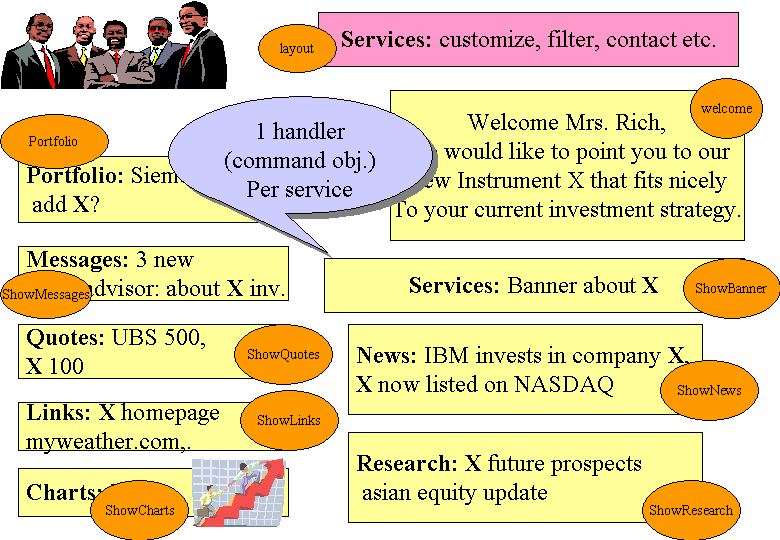
The homepage of AEPortal is called a "Multi-Page" because it combines several otherwise independent services on one page. Initially the internal processing of the homepage happened in the same way as for any other page: a handler running on a server thread (i.e. the thread that comes from the web container) collects the information and forwards the results to the view (via the controller).
It soon turned out that the AEPortal homepage had special requirements that were not easily met by the standard page processing:
Several external services needed to be contacted for one homepage request
Every additional homepage service added to the overall request time (= the sum of all individual processing times)
Rendering could not start until all services had finished. Frames were not allowed and therefore no partial rendering possible. Users did see nothing while waiting for the whole page to complete
In case of a service failure (e.g. news) not only individual page requests for news would block – almost every homepage would be affected too because news are a part of many personal homepage configurations
A simple page request blocking holds on to a small number of system resources. A homepage request blocking would hold on to a much larger number of system resources – potentially causing large drops in available memory. (Something we have observed during Garbage Collection debug)
While processing of multi-pages would have to be somewhat different there was a necessity to re-use the existing handlers and handler architecture because of tight deadlines. This lead to the following architecture:
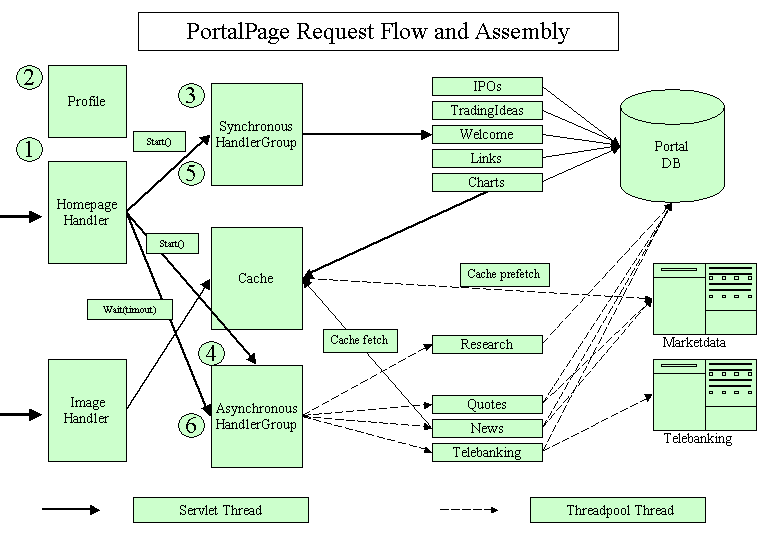
The processing steps 1 – 3 from above apply here as well. The homepage handler is a regular handler like any other.
Using the servlet thread, the controller forwards the incoming request to the homepage Handler.
Homepage handler reads profile information to select which services of the homepage need to run for this user (access rights are of course respected as well)
Every service has a page description in ControllerConfig.xml telling the system about the necessary access token, handler names and last but not least which data sources the service will use. Depending on the data sources (available are: AEPortalDB, OTHERDB, HTTP) the handler for this service will be put in one of two HandlerGroup objects: Handlers using only the AEPortalDB are put in the synchronous handler group. Handlers using HTTP sources end up in the asynchronous handler group.
Homepage handler calls start() on the asynchronous group first. It iterates over all available handlers and starts every one with a thread from the AEPortal threadpool.
