different cultures at one place !?!? loss of internet functionality Bruche Schneiers recent competition for the craziest terror scenario comes to mind....
- SOA in your Enterprise - by IBM Global Business Services. A seminar here at HDM, 10. November 2006
-
 Everybody in IT is currently doing something with SOA. Either analyzing, implementing or running it.
Everybody in IT is currently doing something with SOA. Either analyzing, implementing or running it.
What makes SOA so interesting for enterprises and why just now? What are the challenges with SOA that companies have to solve? How is a SOA strategy successfully implemented? Examples for successful implementations? What are the core technologies behind SOA? Consultants from IBM Global Business Services have created the following agenda. Their goal is to present the core topics on SOA and to answer the above questions. Agenda:
-
What make's SOA special - the business view
-
SOA technical architecture
-
Security in a SOA environment
-
SOA Governance
-
SOMA - the methodology for SOA development
The presentations are ideal for people who need to make decisions on SOA in the near future of their enterprise. You will find more details for this upcoming event shortly here and at the homepage of HDM Stuttgart If we should send you more information or in case you would like to register early you will find a link here shortly.
The event is free of charge but an early registration will secure your place.
-
- Games Day: We have gained a level
-
Not being a games developer the day was quite educational for me. Here is some of the things I learned today:
There is no recognized theory on the effects of games on children and adults. As always in social effects it depends on the circumstances and environmental forces as well. A one-dimensional explanation misses many things like the development and practice of socail skills in multi-player games. On the other side the results e.g. from Christian Pfeiffer on the effects of early media exposure on the success at school warrant a careful dealing wiht media at the side of parents. There is lots to cover in future versions of the Game Day and we should keep the focus on technical AND social aspects fo games. The presentation by Prof. Susanne Krueger met a public that picked up quickly on those controversial topics and before we realized it we had already managed to be one hour behind our schedule...
As far as addiction is concerned games seem to cause the same problems as everything else: humans simply seem to be addicted entities anyway - just the drug varies and your craze may not be mine (;-). Some gamers reported problems that friends had to manage a responsible way to deal with games - especially multi-player games with their potential for group pressure. But the same goes for online casinos, phone sex etc. I guess.
Michel Wiekenberg started the technical session with an introduction to modelling with meshes and textures much to the benefit of the not so game-savvy public. Then Valentin Schwind took over and my - is game modeling complex and difficult. He used 3dsmax to demonstrate the various effects and endless ways to configure and model assets and it became clear how difficult this program already is. For professional development plug-ins are created to provide game specific services and to maintain a clear modeller-programmer boundary while putting as much as possible into modelling.
Valentin Schwind shocked the public when he told us the time it takes for newcomers to get familiar with advanced modelling using 3dsmax. But there are also many features in this program that use symmetry e.g. to reduce modelling effort.
Andrea Taras should us ways to map textures to wire models and to do this in a pleasing way. It is clearly more than just techniques. To achieve pleasing artistic results one should have real drawing experience and she suggested a course by our colleage Susanne Mayer where she is currently learning how to draw. The good news was that texture mapping is not always so difficult and even beginners can achieve nice results soon.
After her talk my Colleage Jens Hahn - our graphics, interactive media and virtual reality specialist gave a talk on current developments in graphics rendering. He showed advanced shading techniques (not to be confused with simply crating shadows (;-)) using programmable graphics hardware based pixel rendering and fragment processing (applying the textures information). According to him the fact that those processing steps have become programmable hardware modules is responsible for realistic rendering in realtime.
From a software architecture point of view I enjoyed to see the graphics rendering pipeline as a nice representative of data flow architecture and communicating sequential processes (CSP) - one of my conceptual topics this term. This type of architecture scales extremely well in the context of huge amounts of data and keeps the processing algorithms smples (no locking etc.). Jens shoed Nvidias C for gaphics as a language used to program the hardware modules.
Then came the second of the Wiekenberg double pack: Markus Wiekenberg demonstrated in a much acclaimed talk the development and use of a dialog editor for a playstation 2 game. At least for non-gamers like myself it became obvious how games really are created and what a huge role the correct use and even develpment of tools plays in this area. The dialog editor helped game creators to create realistic dialogs by letting them change camera positions easily. The editor helps accessing and composing the endless amounts of asset data kept in databases and even tries to support different language versions (yes, it is difficult to map different languages to the same scene lenght). It was amazing how the combination of pre-configured animations and configurable effects like laughing, getting drunk etc. were able to create quite realistic dialogs.
Markus Wiekenberg had developed this editor and did not cease to emphasize the importance of usability in this project: only when the UI meets the expectations, knowledge level and working style of those designers will the increase in productivity be realized.
The software related talks where continued by Christoph Birkhold who reported experiences from this latest game development: desperados 2. He showed many scenes and explained the technology used to create them - ranging from the core architecture to the inclusion of a physics engine. He explained that whoever wants to integrte such an engine to increase the realism of scenes should do so as early as possible in a project. The reason is that there are many conflicts between physics and game logics and it can happten that the decisions of the game physics engine threatens the playability of the game: What happens if physics decides to put a wreck doll at a place where games logic says no?
After these two talks from professional game programmers two MI students: Thomas Fuchsmann and Stefan Radicke - they run our own games tutorial at CS&M - told about their own game projects and showed several scenes. It started with their 3rd term project "FinalStarfighterDeluxe" (their little starship became the logo of our game day). And it ended with their current project: the development of a 3D game engine. Since they started development from scratch they are in an ideal position to teach game programming in their tutorial.
Last but not least Kerstin Antolovic and Holger Schmidt from Electronic Media at HDM presented their mobile game. Programmed in Java on J2ME they told us about the problems with incompatible implementations of Java on various mobile phones and the difficulties of bluetooth programming. Their game had to deal with minimal computing and storage resources and still included several different modes ranging from timed attacks to multi-player environments. Despite of the difficulties the possibilities behind mobile games are ming-boggling: image some 80.000 people in a stadium all equipped with bluetooth phones...
This excellent development project also showed that more mixed teams consisting of electronic media and computer science students are needed.
The Games Day ended with a short discussion of future versions of this events. The whish list included e.g. specialized tutorials for and by industry experts, programming competitions, multi-day conferences etc. We will conduct a Games Day wrap-up soon where we will discuss the results and start planning the next one. In the meantime we should also intensify our relations to our partner university at Dundee, Scotland. They seem to specialize in games and multi-media devellopment.
Looking at the large number of participants the Game Day obvioulsy was a success. But did we gain a level at CS&M? I think so. The Games Day technical presentations came from our own students, alumni and their friends to a large degree. It shows a high levele of technical competence and an excellent motivation to turn games development into a permanent topic in our faculty.
- First HDM Games Day - Program
-
 This is the agenda for our first day on games (computer, consoles, mobile) and games development. One of our goals is to introduce students to the world of games creation. Another goal is to bring us in touch with specialists working in the game industry and start a discussion on the future of game development at HDM. We hope that the Games Day will serve as a kick-off for future events which might even spread over several days.
This is the agenda for our first day on games (computer, consoles, mobile) and games development. One of our goals is to introduce students to the world of games creation. Another goal is to bring us in touch with specialists working in the game industry and start a discussion on the future of game development at HDM. We hope that the Games Day will serve as a kick-off for future events which might even spread over several days. Electronic games have grown into a substantial industry making millions with online games, strategy games and adventures. But there is more to games than just economics. Today those games - especially the online and multiplayer variants - are having social impacts as well: From getting lost in cyber space to meeting lots of people and making friends online. This means that many different faculties at HDM have a common interest in computer games: design and arts, the economics behind game production, PR and markteting as well as information ethics and last but not least the architecture and desing of games as complex programs. The Games Day leaves room for discussions on the future of game development as well.
The First HDM Games Day provides an introduction to the world of game design and programming. Demos of games will give an impression of the current state of the art in computer games (or as the Gamestar magazine recently said: "You have gained a level"). The day is free and open to the interested public both from within HDM as well as from the industry. It will take place Friday 16.06.2006 at Hochschule der Medien, Stuttgart, Nobelstrasse 10. (see HDM homepage for streaming infos and last minute changes . We start at 9.00 in room 056.
- 9.00 - 9.30 "Böse Games?"
-
Susanne Krüger, Timo Strohmaier, Walter Kriha, HDM - open discussion
- 9.35 - 10.20 Game Modeling
-
Valentin Schwind, Michael Wiekenberg
- 10.25 - 10.55 Textures in Gaming
-
Andread Taras
- 11.30 - 12.00 Shading Techniques for Computer Games
-
Jens Hahn
- 12.05 - 12.45 Tool Pipline,
-
Markus Wiekenberg
- 11.30 - 12.00 Shading Techniques for Computer Games
-
Jens Hahn
- 12.45 - 13.30 Lunch Break
- 13.30 - 14.45 Framework Architecture and Game Physics with Demos
-
Christoph Birkhold
- 14.45 - 15.15 Discussion Round 1
-
All
- 15.15 - 15.45 Coffee Break and Demos
- 15.45 - 16.30 Games Programming Basics with Demos
- 16.35 - 17.05 Mobile Games
-
Representatives from Electronic Media (AM)
- 17.05 - Get Together
This is the list of topics we would like to see discussed at our second games day in the winter term:
Cell Process Architecture for Games IBM Lab Böblingen Audio in Games Amsterdam Game Engine Performance Problems in Games MMOGs and P2P Usability and Eye tracking in games development Security (DRM etc.) Game Economics It is quite possible that the next Game Day Event spreads over a couple of days. For a nice introduction to online games see the new IBM Systems Journal:

- The pipeline architecture in computer linguistics
-
 In his introduction to computer linguistics today Stefan Klatt mentioned the pipeline as being the current architecture of choice for extracting information from documents. The pipeline allows modules to sequentially work on text fragments and extract information from those parts, e.g. break up the text into words (tagging) or enrich the raw text with meta-data like when sentences form a more complex argument.
Those modules can be rule-based or statistcal in nature with a combination delivering the best results with respect to recall and precision. The modules can use thesauri or other forms of lexica as well.
In his introduction to computer linguistics today Stefan Klatt mentioned the pipeline as being the current architecture of choice for extracting information from documents. The pipeline allows modules to sequentially work on text fragments and extract information from those parts, e.g. break up the text into words (tagging) or enrich the raw text with meta-data like when sentences form a more complex argument.
Those modules can be rule-based or statistcal in nature with a combination delivering the best results with respect to recall and precision. The modules can use thesauri or other forms of lexica as well.The art in building pipeline architectures lies in defining the shared data structure those modules work on. This structure must be extensible by each module as nobody can know which analytical processes will be available in the future. At the same time the modules must be and stay independent of each other. This means that an addition to the shared or common data structure cannot render existing modules incompatible. A high degree of self-description and meta-meta layers is probably required. At this point the Unstructured Information Management Architecture (UIMA) from IBM comes to mind. It can be downloaded from alphaworks and a very good IBM Systems Journal on the topic of unstructured information processing exists as well. It describes the framework and pipeline interfaces that IBM defined to connect modules. It also describes the Prolog data structure used to capture shared information. Due to this data structure and the processing pipeline working on it later modules can use the original textual input AND all the intermediate results of previous modules. This is a major advantage as it relieves the programmer of a module from the tedious work of getting input etc. And it also gives high quality results to later modules. On top of it the whole process is sequential and does not require error prone locking and synchronization primitives. But is it the best we can do? Just think about our brain seems to process language on the different levels of phonetics, lexicon, syntax, semantics and pragmatics. It looks like in our brain the different layers can somehow share information IN PARALLEL. Partial semantic results can help the word tokenizer to perform better. From a layered architecture point of view the mixture and cross-fertilization of layers is not desirable as it tends to create tight couplings between layers. Each layer should only depend on its lower neighbour. But from a processing point of view each layer should be able to use partial results from other processing steps as early as possible to improve its own results. How could an architecture look like if we want to achieve parallel sharing of partial information without ending in a nightmare of tight couplings or synchronization problems? How about creating a distributed blackboard (aka linda tupla space) to represent the common data structures? An example might help: you know perhaps the experiments done with texts lines cut in half horizontally? The human brain seems to be able to still read those words even at a lower recognition rate. A word tagger might have some problems to detect the proper words from OCR input. But syntactical and semantical analysis modules could provide early hints once the first parts of a sentence have been guessed by the tagger. It is my guess that some kind of cross-fertilization between processing modules is what makes the brain so powerful in the area of NLP.