The behavior of the threadpool needs to be checked. Will every new request be put into a large queue or will the requester block on adding to the queue if all threads are busy? This will affect system behavior on a loaded system.
Then homepage handler calls start() on the synchronous group. Again it iterates over all available handlers but uses its own thread (which is the servlet thread) to execute the handlers sequentially.
After executing all handlers in the synchronous group homepage handler calls wait(timeout) on the asynchronous group. The timeout is configurable (currently 30 seconds). When all handlers are finished OR the timeout has happened, homepage handler returns back to Controller.
The assumptions behind these two groups are as follows:
handlers in the synchronous group are both fast and reliable (because they only talk to the AEPortal database). They could run within their own threads as well but the overhead for the increased thread context switches are not worth the effort. We see execution times of less than one second for the whole synchronous group.
The reasons for handlers to go into the asynchronous group are more diverse. The first and obvious reason is that the handlers experience large waiting times on I/O because they access e.g. other web servers. By starting a request as soon as possible we can effectively run several in parallel. Doing so we avoid the overall homepage request time to be the sum of all single handler times. Tests have shown significant savings here. To achieve this effect the wait() method would not need a parameter timeout.
The timeout parameter is available because external services not only cause I/O waiting times but are also sometimes unreliable too. The assumption was that a full homepage request should not have to wait for a single handler simply because its associated external service is very slow or even unavailable. While this is a valid requirement the consequences of the timeout parameter are much more complicated than initially thought. This will be discussed below.
(Research, Telebanking and Charts are currently special cases. Research does NOT use HTTP access for the homepage part but is currently fairly slow and is therefore in the asynchronous group. This will change soon and it will move to the synchronous group. Telebanking is different in development and production and it is currently not clear how fast and reliable access to its external services will be in production. This is why it is in the asynchronous group even though its runtime in development is only around 50 ms. The charts part of the homepage is worth an extra paragraph below.
Charts looks like a service that would need an external service (External Data System) for its pictures – and it does so, just not within the charts homepage request.
The homepage request of charts uses the asynchronous requester capabilities of the AEPortal cache and simply requests certain pictures to be downloaded from External Data System (if not yet in the cache).
Charts Handler schedules the request synchronously but the request itself runs in its own thread in the background, taking a thread from the AEPortal threadpool.
The homepage only contains the URLs of the requested images. During rendering of the homepage the browser will request the images asynchronously by going through the AEPortal image handler.
The fact that charts causes a background thread to run is important in case of external system failure: what happens if the charts external service is down? Or under maintenance? Currently the background thread that is actually trying to download the image will get a timeout after a while and finish. In the meantime an image request from the browser will wait on the cache without a timeout. What happens in case of a failure? Will there be a null object in the cache? Anyway – the image request blocking without timeout is not such a big problem because it runs on a servlet thread and therefore blocks an entry channel into AEPortal at the same time – no danger of AEPortal getting overrun.
The background thread of the asynchronous requester is more dangerous because a failure in an external service can lead to all threads of the threadpool being allocated for the cache loader.
Threads should NOT die and if they do the threadpool needs to generate a new one.
Failure behavior needs to cover maintenance periods of external services too, especially the single point of failure we got through MADIS (news, quotes and charts all rely on MADIS)
Note: The image cache cannot get too large! Should the images be cached in the file system instead?
The processing of a multi-page request has the following RAS properties:
Additional threads are used. Handler uses server thread to start the threads. At least one thread must be available (possibly after waiting for it). A homepage request cannot work with a threadpool that does not have any threads and it cannot use the server thread instead (which would be equivalent to putting all necessary handlers into the synchronous group). There are no means to check for available threads in the threadpool.
The size of the threadpool is still an open question. Testing has shown that an average homepage request uses between two to four threads but his was before the introduction of the separate handler groups. In addition to this the asynchronous requester capability of the cache (see below) will need threads too.
It is still an open question whether the threadpool should have an upper limit. One of the problems associated with no upper limit is that currently the threadpool does not shrink – it only grows till the max. value is reached. The question of upper limits is much more difficult to answer for the case of timeouts being used (see below)
During the request the AEPortal database is contacted many times (e.g. for profile information) and parallel to this external services are accessed. There is no common transaction context between the handlers.
Processing is sequential as well as parallel: The best case would be if the runtime of the synchronous block is equal to the runtime of the asynchronous handler group (which is started first). Testing has shown that in many cases the external services are slower (by a factor of 2 – 5)
A single slow service leads to a considerable system load since the other handlers have already allocated a lot of memory.