Besides the processing architecture the talk by Stefan Klatt provided a very good introduction to the concepts behind computer linguistics and the methodologies used there. It is a fascinating area which combines computer science, linguistics, mathematics, philosophy and psychology to be successfull.
- Web Analytics, RFIDs and J2EE Adapters - free IBM Redbooks
-
Just a reminder: you can get free and good information from IBM Redbooks . The introductory chapters are usually not specific to IBM products and give a good overview on the topic. Here some examples. The web analysis book looks especially nice.
How to use Web Analytics for Improving Web Applications WebSphere Adapter Development IBM WebSphere RFID Handbook: A Solution Guide - Current Thesis Work at Computer Science and Media
-
After our perfect rating in Zeit/CHE - computer science and media at HDM turned out to be one of the four best technical (;-) computer science faculties - it is time to present some of the latest thesis work done at the computer science and media faculty of HDM.
The last two thesis papers show clearly the wide range of interests that our students in computer science and media have.
- Desktop Search Engines for the Enterprise
-
Dani Haag did a research oriented thesis at UBS AG. The task was to define criteria for the use of a desktop search engine on an enterprise scale. After a theoretical part where he investigated human search behavior and strategies he covered the topic of desktop search in depth. The results where quite intersting.
Desktop search is radically different from internet search: It deals with information that a user typically has already seen once and that she wants to find again quickly using criteria like the tool used to create it, creation time etc. Desktop search needs to serve different user groups and intentions ranging from specialist looking for a very specific piece of research documentation to secretaries trying to locate a memo. Desktop search can save a lot of time. Just imagine 30 minutes of search time per person per day in a company Desktop search needs to be federated in an enterprise environment: other search indexes need to be used. This is especially true for network drives. An update of a public piece of information on a shared global network drive would result in thousands of local search engines updating their indices. And this would simply kill the company network for three days given a large enterpise. Desktop search needs to be extensible with respect to new formats. And last but not least desktop search is also a security problem. Google e.g. hooks the windows API and gets access to e-banking information etc. Google reads this information before it enters an SSL channel. Caches are also not safe from desktop search engines and users need to be very careful to avoid confidential information from showing up in indices. But the most important feature of a good desktop search engine clearly is good usability. Here the products from Microsoft and Google seem to have an advantage over smaller companies that may be in this business for a longer time but failed to develop easy to use interfaces. All in all there is little doubt that the future of local machines will include a desktop search engine as the amount of data per person is still increasing. This includes mail, internet and application data.
- Central User Repository and Business Process Re-engineering
-
How expensive can it be to introduce a new employee to a company? The answer depends on the structure of the company (distributed vs. centralized), the applications and the infrastructure provided. Marco Zugelder thesis covered the creation of a centralized user repository, together with the business process analysis needed to improve the process of hiring new employees. The result was the design of an LDAP database with interfaces to different kinds of application and a strategy of how to incrementally move towards this centralized repository.
During his business process re-engineering work he studied existing processes at one of the largest computer hardware suppliers for businesses in Europe. He used the BPMN notation to descrive the processes found. But he also quickly realized the the organization of change would be a major issue during the business process analysis. The investigation of current practices and processes raised some questions and suspicions with the employees which could seriously impact the project. Markus Samarajiwa's talk at the last IBM University day came in quite handy here: How to deal with organizational change problems.
- Autoconfiguration of home networks with semantic protocol definition
-
The home of the future will not be configured by its users - at least not completely. The complexity of updates to various devices is just too high to be handled by the end-user. This means that application service provides will have to do the maintenance work, e.g. updating the software on dish-washers and heaters. Unfortunately most devices have different configuration values and protocols. This was the starting point for Ron Kutschke at Alcatel. His task was to find a solution to this problem and following ideas from out long term partner Dr. Stefan Rupp at Alcatel he decided to use a semantic approach: He designed an ontology for the definition and description of a generic configuration protocol based on OWL-S. In a second step this generic protocol was then mapped to specific configuration structures and transport protocols.

This interesting work which resulted in a running prototype has been put in the public domain and can be downloaded here: Thesis Presentation Appendix (technical) Software (source). Let me know if you have problems accessing the software or thesis. To me the thesis is another proof for the increasing importance of semantic technologies in service oriented architectures and we have currently a number of thesis work at HDM in this area.
- On the Effects of Web Banners on Reception and Behavior
-
Sanela Delac did her thesis work with our usability specialist Prof. Michael Burmester. Using an empirical approach she investigated the effects of banners on reception. Different theories existed on this topic, ranging from users don't even recognize those banners anymore to them still having a measurable effect on browsing behavior. She used the eye-tracking equipment of the usability lab to get hard data on reception and - together with a questionaire - did a statistical analysis. It turned out that the effects of banners heavily dependen on the browsing mode of the users. A user with a strong focus on something rarely recognized the banners. Users who just wanted to do some browsing without specific goals were much more influenced by banners
Besides the statistical and computer science parts Sanela also had to get familiar with the psychological basics of reception, alarm signals and peripheral detection of input. The thesis worked out nicely and confirms once more that our students in computer science and media are able to work in very different fields just as well - combining their technical know-how with other sciences.
- Electronic Waste - Heaven Sent?
-
Matthias Feilhauer did a very nice thesis on the way industrialized societies currently deal with electronic waste: by exporting it into the so called third world. He was able to show that this export is very much a mixed blessing. On on side those countries get money and raw materials at a cheap rate. On the other hand they suffer great environmental damage during this process.
Thanks to our friend Prof. Rafael Capurro he was able to get in touch with specialists from GLOBAL 2000. The thesis finally was written in Vienna.
What caught my attention in the thesis was the term "throw-away hardware". Apple Ipods and mp3 players in general are just one kind of hardware that will never get repaid. It will be exchanged and thrown away. There are tons and tons of old or broken mobile phones and players waiting to be recycled in the third world.
Surprisingly little data exist on the quality of the recycling processes there.
- Computer Games Workshop at CS&M
-
16.06.2006 will see the first workshop on computer games technology at the computer science and media department of HDM. We will discuss all kinds of computer games, including massively multiplayer online games. Talks on the following topics are planned:
Game Story Patterns Tools in Game Development Excerpts from a Games Tutorial Practical Demos Game Development Theoretical Foundations The Social Side of Computer Games  Screenshot from World of Warcraft game, found at a site dedicated to this game
Gamers and people interested in learning more about computer games are welcome to join in.
Screenshot from World of Warcraft game, found at a site dedicated to this game
Gamers and people interested in learning more about computer games are welcome to join in.Note
The workshop will be held on 16.06.2006 at the computer science department of Hochschule der Medien, Stuttgart. Time and location will be given later.
By a happy coincidence: The current IBM Systems Journal features Online Games and has lots of interesting articles: protecting content, cell programming, server systems for MMOGs, marketing and financial aspects of online games and so on. And Thomas Fuchsmann found the following paper on event distribution and isolation mechanisms in large online games (ways to load-balance so called flash crowds in online worlds) Adaptive Middleware for Distributed Multiplayer Games
- Software Engineering on Mainframes - Workshop at HDM
-
This is our first workshop on mainframe technologies. Last year we have made a first step in this direction when we had Karl Klink at HDM. The former head of VSE operating system development at IBM Böblingen held a very interesting talk on linux and open source development strategies - with a lot of surprising results regarding quality and social issues. The success of this event made us think about putting a larger focus on mainframe technologies in general at the computer science and media department here at HDM.
The next step was to organize a larger workshop dedicated to mainframe topics. Organized by Karl Klink the workshop will include three talks:
Market Management, Theory and Practical Issues by Dr. Klaus Goebel Software Development and Engineering Process by Karl Klink Virtualization by Christian Bornträger Out goal is to offer a complete course on mainframe technologies in the coming winter term, possibly run by Karl Klink and Dr. Klaus Goebel. We consider the technology behind mainframes as very exciting. E.g. virtualization has been a hot topic on mainframes since many decades and seems to become mainstream only now. The development of mission critical software with a high degree of availability and reliability will be THE core problem of future operating system development (look at the article on the Tanenbaum/Torvalds debate here)
But also the job opportunities for our students are simply excellent in this area.
- Living in a process world?
-
IT is transforming the way we live both on the macro level of society as well as the micro level of companies and how we work as part of them. I have articulated my fears of a totally controlled society already several times. It seems a lot of surveillance and data capture is done simply because IT nowadays provides the means to do so even on the largest scale - as the latest case from the former "land of the free" shows where ALL telephone calls where captured in the words largest database. Without due process, concrete suspicions or respect for human rights.
Inside companies it is not so much different. Under the pressure of costs and globalization companies investigate their processes intensely. Additional pressure comes from regulations and governance (Basle II, Sarbanes-Oxley). Especially large companies seem to spend incredible amounts of money on defining ever newer, larger and more complicated chains of processes. What does this to employees and their motivation and morale?
You need something done quickly? Or beware - you've gotten creative over the weekend? The right answer is: is there a process for this? (That has become the killer argument against all new ideas anyway - the mere thought on establishing another process keeps ideas from becoming reality...)
If you pass the no process stage the next roadblock is another buzzword of the neo-liberal ideology: Have you got an SLA? SLA is for Service-Level-Agreement and it means when you want some coffee you need a written and signed contract with a coffee providing service entity within your company - perhaps an outsourced service. Nothing moves without SLA and all IT activities are strictly driven by business requirements. Ever seen a business requirement for software re-architecting? Software updates? Infrastructure needs? Wont't happen because those are no business requirements at all.
Many IT departments forget that in a world made of SLAs they need to calculate their project costs in a way that includes ALL future maintenance costs - or they won't get the money for them.
Shared services - things that many departments in a company would profit from - are typically infrastructure tasks and thus not sponsored by business directly. Often the first application project that needs such an infrastructure is burdened not only with paying for it but also for BUILDING it. We see application developers dealing with security stuff like single-sign-on etc. with quite interesting results...
Workflow may be discredited as a term (choreography or orchestration sounds so much nicer). Fact is that workflow applications are more and more directing the way we do work within companies. They control what and when we do things and make us completely transparent by recording and analyzing all this.
Do we really need to regulate and capture EVERYTHING that happens in a company? Can't we rely on some form of spontaneous activities? Has anybody thought about the COST of capturing and defining all data needed to drive a process centered company? Don't we see progress to slow down to a crawl the more rigid the internal processes get? There is a limit to the positive effects of standardizing and controlling things. The PC in a large corporation is NO "personal computer". it is completely under the control of the corporation with respect to what you can do with it. Makes sense when you think about viruses and trojans. But what if you want to try something? How big of an effort is needed to get an exception? But again: Because we can....
So what is live in such a process driven world? It means for a middle-manager to be completely consummated by meetings all day long. The evening is usually wasted reading and answering mail. There is little time left for creativity. Informal relations are about to be replaced completely by SLA driven relations. Fast, unconventionel, motivation-driven actions - typical for software development - just do no longer fit into those organizations. It is no wonder that large multi-nationals e.g. in automotive, have reached an extremely high degree of outsourcing: all creative work is done by externals because the internals are usually completely absorbed by their process tasks.
The "cult of the dead process" follows the well known anti-patterns of science which I discussed below: pick one factor from a complex system and religiously stick to it against all reason. This is "process" here. Forget about everything else. That's the employees in this case...
Sorry for this rather pessimistic view on the process world but I had the feeling that we are applying IT mechanisms without thinking about the consequences for the way we work and want to work.
- The micokernal debate revisited - Torvalds vs. Tanenbaum goes into the second round
-
 I have completely re-arranged my lecture on host based security and trusted computing bases. I've added kernel security - essentially Tanenbaum's arguments on why the micro kernal is better with respect to security and reliability. Having a large lump of code all running in priviliged mode is ample ambient authority waiting to be abused by device drivers and root kits. The link to the Tanenbaum article.
I have completely re-arranged my lecture on host based security and trusted computing bases. I've added kernel security - essentially Tanenbaum's arguments on why the micro kernal is better with respect to security and reliability. Having a large lump of code all running in priviliged mode is ample ambient authority waiting to be abused by device drivers and root kits. The link to the Tanenbaum article.It is getting much clearer what host based security really means even though lots of sections are incomplete.