If one of the handlers involved blocks the whole request coming from the web container is blocked. If the maximum number of open connections is reached, no new request can enter AEPortal WHILE the handler(s) are busy. This is also the case if one of the handlers in the asynchronous group blocks because the homepage handler itself will wait for the whole group to finish (in case of no timeout set)
No timeouts are specified for a handler. If timeouts happen they do so within the external service access API.
There is currently no external service access API that would offer a Quality-of-Service interface e.g. to set timeouts or inquire the status of a service.
The current policy for error messages is as follows: A failure in a service API should not make the JSP crash because of null pointers. The JSP on the other hand cannot create a specific and useful error message because it is not informed about service API problems. This is certainly something that needs to be fixed in a re-design.
Again, just like the in the case of a simple page request, let’s assume that an external service becomes unavailable. Eventually a handler waiting for this resource will get a timeout in the access API of that service and return with an error. This may take x seconds to become effective. (We need to know more about timeouts in our access APIs).
While waiting for the external resource ALL HOMEPAGE HANDLERS that belong to one request will hold on to some system resources. And so will ALL HOMEPAGE REQUESTS do which include this special handler. On top of that - three of the homepage services go to ONE external service (MADIS) and all external services are subject to change (hopefully with an early enough warning to AEPortal). This means that a blocked homepage request has a much bigger impact on system resources than a simple page request. Actually, without the ability to close down a specific service, any interface change in an external service could bring AEPortal down easily.
And since the homepage is at the same time the most important als well as the first service after login, a blocking service from the homepage is a critical condition that can quickly drain the system of its memory resources.
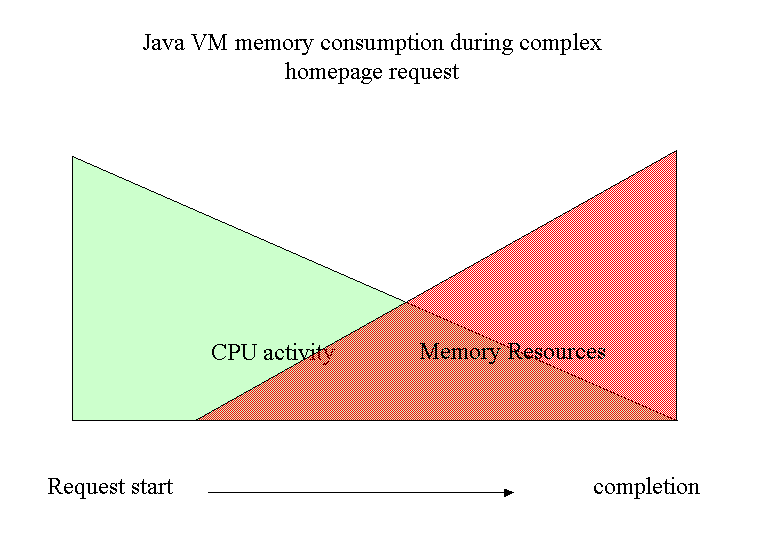
The good news: The request blocks an entry into the system (servlet engine) and prevents overrun.
The effects on the user are also different compared to a simple page request: If a simple request hangs the user can always go back to the homepage and chose a different service. This is not possible if the homepage hangs. We do not offer horizontal navigation yet (going from one service directly to any other service). That means that with a blocking homepage a user gets NOTHING. From an acceptance point of view a quick and reliable homepage is also a must.
The dire effects of a failure in a homepage service have led to the introduction of a timeout for waits on the asynchronous service group. The requirements and consequences of a timeout will be discussed next.
After the things said above it should be clear that the external services make AEPortal very vulnerable, especially the most important portal page. Before we dive into the implementation of timeouts a speciality of the Infrastructure architecture needs to be explained: the relation between handler, model and jsp.
Note: the "models" should really be result objects. The JSP should be a fairly simple render mechanism that can ALWAYS rely on result objects to be present – even in case of service API errors. Right now our JSPs are overloaded with error checking code.
Handlers create model objects. If a handler experiences a problem it can store an exception inside a model object and make it accessible for the jsp. But what happens during a multi-page request? The first thing to notice is that the Homepage jsp cannot expect to find a model object for every possible homepage handler. The user may not have the rights for a certain service or has perhaps de-configured it. In these cases the handlers do not run and therefore do not create model objects.
The introduction of a timeout while waiting for asynchronous handlers offers another chance for "no model". A handler blocks on an external service but the homepage handlers times out and returns to the controller and finally to the jsp. The handler did not create or store a model object yet. The only way around this problem is that the homepage handler gathers statistics about the handlers from the handlergroup and stores it in the Homepage-model. Now the jsp can learn about which handlers returned successfully and which ones didn’t.