I really think Schneier and Tanenbaum have it right when they postulate an increasing importance of host-based security for the near future. This includes interestingly also advanced usability issues like securing a trusted path for users to critical system resources or the use of powerbox architectures for fine-grained delegation of authority to applications. This is e.g. done in work by Combex
Isolation is becoming a key concept again. It looks like the pendulum swings back to more process based parallelism instead of fine grained shared state parallelism through threads. The research-OS Singularity by Microsoft seems to separate plug-ins from the host application through processes. The plug-in and host can only communicate via interprocess communication. This decreases the chance for a plug-in to take over the host application considerably. And for simpler distributed systems design based on communicating sequential processes (here complete Java VMs) look at Jonas Boner, Distributed Computing Made Easy (link from theserverside.com)
- 3rd IBM University Day at HDM
-
 on 2. June 2006 we are going to see the third IBM University Day at HDM. Senior consultants and architects from IBM Global Business Services will present current topics from different IT areas. And as every term the presentations will cover a mixture of technical and organizational fields - this time with a focus more on "soft skills" like strategic consulting, work in international teams and how to be an architect in large software projects.
Dieter Falk will introduce us to the problems of running a data center efficiently. This includes architectural questions like how to design an application properly for running it in the context of a data center. Infrastructure, standards, performance all play a major role here.
on 2. June 2006 we are going to see the third IBM University Day at HDM. Senior consultants and architects from IBM Global Business Services will present current topics from different IT areas. And as every term the presentations will cover a mixture of technical and organizational fields - this time with a focus more on "soft skills" like strategic consulting, work in international teams and how to be an architect in large software projects.
Dieter Falk will introduce us to the problems of running a data center efficiently. This includes architectural questions like how to design an application properly for running it in the context of a data center. Infrastructure, standards, performance all play a major role here.What is strategy consulting? Today even core tasks of businesses like the development of visions and strategic directions are outsourced or conducted with the help of external partners. Sabine Sure will show us what competences are needed in this highly critical field and what methods are used to do strategy consulting.
Like Dieter Falk, Markus Samarajiwa has already been once at HDM where he presented the art and science of organizational change management: how to introduce change at companies in a way that does not lead to major conflicts inside the company. He demonstrated that really managing the change as a separate project makes sense and pays off quickly. A short time after his first talk I have seen concepts of managing organizational change pop up in thesis work. E.g. during the analysis of core business workflows. Companies are currently putting a lot of work into the analysis and definition of service architectures and workflows I predict that the management of changes caused by this will have an important influence on a successful move to SOA principles.
This time Markus Samarajiwa will show us how to work in international projects. Different views on core concepts between cultures exist and threaten common projects. But methods like the scenario method help to overcome the problems.
Last but not lest Bernard Clark, senior consultant at IBM GBS and our liaison to IBM, will discuss the ever more important role of an software architect. Based on real examples from J2EE projects he will demonstrate the skills and techniques that are essential for the role of a software architect.
Note
The IBM University Day will be held 02. June 2006 at http://www.hdm-stuttgart.deHochschule der Medien, Stuttgart, Nobelstrasse 10. It is open to the interested public. Room 056, Start: 9.15
- SOA and Business Process Modeling - possible victims and antipatterns
-
Companies are getting on the service oriented bandwagon quickly. Services need a concept of business processes to drive them and finally we seem to get closer to an understanding of business: business does not think in objects - instead business does think in processes and services. Finally, we do understand what business needs and how IT works.
If you need to stock up on some of the latest process terminology, the current IBM Systems Journal on XML has a nice article by Frank Leymann et.al. Business processes for Web Services: Principles and applications on BPEL etc.
For the seasoned developer a deja-vu quickly establishes itself: didn't I hear those promises already years ago? And why should I believe them this time?
Do you remember the terrible workshops with business people to create an OO based architecture for some new application? the business people must hate us forever for putting them through those exercises. Why didn't we see much earlier that business does not think in objects (storage containers for data)? Why did we miss the concepts of activities and processes completely?
On a sideline: This is the right point to deal with a new myth: the new process/service paradigm is non-OO. This is nonsense of course. Activities ARE procedural, but they need not be expressed and handled that way. The procedures and activities need to be reified with objects and work nicely so. Do not confuse concepts from reality with implementation concepts.
How successful will the above technologies be? Did you ever read "the right stuff" by Tom Wolfe? The US Air Force killed hundreds of young pilots with their various F16...prototypes and research projects. And the pilots always claimed that it was human error that led to those deaths. Lying to ourself seems to be a very common feature and software people are prone to do it too.
Do you believe in learning from past mistakes? If yes then you are very untypical for IT. We usually don't. But lets just for the fun of it try to gather some of the nonsense we have proclaimed over the past 15 years. And forgive me if I start with object orientation as this was the first time I got really bitten by a new technology and their evangelists - Youdon and Coad in this case. Before I was safely rooted in the Unix system philosophy and the C language and projects usually were quite successful and the methodology used at Siemens Unix labs was quite agile and developer focused.
We will not forget how foolish business theories are. We will just deal with them later.
- Object Orientation
-
the victims of the first years of OO were countless: slow, completely inflexible applications appeared. Experimental programming and rapid development disappeared behind huge hierarchies and endless discussions on category systems and the "right" hierarchies was hurting development groups. We were unable to create flexible toolkits based on OO first - until we finally figured out what frameworks are made for. I discussed the problems in my paper on framework development. My biggest mistake at that time was to believe in the things Yourdon and Coad said about OO development. And that I did not realize that what they described was application development, not flexible toolkit development. It was the first time that I started a large development without having real experience with the technology behind it (in this case OO) and I paid a high price: The resulting software was absolutely inflexible and not maintainable at all. After a very thorough failure analysis I figured that what we needed was a framework architecture and I started learning from the emerging framework research and development (fresco, taligent). Our development group discovered the huge problems behind C++ (unclear and complicated semantics, binary dependencies and last but not least a horrible implementation of generic types called templates. This last feature had cost the Taligent group HUNDREDS of MAN MONTH as I learned later. Luckily our use of CORBA technologies prevented most of its use. Finally we had to learn to separate OO concepts from implementation - something that got even more clear when I moved into enterprise beans technology later on: here we had to dissemble objects into their different runtime, security, persistence and other aspects and represent them outside of those objects. (Ever tried to use inheritance in good old EJB versions?)
The mistakes resulted in a positive but critical attitude towards OO and that in turn proved to be quite healthy. Because next came the above mentioned approaches to cruedely map business concepts into machine or implementation objects. It missed the process aspects of business completely but that was only one mistake. the other mistake was the assumption that business objects would have to show up as implementation objects at all. Just take a look at an older EJB class diagramm: the business logic finally is contained in a class that has no inheritance or type relation with the associated business concpet at all. that is the implementation side. But the third an biggest mistake was the concept of a "business object" itself.
- Business Objects
-
many of the big and famous have tried to tackle this concept (Oliver Sims, D'Souza, OMG and others). All turned out to be nonsense: Business Objects were overloaded with behavior that immediately created problems as soon as the associated use (workflow changed). What was good behavior in one workflow or use turned out to prevent the re-use of those business objects in other cases. Quickly the business objects turned into enterprise objects with largely a storage characteristic and little business behavior built in. Business behavior then was delegated to facades, delegates and other higher level objects. I still remember endless discussions on whether there are only business objects or also data objects (containers of enterprise data with little or no behavior. Nowadays those have become standard and are called Data transfer objects or value objects. Those design patterns or best practices were absolutely neccessary and even today every experienced J2EE developer knows that violating those concepts will kill an application quickly.
- Distributed objects
-
The OO concepts - together with the meager experience available yet - was quickly ported to the distributed systems world to create havoc there as well. All things distributed (latency, failures etc.) where replaced with the transparency dogma: objects separate interface from implementation and can hide the fact of distribution behind the interface. We did not realize that interface vs. implementation was a DEVELEOPMENT issue, not a RUNTIME issue. This resulted in extremely slow systems which on top of this were also tightly connected and therefore unmaintainable. Not to forget that there was no versioning concept for those distributed objects as well. Finally it became clear that the small granularity of local OO programs was a killer for network performance and that the OO approach placed an additional burden on servers because of the need to keep references. In many distributed systems it is NOT CLEVER AT ALL to distribute references because references are promises that you need to keep. Much implementation technology circles around how a server can still scale while maintaining references for clients (activation, automatic storage etc.). After granularity was finally seen as a problem the concept of components showed up.
- Components
-
Most programming languages have no concept of a component. An Enterprise Java Bean is called a component because "class" simply does not work: An EJB is NOT a class. it is a combination of objects, XML descriptors etc. But what IS a component conceptually? I learned that it is quite possible to have a huge development team working with a huge budget in the hundreds of millions on a component based project - without having one person in the whole project who would be able to explain what a component is or should be. Yes, those were the golden times of IT....
Today components are mostly understood as being a) a development time artifact and b) having a coarse grained interface with all internal complications hidden from clients. Sounds good as long as you don't look inside of a component. Because then you will notice that encapsulation and coarse grainded interfaces create a nice problem regarding re-use: A completely independent component could not use other components without creating development time and perhaps runtime dependencies. So it is quite reasonable to require for every component to explicitely tell about internal dependencies up front. UML supports this now with a nice graphical notation. But wasn't there once a dogma about hiding all things implementation? Turned out to be ok during development but was never true at runtime where system managment needs to know about dependencies. Looks like there are more parties going on, not just development.
Even with more coarse grained interfaces we need to watch for runtime problems like latency between components.
- XML vs. Code
-
Parallel to (distributed) objects and components XML became an important artifact in software projects. When I did framework development in C++ it became quickly apparent that changing C++ code was a nightmare with respect to recompilation. And customization was also very hard becaues it required new classes etc. Creating flexiblity and achieving customization of software using inheritance and new classes is like making people survive environmental pressure (catastrophes) through mutation: a lengthy and unfortunately mostly deadly process for the ones involved. Humanes most impressing ability is not mutation but dynamic adaptation to changing environments like living a 5500 meters above sea level or directly at sea level.
But adaptation in languages like C++ turned out to be cumbersome and hard: static typing does not help here at all and in my point of view is one of the biggest myths that exist in IT. EVERY project that I know which needed to be flexible had to introduce dynamic features which are based mostly on strings (classByName etc.) There goes the type safety and we are back to good old runtime detection of type errors.
But instead of questioning those languages - as I do today - I went down the path of introducing XML into software development. In 1994 I was heading a framework group for document processing and workflow and we used SGML heavily to keep configuration of hardware, documents and workflow outside of the source code.
I was proud and not realizing what kind of huge problem this would create later on. Today we have tons of projects that use XML to describe everything that needs to be customizable: environments, databases and business behavior. These XML files create maintenance nightmares and there is no single compiler or environment that could track dependencies between code and XML environment. Code libraries to work with XML like JaxB are simple crap (no meta-data). XML definitions are a foreign element and have never become something natural in code. Compare this with Lisp lists: those lists represent the AST (abstract syntax tree) directly. A beautiful concept but the syntax sucks. I Believe we got the same problem with XML: it needs to become a natural part of the language. Unfortunately the microsoft project to achieve this seems to have died. The question is: can we do better than Lisp? What is missing in our languages today? Do we need better environments with more tooling, generators, XML etc. or do we need more powerful programming languages (capturing semantics, logic etc.)?
If you think that those questions are a sure sign of overexposure to theoretical computer science I recommend watching the deployment of J2EE components across various stages of testing (machines and application integration, production tests) and the associated handling of XML...
Will anotations be different? The only advantage of annotations are that they are kept together with the code. They don't solve the the real problem that code seems to be not flexible enough to deal with different environments. Annotations are still a foreign concept because the things annotations express are not really represented in our current programming languages. The semantics are missing.
- Web Services and SOA
-
Can somebody please explain the differences between a web service and a CORBA service to me? Platform independent, language independent, internet enabled? Please don't mention firewalls...Honestly, in many cases web services functionality is just a re-write of well established distributed systems functions as can be found in CORBA and other architectures. And the list of misunderstandings and sheer nonsense is long: UDDI was supposed to let services find and understand each other automatically. The tiny bit of advanced semantic processing missing here did not stop the evangelists from distributing their nonsense. And the web itself was built on a few and very generic functions like get/post and not on fine granular and proprietary RPC functions as mandated by the first Web Services specs.
The protocol stacks for web services were growing fast but nobody seemed to really know what to do with them. Getting back to messages instead of object references was quite reasonable but created problems for grid computing and thats when we got stateful web services back...
Just when Web Services seemed to lose momentum the concept of service oriented architecture popped up. Conceptually it is on a higher level than objects or components: stateless, long-running and composable services seem to represent business processes directly. And thats when the concept of workflow - a term that had become rather tainted due to long and expensive abuse by software companies - made a reappearence as "choreograhy" and processes, activities and services became the latest hype. The question now is: will we repeat the same mistakes as with all the other "latest hype" technologies mentioned above? What mistakes can we expect? How far are implementations really? Before we try to answer those questions it pays to look at out counterpart: the business people and their theories.
- Business Re-engineering and Processes
-
In a talk at our "current IT topics" event at HDM we had Philip Schill of Abbax and Ralf Schmauder of IBM with us. Both work on business process management, modelling and engines. While Ralf Schmauders talk had a focus on SOA and BPM technologies Philip Schill presented also an overview of how the concept of processes evolved within business. And one thing became very clear: business theories seem to mirror IT theories quite a lot: every couple of years a new theory is created and later dropped. It started with business reengineering, became customer centric, later turned into an investigation of the overall production chain and is nowadays collaborative services and reduction to core business processes. Interestingly, both Business theories and IT theories seem to be based on the same (Anti) patterns
- Antipatterns:
Business as well as IT systems are rather complex entities consisting of many elements and different behaviors and goals. The trick is to take one aspect or factor only and turn it into an explanation of the whole. Now, isolating one factor and investigating how this factor contributes to an overall system is surely a scientific way of finding out rules and laws. But business and IT seem to forget that every node or element in a complex system has only partial influence on the overall outcome. Instead they try to convince us that the ONE element or factor is the only one that needs to be dealt with. In the case of business re-engineering each theory took one factor and forgot about everything else. They forgot in that order: clients, shareholders, employees. And IT forgot e.g. the physics behind abstractions like latency and availability and confused development aspects with runtime aspects.
- The process focus and its possible failures
-
So what can we expect from the new business process management and SOA orientation? We will sureley confuse logical and physical aspects of services and run into huge runtime performance problems. We will underestimate the dependencies created between services - not on the development level: here we got quite some independence if we keep things coarse grainded and stateless - but on the business level. What if a service is not available? It could possibly affect many other mission critical processes. We will misunderstand long running transactions. ACID transactions are a no-no between losely coupled business partner: nobody wants to lock their databases for external partners. This means we need conversational transactions but those require a different business model with the ability to cancel orders later without problems. In the case of process engines which will have to execute our models we will see lots of performance and stability problems. Semantic descriptions and constraint processing play a vital role in business processes - we have little experience here and few students get a good education in those areas.
I may have a chance to join an architecture review board for a large business process application and I am looking forward to compare the experiences here with the mistakes of the past - and possibly prevent some of those mistakes to reappear again.
But besides technial problems and failures I am much more concerned about the effects of the process orientation on the way we work. See my article Living in a process world here.
- Enemy contact - dotnet security
-
Sorry, I cheated. It's not on security. I did not make it yet to the security articles in the latest volume of the german dotnet magazine (vol. 5/2006) yet But I will cover dotnet sec. in a later posting. What stopped me dead in my tracks was the editorial. Yes, the editorial, something I usually skip in most magazines. But being a first time reader of the above publication I scanned the editorial and got the shock of my life: .NET ist dead? Not a bit of it in Vista? Possibly not part of the long term development strategy anymore? Only a handful real dotnet apps worldwide? Most Mickeysoft development still done wit C++, MFC and Access? MS most important apps still not on dotnet and not even thinking about moving to it?
The editorial referred to an article by Richard Grimes , a rather well informed and experienced developer who is not known for panic attacks. As you can image this stuff was quite some surprise for me as I usually to not really run into any dotnet stuff in my work. The large enterprise infrastructures I have to deal with are mostly done with J2EE.
But I may have had a bad feeling already before: being a proud owner of a new lenovo tablett pc I was wondering why this beast turned out to be slower than my four year old tosh in many cases. A short google grep uncovered some suspicious dotnet components which seem to all require an unreasonably large piece of ram for the vm. And they where supposedly well known for their sluggish performance.
Not enough, the next article explained some software architecture for an application and oh wonder: I could really understand it because the architecture got explained using design patterns like DTO's (data transfer objects). I know those from past EJB and J2EE developments and I felt at home right away.
So what is going on in Mordor land? Is Sauron getting haemorroids? (Sorry for the language: I got introduced to WOW (World Of Warcraft) lately by a student of mine - thanks Mr. Wiekenberg, it was very educational (;-)
My current hypothesis is: perhaps it is not only the J2EE apps that suffer from low performance and mind-boggling complexity. Perhaps things are just as bad in dotnet land. (remember TCOMs OBSOC disaster? Didn't look like the MS developers really had an understanding of the framework...
I have noticed lately that the number of serious bugs due to misunderstandings regarding framework architectures seem to increase. And I am starting to lose confidence in the type of enterprise architectures that are built on J2EE and seemingly also dotnet.
Will SOA and business process modelling and management come to the rescue? or Model-Driven-Architecture?
I will talk about those developments and their future victims shortly.
- Enterprise IT-Architecture and the Global Services Method
-
 The workshop on IBMs very successful method for architecture development - the IBM Global Services Method - will now
be held for the third time at the computer science faculty at Hochschule der Medien. Again presented by
Bernard Clark, senior consultant at IBM GBS, the workshop will tackle the problem of enterprise IT-architecture. Solutions
will be developed in context of GSM and the SOMA method of IBM.
The workshop on IBMs very successful method for architecture development - the IBM Global Services Method - will now
be held for the third time at the computer science faculty at Hochschule der Medien. Again presented by
Bernard Clark, senior consultant at IBM GBS, the workshop will tackle the problem of enterprise IT-architecture. Solutions
will be developed in context of GSM and the SOMA method of IBM. Today governance plays a major role in company IT development and the workshop will include the task of preparing an IT-Transformation architecture for the merger of two large banks. This task will include risk management and governance.
Participants need to prepare for a rather busy two weeks and three workshop days. Between the workshop days they will have to create workproducts. Those products will then be presented and aligned with other groups on workshop days.
- Some nice links on security and cryptography
-
Mathias Schmidt sent me a couple of nice links on the topics security and cryptography. I can add only one to that list: Google queries returning critical information . This site contains lots of canned queries which expose valuable information. Some of the sites may be honeypots though but I know that e.g. Java Management Extension is a rather sure way into many application servers. The next site contains crypto challenges ranging from easy to very hard, including some steganography. Many interesting papers and theories can be found at Little_Idiot and Mathias warns that the site is highly addictive. This seems to be Cult and very intersting too. I have not checked it as I am not really into code breaking but code building (;-).
- ITAN - or the difficulty of understanding and explaining security
-
A couple of month ago Bruce Schneier explained the futility of multi-factor authentication nicely in his cryptogram newsletter. The argument goes like this: Requiring several credentials from a user to perform authentication helps only against rather simple cases of authentiation fraud like lost/stolen passwords. But most banks talk about multi-factor authentication in the context of the current phising frenzy. Phising is when fake e-mails contain links to fake bank sites run by attackers. When an unsuspecting user clicks on those links he lands at this fake site and will see the well-known look and feel of his bank - only that his is not connected to the bank but to an attacker instead. This is the equally well-known man-in-the-middle scenario. The MITM can now receive intercept the complete communication between client and bank AND modify it in arbitrary ways. But ain't the user running SSL? Of course he does - but the other end of the very safe and confidential channel created by SSL does not end at the bank.... In other words: no matter how many credentials a user will enter, they will all end up in the hands of the attacker who can make arbitrary use of them.
So far so bad but banks like the Postbank introduced the ITAN which goes like so: when a customer logs in the Postbank asks for a TAN but in the case of ITAN the bank asks for a SPECIFIC TAN (e.g. "please type in the TAN number 30". If a TAN is lost somehow it is very unlikely that the bank would ask exactly for that one. But let's look at this in the case of a complete MITM scenario: The MITM would simply forward the bank request to the user, have her fill in the proper ITAN and intercept the response. Then he would fake a new request to the bank, secured with the intercepted ITAN. This is simple proxy technology.
The consequence is - as my colleague Roland Schmitz immediately pointed out - that ITAN protects the customer who is carefully handling his connection to make sure that he is really connected to the right site. And that is exactly the customer type where the regular TAN system works nicely already.
Does this mean that two factor authentication does not work in general? The answer is that it depends on WHAT gets authenticated: the user or the transaction. Consider the following scenario: After receiving a transaction request a bank sends a message back via SMS to the customers mobile phone. If the message is a simple TAN or ITAN (token or request) then it does not help. The customer will send this information just to the same MITM as before who will abuse it. But if the message contains the transaction data for the customer to verify, then we have increased the security of the whole transaction considerably. But again - we have established transaction authentication and not channel authentication.
The university of Bochum built a proxy as a MITM attacker and was able to intercept and manipulate Postbank transactions successfully. They proofed it by transfering a symbolic one Euro value to another account. After what was said above the press reaction was formidable: In just about every newspaper, radio and TV channel the successful attack was described. I saw a couple of newspaper articles but what stuck in my mind was a TV feature. The reporter asked a guy from the University how she could protect herself from ITAN attacks. The answer was quite typical for the usability problems in security: The guy told her she must look at "the little lock in the right corner of the browser" and - just as if getting second thoughts on the value of this statement - added "and of course you must check the certificate". Check the what? What is a certificate? Why would I want to take a look at it? WHAT is it that I need to check in a certificate? I am sure that 99% of the german population did get exactly ZIP value from this statement. And the hint with the lock that signifies an established SSL connection is completely wrong in this context: Of course would the attacker establish a SSL session with the duped client - but it would be to HIMSELF and not between the client and the bank and therefore COMPLETELY USELESS to the client.
I write this just as an example of how far we are away from communicating security in a reasonable and understandable way. Both - specialists and the regular citizens stay behind baffled. One group for the sheer unbelievable lack of knowledge on the citizen side, the other group for the unintelligible techno babble they are given as "help".
- Usability and Security
-
When I stumbled over the capability research done at www.erights.org - which shows the user interface being used to hand over capabilities (rights) in a very granular, safe AND convenient way - and Ka Ping Yee's important requirements for the design of secure user interfaces it was rather clear to me that usability and security would soon become a very interesting and popular topic. This seems to come true now. O'Reilly has published a first book with the title of usability and security and it collects many different articles and views on this topic. I will do a complete review as soon as I'm done with the book but it is surely a very important step in this area.
Usability is such an important topic in computer science - not only for the architecture of secure systems - that we at Computer Science and Media in Stuttgart have decided to make usability a mandatory part of our bachelor and master program in computer science.
- Learning from other disciplines
-
In the context of security I have been looking into what I called "user conceptual models" - a way to represent basic attitudes and behaviors of special users or groups of users. The reason for this construct is the believe that depending on those UCMs certain weaknesses in security can be expected. Let me give you an example: if a developer team that has been working exclusively on the intranet suddenly develops an internet application several basic mistakes can be made and - given a knowledge of the UCMs involved - predicted. Let's say a group develops a web based file storage application. The web app allows users to store their data on a company web server and get back an URL for later retrieval. The intention probably was that employees of the company could use this application while on the road. But of course anybody could use it to share content with anybody else. The team has created a globally available file storage application and not something that only employees could use.
The mistake clearly shows a "intranet" UCM which assumes a mostly harmless and honest user group. Once we know that we should immediately perform a review of the whole application in the areas of input validation and server configuration for vulnerabilities. And there is a large likelihood of finding major problems.