The implementation of a timeout is simple: the homepage handler calls waitForAll(timeout) on the handler group and returns either because all handlers of the group signaled completion to the group or because of the timeout. The consequences are much more difficult. What happens to the handler that did not return on time? The answer is simple: Nothing. It is very important to understand that the thread running the handler is not killed. Killing a thread in Java is deprecated and for a good reason too. When a thread is killed all locks held by this thread are immediately released and if the thread was just doing a critical operation on some objects state, the object might be left in an inconsistent state.
This has an interesting effect on system resources: The homepage handler will return and after rendering the request will return back to the servlet engine and by doing so free an input connection into the engine – WHILE THERE IS STILL A THREAD RUNNING ON BEHALF OF THIS REQUEST WITHIN AEPortal. A new request can enter the system immediately, will probably hit the same problem in the handler that timed out in the previous request and return – again leaving a thread running within AEPortal. Of course, these threads will eventually time out on the service API and return to the pool but on a busy system it could easily happen that we run out of threads for new homepage requests (or even asynchronous requests on the cache)
Does it help to leave the upper bound of the threadpool open? Not really since requests could come in so fast that we would exhaust any reasonable number of threads. And remember – we can’t shrink this number afterwards.
Note: we have discussed an alternative: Wouldn’t it be better to crash the VM through an exploding threadpool? In this case the websphere system management would re-start the application server!
If we could prevent the new request from running the problematic handler we could avoid losing another thread. But this would require the functionality to disable and enable services.
Without being able to disable and enable services automatically (basically a problem detection algorithm) a timeout does not really make sense. It is even dangerous if set too low.
The handler threading mechanism was introduced at a time when many handlers used little or no caching at all. It could be expected that every handler in the asynchronous group would have to go out on the network and request data.
The membership in the asynchronous group therefore became a property of the handler – tagged onto the page description. While this is easily changed by a change to the configuration file it still presents a problem in case of advanced caching: If the data the handler has to collect is already in the cache, the handler will return almost immediately. This is a waste of computing resources because the overhead of thread scheduling is bigger than the time spent in the handler to return the CACHED data.
The homepage handler on the other side could not know in advance if e.g. the news handler will find the requested data in the cache or not. It needs to start the news handler in its own thread (per configuration) even if the news handler will run only 10 ms.
Why doesn’t the homepage Handler know which data the news handler will retrieve? Because there is no description of those data available! The only instances that know about certain model objects are handlers and their views. This makes caching and scheduling much harder.
What looks like a little nuisance hides a much bigger design flaw in the portal architecture: The architecture is procedure/request/transaction driven and not data/publishing driven:
Without running a handler no results ("models") come to exist
Only the code within a handler knows what data ("models") will be created and where they will stored (and how they will be called)
A page does not have a definition of its content – quite the opposite is true: a handler defines implicitly what a page really is. Example: the content of the homepage is defined as the set of handlers that need to run to create certain data ("models")
Handlers need to deal with caching issues directly and internally. No intermediate layer could deal with cached data because nobody besides each specific handler knows which data should/could be cached
The framework maps GET and POST request into one request type – negating the different semantics of both request types in http. There seem to be no rules within our team with respect to the use of GET or POST.
We have already seen some of the consequences of this approach with respect to caching and scheduling. But think about using the AEPortal engine behind a new access channel or just AEPortal light. Whoever wants to extract information through AEPortal needs to know about handlers and their internals (models). Instead of knowing about data and data fragments, clients need to call handlers. Again, this architecture is good for transactional purposes but it is disastrous for publishing purposes.
A few hints on a data-driven alternative:
The system retrieves the homepage description containing links to fragments.
The systems tries to retrieve the fragments from the caching layer, with the user context as a parameter
If the cache contains the item in the version needed (we have personalized data!) it is returned immediately.
If we have a cache miss, the proper requester turns around and gets a handler to retrieve the data (synchronously or asynchronously)
The items returned are assembled and forwarded to the proper view.
This means for clients that they do not know about system internals. All they need to know is the INFORMATION they want – not which handlers they have to call to retrieve an information set that hopefully contains all the data they need.
We will discuss this some more in the chapter on caching, when we meet the problem of document fragments.
For more information about this have a look at:
http://www.apache.org/turbine/pullmodel.html
Its focus is on GUI flexibility – UI designers cannot change the GUI without also changing the Java based handlers that create the result objects - but the reasoning also applies to caching and fragments.
The current handler design did not force developers to separate different use-cases into different handlers. A typical example is the authentication handler providing the rendering on behalf of the authentication front-end. Different requests all end up in one handler – only distinguished by different parameters. This has the following problems associated:
The fragment based architecture described below needs to separate the different requests into clearly distinguishable fragments.
The handlers need a more generic design allowing the configuration of e.g. a fragment handler by specifying the service needed etc. This is e.g. done in the Portlet approach (Apache Jetspeed)