But how can we catch the notion of UCMs in a more formal way? I am not speaking of mathematical formalisms here of course. Just some heuristics (like risk analysis) that allows predictions and estimates of vulnerabilities. UML knows the concept of "actor" - the acting agent behind use-cases. These UML actors are not real people. They are just placeholders for event sources. They do not have history, character, prejudices, social qualities and so on and therefore cannot represent UCMs. But yesterday - during a thesis exam - I learnt something from a very different area that could prove very useful in my case. The thesis was from Taufan Zimmer, one of our Computer Science and Media students and it combined user interface design for PDAs with the implementation of a control application for media devices in home environments. He used so techniques from usability theory like user centered design, analysis, design scenarios and others. Design scenarios contain "Usability agents" and these agents (or personas) can and should carry real live qualities like age, attitudes, social characteristics etc. These qualities are needed to make usability designs and later tests realistic with respect to possible user groups. The agents look like the perfect tool to build user conceptual models for security analysis with.
This shows clearly that the design of human-computer interfaces is not the only case where computer science needs help from other sciences. The same is true for security. In a next step I will try to use more usability concepts for security.
- Sense-Making
-
I really like this term. I learnt it in a talk by Joseph Pelrine on agile development, last monday at Basle. Joseph did not go into technical details like tools that make agile development possible. Instead, he launched an attack at the conceptual models in software development. The leading model is that of development as a machine. Given the proper process software can be produced in the same way Tayler organized the making of cars at the turn of the century. But humans are no machine and the process of development is complex. Joseph distinguised four types of problems and associated problem solving strategies: simple, complicated (academic), complex and chaotic. He says that development falls into the third category - complex systems - where we find rules causality only in retrospective. This sounds true and could explain why the second project is often a complete failure: we try to use the things we have learnt in a first project on the second one and don't realize that the rules and solutions may not fit. Where we also seem to have conceptual problems is in the handling of time. Not so much time as deadlines but time as a factor driving changes in requirements. Few systems are built with an idea of change during lifetime. Ontologies are static as well. They seem to be important carriers of knowledge and experience, nevertheless they are static and they also have this dictatorial touch.
Is there something that splits model-driven development from agile development? Not neccessarily but my feeling is that due to the use of generational techniques in MDA some agility might be lost. It could be recovered through Meta-Object protocols which allow dynamic changes even to the core models.
Sense-making is a core human ability because it allows us to react to new dangers and problems. Over the weekend I stumbled over this problem also in a different context: I attended a talk by Prof. Peter - a well known specialist in immunology. The human body seems to be able to do some "sense-making" as well. It can detect new dangers and react on them. Sometimes this works and sometimes it doesn't like with certain liver diseases. One of the cybernetic problems behind this is whether the body learns to recognize new viruses or whether the bodys immune system is equipped with a fixed pattern matcher that can change only through mutation. Current research seems to indicate the latter. In the talk it became clear that a patient with a rare immunologic disease cannot be treated by regular doctors outside of large hospitals. They lack experience and they don't have time to get it for such rare cases.
The second talk was by Dr. Bargatti, a sociologist working in the medical area and studying patient-doctor relations. He said that many doctors have a big problem with accepting patients as partners. They prefer a machine-like view on the body: if it is ill it is like a broken machine that needs fixing. And many patients share that view as well. In the context of these talks we where quickly in a discusson of the general health system and new developments like the health card. And it became clear to me that we have a sense-making problem here as well: A doctor may be able to spend 5 minutes on a new patient to establish the basic diagnosis and treatment strategy. If the person comes with a healt card that contains her complete medical history this won't help the doctor at all: there is absolutely no time to go through all these documents. But what if an essential document is overlooked? Then the doctor will be asked how he could describe X when a Y condition was present. Given this background it does not come as a surprise that doctors view the health card as a potential danger for the profession.
What can we do? Prof. Peter mentioned work on defining data-models for diseases that allow a faster diagnosis and - most vital - prevent false treatments. Standardization is certainly not a wrong approach. A patients card can then be automatically scanned and processed. But is this enough? What we need are expert systems that can do some kind of "sense-making" as well. Initially it would be great to have systems that can at least extract the most important medical conditions from the health records, e.g. to prevent treatment errors. But in the long term we will need to achive a kind of augmented medical diagnosis and treatment system. This will not be easy to develop as it touches core problems of semantics. But it will also be hard on the doctors: their profession changes from being the gods of medicine to somebody relying on external, computerized help for even the most basic tasks - if they don't want to risk law suits for wrong treatments. And this to a profession that absolutely hates the informed patient.
"You are reading too much on the internet" complains a doctor about a patient with a rare disease. But - given the current constraints in the health systems with respect to time and money - the doctor does not really have a chance to treat this patient properly. This creates tension in the patient-doctor relation.
A few words on the technology behind "sense-making". If we want machines to be capable of sense-making we need to further standardize vocabularies. We need to implement ontologies to translate vocabularies and to capture rules and experiences. And we also need to implement active problem solving technologies. This could be statistics (bayesian networks) and other techniques from artificial intelligence. We will also be forced to use collaborative filtering techniques where semantic analysis does not work (yet). But without proper sense-making capabilities we will simply drown in our information. Simply putting information online is not enough.
Some good literature on the german health card can be found at the University of Potsdam where Dietmar Bremser and Sebastian Glandien have developed alternatives under the title Cross Media Health Care . The authors discuss the use of RFID technology as well and have uncovered some surprising consequences and failures within the health care system.
- Women and Computer Science
-
The thesis topics show the wide range of interests and skills our female students have: Building a professional workflow driven application for the print industry (including multi-client features, security and framework technology. Re-engineering the complete administration of a huge logistics application for a large truck-logistics company, saving the company lots of money due to improved service processes leading to a much faster time to market. And finally a catalog of usability rules and guidelines for web shops. This catalog includes also design rules and can be used for both evaluation and development of usable web-shops.
Do I have to mention that all three got very good jobs immediately? Coming back to the drop in beginners mentioned before: this could be a problem of how computer science departments represent themselves. Both in their homepages and in written materials. It looks like the options and possible combinations within a computer science and media study are not conveyed properly to female students. One of the students had asked me in the second term of her studies whether she should quit and study something else. She was afraid that computer science would be too restricted and that she would not be able to follow her wide interests. Luckily I was able to convince her that computer science actually is a rather open topic. At HDM we work closely with other faculties (e.g. information design and usability, information ethics, business administration and all kinds of media arts. But it is a fact that these choices need to be communicated better.
- Digital Identity and its federation in a SOA world
-
Lately I have been thinking about identity handling within a portal and between its partners. This includes accepting users that have already been authenticated by different systems and also forwarding identities of users to external partner systems. Obviously there needs to be some contractual relation between all these systems and users. Somebody working in security of course first thinks about different mechanisms that need to be mapped to convey user information. From CORBA CSIv2 to webservices security e.g. This also requires a language to describe user properties in a standard and interoperable way. And registries to hold user data. And how to make the partner systems exchange user related information - the problem of federation of identity information. It was the last point - federation - that make me look around for a good explanation of what federated identity really means and how it can be achieved. I read the latest versions of Liberty ID-FF Architecture Overview where the Liberty Alliance Group describes federation of identity through various means. While technically not bad the paper did not really explain federation well. It did explains several different profiles to transfer a token from an identity provider to a service.
Then I saw the new book from Phillip J. Windley, Digital Identity . The author defines federation as the communication of identity information between partners, based on trust and contracts. Companies do not lose control over their customer information. No central repositories need to be created at huge expenses and with fragile content. Windley manages to explain the concept of identity within companies and between external systems in an easy to read way. He shows why federation of identity is unavoidable because point to point agreements between different partners are simply much to costly: identity does not scale in a networked world - the number or relations increases much faster than the number of nodes (participants) which is nothing else then Metcalfes Law. Windley also presents different ways hold identity information: Meta-directories, Virtual Directories and Federated Directories and explans the pros and cons of each approach in detail.
But the book does not get lost in technical detail. Instead, it takes a top-down and business oriented view on identity management. It assumes a world of businesses sharing services frequently, in other words - a Service Oriented Architecture (SOA). The book contains many surprises, e.g. that identity is not simply a sub-concept of information security - there are many security problems and solutions which have nothing to do with identity. Not to forget the many places where identity information is hidden within an organization (and replicated...). Identiy information needs to be transported and understood at the receiving side. Windely explains current standards for identity assertions like SAML, SPML and XACML for access control but the way these languages are presented has the goal of clarifying their role within an Identity Management Architecture (IMA). The author shows the advantages of a well-organized identity handling process but also shows that the ways to achieve such a process are tedious and difficult.
I especially liked the chapter on federation. Windley uses the case of Bank of Americas Credit Card Franchise to show the development of identity federation systems from ad-hoc agreements between two partners over a hub-and-spoke architecture where one partner dominates all others. And finally to a network architecture where an independent identity managment entity (owned by the participants) delivers identity services to all participants. Will we really see companies providing identity services in the future like we have companies providing e.g. payment services today? I don't know but the authors gives some good reasons for such networks: scalability, cost savings etc. This chapter is an excellent example how technical and social, organizational factors all influence a complex topic like identity management.
The book also contains a lot of information on how to build a real IDA - based on the authors experience with creating an IMA for the Utah government. From capturing business functions to creating meta-data stores with data on identity management systems within organizations almost all aspects fo an IMA introduction process are covered. The authors practical experience shows when he discusses lifecycle aspects of identity. When e.g. a new employee starts at her first day, when jobs are changed and reorganizations happen. How long does it take in your company to register a new employee in all systems required for her work?
So before you start to build a Single-Sign-On system for a company, get this book to understand the whole concept behind identity and the possibilities for business based on an IMA. SSO is not the goal of identity management, it is much more a byproduct of establishing identity management.
Privacy is a big issue behind identity management. Here the authors takes mostly a business view and explains existing regulations and the actions companies should take to avoid legal problems. Still, this world of federated identity management does concentrate a lot of consumer information in the hands of a view Identity Providers. Those networks of federated partners - how willl they develop? Will they become largely independent of their founding members and participants? What political regulations will be needed for those networks? And finally: aren't there alternatives which would allow customers to keep more of their identity data in their own hands? Does the isolation between service providers really work or will they over time aggregate cross-service information? Not to forget the rebate case: Windley shows that for relatively small amounts of money customers are willing to give up large areas of their privacy.
So I guess the final question would be: is it right that identity plays such an important role within business and society? Or should we look for ways to e.g. authorize access to things based on capabilities which do not convey identity when it is not needed? Identity federation is without any doubt better than the inital proposals of centralized systems like MS Passport or Hailstorm - but will it stay this way? Or will the forces of the market transform the identity networks into Passport clones? How many will survive? I guess the credit card example is a good way to predict the number and size of future identity networks. Those networks are cross-national, of course. What does this mean for local privacy regulations? The number of open questions is quite large in this area. And Phillip Windleys books helps us a lot to understand those future developments by telling us that that service orientation without federation networks will not happen.
- Hamburg under attack: a pandemia of idiocy hits the north-german city
-
It was not the bird flu that hit Hamburg last week. Instead, a pandemia of idiocy (or some clever political calculus) hit the city. It always starts like this: google news reports some incident like "suspected terrorist killed in London - he behaved suspicious by wearing a winter coat in summer" or "at a busstop somebody overheard a group of arabic looking and speaking men talking about tschihad and Allah - causing a manhunt that involved more than 1000 police and stirred up most of Hamburg. It is those news where one - after dealing with security for a couple of years now - gets this strange feeling in the tummy: what if the guy was wearing the warm coat was just sick? what if he comes from a much warmer country? And Hamburg: what if the guys had been discussing political events? Could it really be the case that a big manhunt gets started on so little "evidence"? But yes, both London and Hamburg have reasons: One (London) wanted to prove how important this new "shoot to kill" law was for the police - at the price of cold blooded murder by the police. I've seen the pictures: the brasilian was wearing a light coat, he did not run away because he was shot sitting on the bench in the train and - if the witness is correct- after being fully restrained by police forces already. This is usually called murder.
And Hamburg? Hamburg is preparing for an election. It has a kind of "law and order" history (think about this Schill guy, an ex-judge turned politician). And a bit of a terror alarm cannot hurt to "emotionalize" the general public. The psychology of terror alarm works so nicely in the US that German politicians get envious.
At least they did not shoot the three "arabs" right away once they got them. Turns out they are no arabs at all but Inguschen (that's somewhere close to Tchetchnya where all those terrorists live according to brave Putin). Unfortunately their arabic is rather poor if non-existant - even though police claims that the can speak some arabic words. It is of course very likely that they will use their poorest language to plan terrorist attacks - its all for disguise.
What can we do? Besides hoping that the bird flu will take those politicians there is only one thing we can do: Explain the mechanism of FUD (fear, uncertaincy and disinformation) and its political use over and over again. Make people read Bruce Schneiers "beyond fear" to understand the tactics behind raising fear. Make people ask about who gains what by raising fear. Insist on good and fair politics as the best protection against terrorist (yes - do the unthinkable and ask yourself: could the terrorist have some reason for their deeds? Forget about what our politicians tell us about terrorists and suicide attacks: a suicide attack may look completely unnatural and crazy but think about this: once you have decided that you would go to war over something there is always the chance of getting killed - perhaps without even getting a chance to hurt the enemy. A suicide attack is a rather rational way to fight once you have accepted the premises. But of course the idea of a rational terrorist is unpopular and politically incorrect: it makes them look as if they had a reason for what they are doing. As if there could be some fault on our side as well.
And perhaps the most important thing: make us distrust our own - as author Christa Wolf says in "Cassandra". And we Germans have a lot of reasons to distrust our own military, politicians etc. - more than anybody else even though the US americans are catching up quite well
- RFIDs, passports and a clever business model
-
Otto Schily, the german secretary of internal affairs - together with Philips, Siemens and other bigwigs of the semiconductor industry - is pushing hard towards the new passport design made by the BSI (Bundesamt für Sicherheit in der Informationstechnik). Critical voices are not really wanted during this process as the case of Andreas Pfitzman and others shows. Andreas Pfitzman - a well respected professor for security at the TU Dresden - was supposed to give a talk at the yearly BSI conference. He was "un-invited" shortly before the conference started. Insiders claim there was direct pressure from the internal affairs office on the BSI president. But was it really hard to make the BSI give up on some principles? Let's look at three things: what Pfitzmann wanted to say . What made the BSI give in. And some comments on the new passports, their technology and the business model behind. And at the end we will throw in some sad comments on the fate of Germany's "Datenschutzbeauftragte" - supposedly independent protectors of civil rights on data and anonymity. (A note to americans: this looks like a strange concept because in the US data belongs to those who collected them...)
Let's start with what Pfitzmann wanted to say. First - it was nothing revolutionary. Or chaotic, basic-democratic or other dangerous stuff. He mentioned some dangers behind biometrics. Did you know e.g. that iris scans do not only identify a person - they also tell about the persons health. So when you come in Monday morning the company already knows how bad your weekend really has been (;-). According to Pfitzman this was common knowledge in security circles and now you know it too. This gives btw. a nice argument against the good old statement: I got nothing to hide - REALLY???
More interestingly Pfitzman talked about "unobservable areas" as a human right and this is where his talk is really frightening: he positioned those areas into the digital world only. In other words he has already given up the hope to create those areas in the real world. Before this I had not really realized how far we are already going with video surveillance, bugs and remote controls...
Another disturbing statement from him about biotechnology and biometrics. It is (hopefully) common knowledge that biological attributes used in biometrics are no secrets. But Pfitzmann pointed out that the other trait of biological attributes - their uniqness - may not much longer be held up as well. With our genome information in the databases of biotech companies we run the danger of having fingerprints, irises etc simply reproduced from the spec. This will be a big boon for many patients no doubt but at the same time it will destroy biometrics.
So far to point one and now we need to talk about what drives the BSI to kick out such an expert. The answer is two-fold: Money and power. It is a money thing because of the participation of big semiconductor companies which want to make the passport system a standard in EU country and hopefully worldwide as well. We are talking big money there. But this may not have been enough. But Schily threw in something more: The BSI can become the "fourth pillow of security" in Germany. I believe this was what made the president of the BSI change the conference schedule... You can read more about in the C'T magazine of June 2005.
Now for the passport. They contain an RFID chip - but it is restrained by an additional optical scan process which reads your name, birthday etc. and generates a key from those data. The key will be presented to the RFID chip which will then allow access. No secret reading of your biometric data from somebody walking by. Ok, the data needed for the key are not really hard to get (you need to provide them e.g. when you apply for socker tickets for the world chamionship) but that would be really nitpicking.

So far so good if it where not for this dumb question that pops up in ones mind: why do I need an RFID chip when remote reading is not possible??? Even the german "Datenschutzbeauftragter" was wondering about this. But I can help him here:
There is an RFID chip on the passport so that police, secret service(s) and other legitimized organisation can read your data without bothering you. This concept is well known and was discussed in the 90's in the US under the term "clipper chip" and "key escrow". It basically undermines your right to privacy and digital security completely and was rejected then (glad this happened before 9/11).
There is an RFID chip on the passport because it lets the providers use a nice business model: Instead of well known but cheap and safe technology like a smartcard chip (remember: banks use it for money!!) the RFID concept allows the industry to charge at least Euro 59 for this passport. Now that is a nice increase from proviously 29 EURO. And what's even nicer: it is a business model the citizens cannot escape. If only I had such ideas every once in a while - my new motorbike would not still be at the dealers...
Now to the last point: the "Datenschutzbeauftragte". They are not really popular with the industry or the politicians at the moment. But help is coming: Schily does not let a chance go on pointing out that due to those people we have: a weak industry, terrorist dangers, child pornography rampant and in general a population ridden with warts, sore feet and bad breath. And the first state government in Germany already took action: The NRW datenschutzbeauftrager is no longer responsible for the industry - just for government organisations. Watching the industry is now the job of the secretary of internal affairs in this state - remember: the one organisation also responsible for secret service(s), police etc. At least now the data and those who want them most are together...
A last point: Recently 40 Million credit card data where exposed in the US. The reaction of the US government at the same day was: after intensive lobbying of the health industry the paragraph which threatened them with criminal charges in case of negligence with patient data was removed. Civil rights sure are not very popular currently.
- IBM University Day at HDM in Stuttgart
-
A very interesting program is waiting for interested guests from industry and academia. IBM specialists are presenting current experiences from large scale projects in the industry. And students will profit form carreer information provided by IBM HR.
This is an excellent opportunity to meet IT-specialists and learn the latest on how to run successful projects. - Global Services Method Workshop 2005
-
Digital Media in Finance is the topic of this years workshop on IBM's Global Services Method.
 A rare opportunity for students of computer science to get first hand knowledge of methodology in project management and architecture. Bernard Clark - a senior consultant in IBM's Business Consultant Services - is holding the workshop for the second time now at HDM. The first time was a big success already and this time the theme - digital media - is right at the core of activities at Hochschule der Medien.
A rare opportunity for students of computer science to get first hand knowledge of methodology in project management and architecture. Bernard Clark - a senior consultant in IBM's Business Consultant Services - is holding the workshop for the second time now at HDM. The first time was a big success already and this time the theme - digital media - is right at the core of activities at Hochschule der Medien.As always it is amazing to watch the progress students make during this workshop. They have to start with few directions (so called work products) which set the stage for a large project. E.g. the "Strategic Directions" work product which just gives the vision of management behind the intended project. And "current IT infrastructure" which describes the existing environment (to some degree).
The students are given the task of preparing further work products, ranging from use cases and user profiles to system functional or component models. After some initial complaining about the vagueness of the task (being students of a technical program their attitude is more like: "give me the spec. and I will build it", they now have to take over different roles and start reasoning about project goals and business intentions.
But at the second day of the workshop - a week after the first - the students see how the statements and papers of the different teams suddenly start to make sense. The documents - no matter how vague they seemed from a students point of view - slowly turn into a base to rely on. Suddenly contradicting assumptions are realized and resolved. And oh, assumptions: how hard is it at first to start making them so that a team is able to make progress if other teams do not provide needed input in time. Again something very realistic and important to learn.
It is essential for students to learn those techniques used in large projects. To realize how important a process focussed on deliverables is once you have many people working on a task. And how bad it is if somebody does not deliver for the overall progress of the project. Here again Bernard Clark provides lots of important advice on how to deal with difficult situations.
And for us doing the workshop it is always interesting to see the different ideas and approaches the students use for their work products. And we are very happy that we can offer this opportunity to our students - thanks to Bernard Clark and IBM.
Note
We are planning several events where specialists from IBM and DaimlerChrysler will tell us about the latest develeopments in the industry: SOA, proactive Systems, Management of Change, global infrastructure platforms etc. The events will be open to the public. So stay tuned for information on time and topics here and at the HDM homepage.
- Recommendations for Java related literature
-
I get frequently asked about recommended Java books. This list covers most of my favourites.
- Entry level
-
This is a bit of a problem as I learned Java from the Java APIs. I bought the ..in a Nutshell book but I wasn't convinced - the difference to the API level was too small (Do not confuse it with the "Java Examples in a Nutshell which is excellent - see below). At that time the Bruce Eckel book was very popular but to be honest: it is just too fat (or should I say "rich"? Reading the Gates speech from RSA 2005 has done some damage). There are some good ones in German:Joachim Goll, Java als erste Programmiersprache or Christian Ullenboom, Java ist auch eine Insel.. It probably depends on your knowledge in OO languages in general.
If you are an absolute beginner with the the drive to become a master programmer and computer scientist I'd recommend the classic text by Abelson/Sussmann, Structure and Interpretation of Computer Programs (also available in German). Or a book from the Series: How to think like a computer scientist: learning [Python|Java|Cplusplus] by Allen B. Downey
If you need some more informations about design patterns, get the new "head first design patterns" book from Oreilly. Or follows my recommendations in the design pattern seminar.
- advanced
-
effective java by joshua bloch (mandatory, available in german as well). The truth on garbage collection, performance, exceptions etc. For performance take a look at Jack Shirazi, Java Performance Tuning and the performancetuning website.
I always found it much easier to learn from source code instead of going through boring API documentation. Steal code from: David Flanagan, java examples in a nutshell (important: EXAMPLES, version 3) . Use the source for your programs. Fun.
To stay up-to-date on the latest developments be a regular on Onjava.com and developerworks
Advanced pattern use: find some good hints on what makes flexible software fast in Gamma, Beck, Extending Eclipse. Perfect.
- Enterprise
-
Ted Neward, Enterprise Java (a must for enterprise level programmers). And patternwise: get Martin Fowlers Enterprise Architecture patterns as well.
Also: get one of the J2EE design pattern books (follow recommendations from theserverside.com )
To get a better understanding on application servers and J2EE architectures I recommend the Websphere book from Wrox. It's the one with Eric Herness and Rob Haye - guys I used to work with in the good old Component Broker times.
- Server building
-
Again, Ted Neward, Server side java programming. Makes you understand what it takes to build an application server (classloading etc.)
- Remixing, social and technical aspects and the brain for designers - Oreilly Emerging Technology Conference 2005
-
Taking a look at the program I noticed that it may not be the time for the big architecture or the master technology. Instead, lots of re-use of services and ideas: re-mixing is the new strategy. Sounds like what the webservices people already promised years ago. But here we are not talking specs and APIs. Here we talk services on the web and ideas on how to recombine them into something new. the ideas, their embedding into a social environment, are definitely more important than a specific technology.
The big master ontology seems to have lost also. At least according to Clay Shirkey. He now likes the chaos of community driven definitions.
Etech would not be Etech without lots of borderline IT topics like e.g. the brain for designers. But when I look at where I currently get the most requests from industry it is exactly this area: the area of usability and user conceptual models (and with respect to security I'd like to add: programmer conceptual models as well). My theory: successful companies will need to understand the way their customers, users and programmers think if they want to sell successfully. And us programmers we will have to learn how the users brain really sees our designs.
What else is there? A lot about wireless of course. The mobile phone as an edge device. Classroom projects in mobile computing. Community building software. And for the distributed computing fans: anonymous communications and swarmstreaming - a p2p technology to distribute realtime multimedia streams.
What about us here in the "old Europe"? One could feel a little left behind. I don't know of a conference in Europe that comes close to ETECH. There seems to be no interest in the industry to sponser such ideas. And in doing so the European IT industry acknowledges once more the leadership of the US with respect to all things computing - and its applications.
- New Course on Generative Computing
-
I will hold a new course on Generative Computing in the summer term at HDM. Last summer we where exploring generative technologie in general. This term we want to make a step further into designing domain specific languages (DSL), generating compilers (perhaps for input validation) and learn more about software production lines.
Software production line architectures will include software families and the understanding of commonalities and variations.
If all works out we will even be able to take a glance at the way software families are built in the automotive industry where embedded control computers are controlled through thousands and thousands of parameters.
We will also investigate game design and the architectures needed (interpreters, data-driven design, environmental acquisition).
Modelling will of course play a major role. And meta-modeling as well. I am especially interested in learning more about semantic languages based on XML (RDF, OWL, OIL, DAML) and business process modeling and execution languages.
But we will also investigate the difference between the problem domain and the solution domain - a distinction OO analysis and design approaches have tried to negate for a long time. Ulrich Eisenecker in the latest Objektspektrum Magazine (02/2005) had a very nice example about it: He showed two class diagrams about computer mice: one was ideal for explaining the existing types of mice (two or three button etc.) The other one ideal to build such mice. Interestingly, the second diagram seemed to be more technical but also more abstract at the same time because one could build all the mice from the first diagram from it - and some more.
I have never believed the OO credo of a seemless mapping between analysis classes and implementation classes. I always thought that the machine finally has to work on a more abstract level than the business problem. To explain this (and that is also the reason I have never really believed in use-cases as the final instrument to build good machines): Let's say you want a car to drive from Stuttgart to Munich. Do you build one for exactly this purpose? Or are you going to build a car that will also take you from Stuttgart through the alpes to Milano? We software people would probably end up at the alpes with a steaming engine - complaining that such elevations "where never part of the spec". What does this tell us about generators? Frameworks and especially production line software? Do we need different attitudes, a different way to organize software, different technology or all of this?
And while we are at OO bashing. The magazin also hat a nice article on SOA - the Service Oriented Architecture. Its title was "from OO to SOA" but had soon to admit that SOA was only a different way to specify interfaces. More granular and with value objects instead of behavioral objects. The article was able to show some deficits of the way we have used OO to model busines processes (actually: did we ever really model processes with objects?). I still remember the endless discussions about "business objects": how much behavior should go into them? We started with putting way to much behavior (process?) into them and ended up with brainless value objects as the latest design pattern in enterprise components. Quite a sobering experience. So how do we get to SOA and generated business workflow from BPEL specifications?
But we will also cover some base technology. How do you use the new Java annotations to generate code? Last year we've successfully tried the XDoclet and related approaches. What changes with the new tiger features? And what about the Java Metadata API? Is it useful?
How do you make software more flexible? We will go through all kinds of approaches like external configurations (todays XML graveyards with all the related maintenance problems), intelligent runtimes (using interpreters) and generative approaches which produce highly inflexible software which is tailored to the specific problem. And we will learn how to connect an interpreter to software framework.
There will also be quite some theoretical stuff like how to separate business logic from layout in template languages and how to evolve Java APIs (drawing from experiences the Eclipse designers made). And last but not least we will look at a project that combines the eclipse client runtime with a J2EE client container. Here we will learn a lot about isolation of components by using classloaders.
Testing is a lot of work if you want to do it manually. Even test engines like winrunner or loadrunner need a lot of scripting that needs to change if the GUI changes. But what if you could generate most of the tests as well? Assuming that you have a model for your application that includes DB, GUI and business logic. Shouldn't we be able to use this model to generate test cases as well?
All in all I guess it will be a rather interesting course again.
- Why distributed systems are difficult - it's in the business requirements
-
The first question in my last distributes systems written exam was supposed to warm the students up for the harder stuff. It turned out the be the hardest question of all. The students where able to describe the delegation mechanism in kerberos or distributed garbage collection technologies and so on. Nobody seemed to have big problems with advanced distributed technology in general. But the first question went like this: “ you are designing a distributed application with a browser based front-end where clients have to type in personal data, e.g. zip code and city. Business sees that and wants the city to show up automatically when the zip code is entered. Discuss this requirement. What do you do if business insists on this feature?”
Ok you say. Where is the problem. There is a clear relation between the zipcode and the city and if you know the zipcode you know the city automatically. But wait, did you say distributed and browser based? That would mean shipping A LOT OF DATA to the client browser to do the lookup. Exactly all city names and their relation to the zipcodes. This will take AGES to download. Another alternative would be to leave the city/zipcode data on the server and - after the client types in the zipcode - submit the page, do the lookup on the server and return a new page with city filled in to the client. The typical trade-off between space and speed. And it may even surprise the users because of the additional roundtrip.
An answer like that could be expected after a whole term on distributed systems including a desing session where I excplicitly mentioned faults like not thinking about data size or latency. Not to mention the 8 fallacies of distributed computing that we've gone through. I got all kinds of answers like considerations on the security of the lookup etc.
Thinking about my own mistakes in distributed computing in the past I believe I know the reason: the students didn't see the problem because it is hidden behind a business requirement and split between two tiers of architecture. Our functional thinking kicks in and we concentrate on what is required: an easy lookup. And we completely miss the problems the solution would cause for a distributed application.
Unfortunately in reality requirements are exactly like that: vague, technically problematic and in many cases accompanied with a tight deadline. The case just confirms to me that we still need to improve the way we demonstrate and teach technology. It is still very hard to take a holistic view on requirements and be fair on business and technology. And it also proves that there is only one way to learn distributed programming: build distributed systems - lots of them.
But wait - there is another twist to this story. Cesar Keller, a colleague of mine, showed me a way to solve the above problem without sendung lots of data to the client and without making another roundtrip to the server. The secret is called "xmlHttpRequest" and it is an extension to DHTML which allows clients to pull xml fragments from a server and insert the data into the browser DOM without a roundtrip. You can find more on it here: XmlHttpRequest. It is actually not such a brandnew feature in browsers but seem to only get some attention lately.
We are currently looking at technology to improve the client experience with the help of advanced DHTML and XML translations and - due to browser bugs - had to fall back to server side translations. Thus a way to pull xml fragments dynamically is very attractive.
And - as a sign of "deformaction professionelle" my first idea was: how about the security of this feature? Turns out that it is designed quite safely: you are only allowed to pull data from the server where the page was coming from. Otherwise we would run into the same problems as with frames where attackers assemble pages that look like e.g. bank pages but contain faked parts. Deeply impressed about the safety concerns behind this feature I popped up google and found my paranoia satisfied: About two years ago - I said it's an older feature - you find all kinds of security problems with xmlHttpRequest. Like not respecting the location constraint (safari) to violate client sandbox security (mozilla, firefox) by reading local files and uploading them and so on. I could just see the way this new connection was implemented: with lots and lots of "if ... then ... else" statements which unfortunately every once in a while where forgotten.
- Sarbanes-Oxley - or when the inmates run the asylum (safely)
-
How do you restrict those who are per definition unrestricted? The top CEO's and CFO's of large zaibatsu's (here in the sense of William Gibsons super-corporations) are the target of the Sarbanes-Oxley act. The act was a result of large scale financial manipulations by companies like Enron, Worldcom, Parmalat etc. especially during the boom phase of the .com economy. The act is interesting not only because of the hefty price tag of an attestation. It is interesting because it touches several basic principles of security:
The policy of least authority (POLA) The AAA principles (authentication, authorization, auditing) Non-repudiation (nobody can deny what they did) Hierarchical roles and rights systems Anonymity (are whistleblowers protected?) General IT-security like network security, system security etc. Resources and responsibilities (everything has an owner) Four-eye-principle For finance companies those are quite normal topics which have been well established and implemented in their IT systems and processes. But as my colleague Richard Liu pointed out: Banks or other financial institutions have a lot of experience in so called "Risc Management" - that is keeping key players honest and preventing damage from illegal or non-sensical operations or manipulations.
So it was quite interesting what Monika Josi, Chief Compliance Officer of Novartis Animal Health reported on the SOX process at Novartis in the last year. Pharmaceutical companies know other sorts of risks (like patients being harmed or patents issues) for which they have established routines and processes. The introduction of a control system targeted at the financial side only was something new.
I will only point out the key things that I learned from her excellent talk. Some background: Novartis started the "Soxifying" last year in spring with the goal of getting attested end of 04. A project was started with good backing by top management and stakeholder was a key finance manager. In 7 business areas 41 so called key controls where defined. 75 percent of Novartis sales should be covered worldwide.
- SOX Standard
-
Just like many software development methodologies the SOX standard turned out to be too big, to vague etc. So tayloring was needed and Novartis decided to concentrate on the areas with a potential for high-risks. This where the financial systems like SAP and some custom applications in datacenters worldwide.
- SOX Process
-
It covered the following steps: Project definition and start. Scope definition. Creation of cookbooks. Training of the trainers. Local Tests. Gaps and gap analysis. Walkthroughs. Integration of SOX activities into other quality management standards already established. IT-Security (e.g. authentication) turned out to be the largest area. And testing was the phase with the most effort spent. The Sox process is currently still driven by the quarterly/yearly reporting duties but the goal is the integrate it better into systems and thereby automate things better.
- Changes
-
During the SOX activities many things where discovered, e.g. misunderstandings between global and local operations, finance and IT responsibilities etc. Change management was enforced, 4-eyes-principles and strict authentication. Better business role definitions where created which restricted unneccessary rights.(POLA). The result was a better understanding for IT governance on all sides.
- Activities
-
Designated SOX reps in all locations had to create flowcharts etc. of their processes and systems (following the instructions from the cookbooks which turned out to be extremely helpful).
- Effort
-
The SOX effort was massive. Both in time and money spent.
- Synergies
-
During the SOX activities many related projects and methods where detected. It would be very useful to synchronize the efforts here.
And if you want to know more about SOX: here is a link to an article on SOX (thanks Richard).
After the talk we asked Mrs. Josi about the impact of SOX on content management and publishing. Mrs. Josi pointed out that the focus at Novartis had clearly been on financial systems (SAP etc.) and not CMS. And the IT-Systems at Novartis (and the processes behind) has seen some improvement through SOX. The experience (besides the costs) where very positive and even resulted in the start of a large framework project with the goal to cover all Novartis entities.
But let's get back to the original goal of SOX: Preventing CEOs and CFOs from cheating and ruining companies. During the talk I had the impression that SOX causes a lot of common-sense improvements in IT and finance systems. But I had seen nowhere real evidence that it would prevent cheating at the top level of corporations. This is an area where a lot depends on estimates and personal tastes and I could imagine that all the SOX change will not prevent a CEO from certain manipulations. But this has to be seen. Unfortunately I don't have the skills to really decide whether SOX is another security paper-tiger designed to calm down angry investors or whether it really makes a difference. Comments on this by business people are certainly welcome.
- Techno Bubbles and Train-Marsupials
-
In Living in a techno bubble D.Parvaz claims in the Seattle Post that we are about to loose face-to-face interaction to our electronic gadgets. My colleague Richard started a discussion on this when he sent the link around and ran into some friendly fire by younger colleagues which e.g. made the point that mobile phones definitely increase social interaction (though not face-to-face admittedly) and that a new playstation always attracts comments from others - many of them you may not know yet. (The "look what's that" effect). Richard countered correctly that TV has already shown the isolation effect since its beginnings (Since then families turn into a rather strange formation when the TV is on). And in many other cases the live situation seems inferior to what can be seen on TV - simply because of better camera positions etc. Some sports have been heavily transformed to satisfy media requests.
But before we are getting lost into socio-economic theories on the techno bubble effect let me tell you that the mystery has been solved. At least when it comes to trains of the german bahn I have now discovered the true force behind the techno bubble effect - the reason why people tend to wear all kinds of gadgets on a train, mostly attached to some kind of earphones.
On my way home insight struck me like lightning: The train-techno-bubble is caused by an animal. It is caused by the common train-marsupial (in german: Zug-Beuteltier, in latin literally tranus bagusanimalus). This animal usually takes place opposite to your seat and - once you have taken out your book or paper - starts its nerve-racking activity. Well disguised with a suitcase or a knapsack it produces a paper bag from the inside of its luggage. The paper bag usually shows the logo of a local bakery or butcher. And then it starts. It grabs the bag in a way that produces a lot of noise by crumpling it in all possible ways. Some direct the paper bag directly at their mouth and start feeding on something - again crumpling the paper with fingers to make more noise. Others put their fingers in the bag and - trying to produce as much noise as possible - start tearing pieces from something inside the bag and putting it in their mouth. Both types of marsupials tend to make shy glances at their neighbours (in that well known Mr. Bean style), probably hoping that they would not be recognized in their disguise as regular travellers.
What are they feeding on? It is of course not the american or british kind of bread or toast. Soft, tasteless and consumable with a minimum of noise. No, it is the european (note the continental approach here) version of bread, baked to be crisp and create splinters on every bite. Splinters which you will find in your book or paper later on. And again of course - the highest level of nerve-racking noise. And so it goes on seemingly in an endless way, from station to station until finally the last bit of food has been consumated. Thank God! But no, its not over yet. In a last, desperate effort the - now empty - bag itself gets crumpled and folded and re-folded until you are ready to jump out of the window.
I believe it is the presence of those train-marsupials that causes the techno bubble effect on trains. In sheer desperation people start wearing earphones - mostly of the in-ear type which promises the best insulation from noise. I have to admit that there may be other reasons as well, like the constant use of mobile phones by teenagers on commuter trains which can equally drive you mad. But I have now bought a set of Koss, The Plug from Amazon. It is an in-ear earphone which completely - or almost completely - shuts off the surrounding noise. I haven't got a mp3 player yet. I fear the total cost of ownership of anything that has a CPU in it. But at least I can now again read my books and papers on the train...
- Systrace in OpenBSD
-
The system call interface is usually the place where a program switches from untrusted mode into protected or trusted mode. At this point subject, object and action are clear and can be checked against a policy. The systrace utility in OpenBSD makes ingenious use of the information available in system calls and uses them for advanced access control decisions. This way a program or server can easily be put into a sandbox with restricted rights.

Ways to use Systrace:
-
Secure untrusted code from downloads. Put this code behind a policy when it is run.
-
Secure open services. Put network daemons and services behind a policy and restrict e.g. the way they can access files.
-
Restrict user rights. Put untrusted users or all users behind a more restrictive policy.
These use cases where taken from the systrace chapter (freely available) by Brandon Palmer and Jose Nazario, Secure Architectures with OpenBSD.
Evaluation:
The systrace utility shines through its easy way of configuration. (If you don't believe this, just wait for SELinux). It does not require an immediate all-or-nothing approach and you can start with securing single services.
A common problem to those systems is the definition of policies. Most systems can just record all actions and then generate a policy from the log. This can lead to programs that run with too many rights or to frequently failing programs due to "permission denied" errors - something users hat. The problem simply is that programs to not define the resources they are going to user in any way at installation time. There is also no language which could be used to do so. This means that trial and error is the only way to define a proper policy - starting with no rights at all and then adding rights piece by piece.
The system call interface allows more interesting things with the help of systrace. Debugging, testing and tracing of programs is much easier using systrace.
Currently the logical operations in systrace are somewhat restricted (Don't forget that those checks need to happen at runtime) and a combination of identity and code rights is not possible.
-
- Sorry, a software problem has caused...
-
This message was on display in the brand-new ICE train I took on my way back home. It told me that a software error caused the electronic reservation system to be inoperable and that travellers where supposed to give up their seats to reservation holders. This caused quite some fun when large numbers of trolleys finally clogged the aisles and passengers started to call each other names. Can you image a better way to end a day which had "the development of reliable software" as its topic?
Karl Klink has done an outstanding job with his talk on how to develop reliable high-quality software on mainframes. From more than 30 years of experience he told us what makes good software. The secret is in good employees, good teams, good methods and good and clever organization and last but not least good coding practices. But how do you get all these "good" things in the first place?
This is where Mr. Klink surprised us all. He is obviously not a process believer - but believes that processes are a good thing. The devil is in the details here. A process believer is somebody who buys a development process (e.g. the rational unifies process RUP) and believes that this will guarantee success. A person believing in processes thinks that good quality requires some kind of regularity and structure but that a team needs to pick its own process and select only relevant parts of it. This is a big difference.
He is also not a technology believer - but believes that technologies are important and need to be respected. And especially those who develop this technology. The difference is about the same as above with processes. A technology believer will buy into a new programming language and believe that this language is better than all the others and that it will guarantee success. Believing in technology is recognizing that there are many possible technical solutions to a problem but that a team will only be able to achieve success if it picks something it is familiar with (and something the team likes and wants).
Mr. Klink did put a lot of emphasis on the social organisation of teams and departments. On clever ways to make people take over responsibility by giving them freedom and independence. On the importance of getting developers while they are young and can be formed by an excellent team. On the role management has to play (like standing behind their people by taking a stand).
A good example of clever organization is the way test engineers and development engineers are organized and work together. Some companies put them into different hierarchies. Successful companies make them work closely together so that the test engineer starts working at the same moment when the development engineers starts her task. They share design and implementation know how. This will bring down the number of bugs per piece of code considerably.
In many examples he showed the big quality differences between employees, team members and departments. Sometimes reaching factors. And he did this by giving real numbers and concrete examples. That's because he also believes in measurements and analysis. This seems to be one of the really big problems in IT and computer science: We don't learn from mistakes. It was amazing to see the improvements which where made mostly by changes in the organisation of work and not by throwing more money at a problem.
Other important statements where that bugs are far from being equally distributed. They tend to cluster in certain packages and complexity and size are not the only factors. In some examples Mr. Klink could give clear reasons why a component had a bad quality - many times the quality problems where rooted in personal or organizational deficiencies. "There are at lest 10 jobs alone in development" was his clear statement on different personal attitudes and abilities and that almost every employee has an optimal place where she or he can shine. All it takes is management seeing and reacting if somebody shows signs of problems.
And then - the finale. Mr. Klink told us - after giving us a picture of a high-quality development process in the area of a mainframe operating system (VSE) which is well known for its low number of critical bugs - that in his eyes the open source development style which is used e.g. for Linux is extremely close to what he did within the company. Or even a bit better with respect to source-path-coverage in testing.
How could this be? Item for item he showed us that the open source development process with its maintainers, contributors and helpers is far from being chaotic. Instead, it is a rather brutal way to eliminate bad ideas by the use of competence and proven quality instead of mere authority. A good team does not accept blind authority. You can only be part of a high-performance team if you can prove you can achieve something with quality. The same almost darwinistic principles apply to open source. The bazaar can be a rough place because people have a choice to buy or to walk away. Many companies do not create an environment like this and work on mere authority instead.
Open source is driven on vision, not command. So are good teams. This explains why so many skunkwork projects turn out to be successful. It is because of the dedication of their members. And open source projects tend to achieve minimal interfaces (compared e.g. to bloated 600+ functions in other areas). They are also not shy of reverse-engineering or simply dumping bad code (avoiding the "big ball of mud" anti-pattern)
This has led to interesting social things within IBM: there are now employees which wear two hats: they are linux maintainers (independent) and line employees of IBM. It will be interesting to see how far this process will spread within IBM and whether more companies will follow this way of software development. This could revolutionize the way we work and live.
At the end we where all convinced that we had seen and heard one of the best talks at HDM ever. And we sure hope that this will not be the last time that Mr. Klink has shared some of his experience with students and profs. And there was one last thing that Karl Klink has shown us: Good management is believing in (young) people and by fighting for your ideas even if they seem to not fit into current political thinking. New ideas are rarely popular in companies as Clayton Christensen has shown in his "innovators dilemma".
- Like a Cookie
For a good start on RFID and wireless technology in general see Lightweigt RFID framework by Chen Junwei. This developerworks paper explains basic wireless terms like inductive coupling (short range) vs. propagating electromagnetic waves (long range). It also shows that RFID technology combines three important qualities: identity, location and condition. It is the combination of information that makes it so much more powerful. This is very similiar to the use of cookies for identification and combination of web based information.
Cookies set by doubleclick an Co. work like primary keys in a database. They allow the aggregation of arbitrary information behind one concept. Where an RFID tag tells something about the location of an identity, a cookie tells doubleclick about your behavior on the web - including the locations you have visited in the virtual world. Only the condition feature - like reporting the bio-status of a person or animal - does not fit nicely into this comparison. Seemingly harmless information left in one place (say you didn't leave your name there) can be automatically extended with the missing parts through recombination of bits and pieces you have left in other locations.
From a privacy point of view both cookies and RFID tags are used to combine information against the expressed will (or without their knowledge) of private persons.
But what I liked especially from Junwei's paper was the diagram on RFID infrastructures. It shows how big such infrastructure can become and how tightly RFID information is tied into existing databases and processes.

- Don't Authenticate Me!
-
Frequently the functional aspects of wireless RFID technology and smartcards made to look similiar by using the distance argument: RFID chips (supposedly) work only on short distances. So it does not make a big difference whether you embed an RFID chip or a smartcard chip in a passport. Your privacy is protected anyway.RFIDs are simply more convenient.
This argument stinks for the following reasons:
The ability to get to your data is now a function of the field-force applied to read out the RFID tag. Your control over your data is now no longer at your discretion Distance is NOT a useful tool to protect private information in a wireless world. Already no we can read RFID data from much greater distances. Once enough people are equipped with passports carrying RFID chips it is feasible to control masses (e.g. during demonstrations) by scanning whole groups from a distance.
Bluetooth is called a personal area network which is supposed to work mostly between 1 and 10 meters. Already now we are stretching those limits considerably and - using a bluetooth gun - private communications via bluetooth can easily be overheard and manipulated from 100 meters and more. Again, distance is NO protection in the wireless world.
And what about your control over your data? With a smartcard chip carrying your data you can control IFF and WHEN your data are taken. Simply because the card must be run through a reader and your pin is required. And even if you are forced (by state or by gun) to disclose the data, at least you will KNOW that your data where captured. With RFID chips embedded in passports you will NOT be able to control when and where your data are taken. YOU WILL BE AUTHENTICATED.
What about protective measures like cases etc. A short story from the trenches of everyday life: Being a biker I like to use a magnetic backpack which is easily fixed at the tank and held there through 8 strong magnets. Convient but unfortunately the magnets have the tendency to wreck my creditcards about once a year - even though I am very careful and try to never put them directly inside the backpack.
After another round of ordering a new set last year I remembered that I have lots of friends with all kinds of degrees and PHDs in physics (theoretical and experimental). So I thought that they sureley would know a special metal case that I could use to protect my cards from the evil magnets. When I asked around I learned a lot about physical things - most of them I immediately forgot - and finally left with the well-meant advice: Actually, the only thing that helps is to not bring the cards close to the magnets - thank you very much. Professor google could not help either.
Taking to specialists at the bank I learnt that at least there is some hope for the future: the regular creditcards will be all replaced with smartcards carrying a chip that is not susceptible to magnetic fields.
Conclusion: There is NO reason at all to put your passport data into RFID chips where they rest - unprotected - for everybody to extract. Don't fall for the convenience argument: RFIDs in passports are only convenient for people who have no respect for your privacy and who would not hesitate to put you in danger by exposing your data to anybody. Do you really want to walk around telling everybody who you are? Think about this information being correlated with databases about persons, their wealth and habbits and then think again. Do you want to be singled-out and mugged simply because some crooks could read your data from a distance?
For the technically interested: most current operating systems and applications use authentication based logic for checking access to resources - so called access control lists (ACLs). Every resource here has an associated list which contains an identity and which operations this identity is allowed to perform. Of course, authentication - the process of checking the identity - is a necessary requirement to make this type of access control work. There are technical downsides behind this approach (which are discussed in the capability movement e.g.) but the social consequences are that we are more and more used to authenticate for all kinds of access. But in many cases a key (capability) based authorization would suffice and we would not be forced to always expose our identity.
I found a nice introduction to this type of thinking in the book on capability based computer systems by Henry M. Levy which can be downloaded freely. The book is no longer in print but shows nicely how far one has to go back to uncover different ways for authorization and access control.
| $Date: 2008/02/16 14:07:15 $ | Home | About... | Privacy... | Feedback |
Copyright © 2001-2015  Except where otherwise noted, content on this site is licensed under a Creative Commons Attribution 2.5 License by Walter Kriha. Except where otherwise noted, content on this site is licensed under a Creative Commons Attribution 2.5 License by Walter Kriha. | ||