Fragments are a concept independent of base technology assumptions like J2EE or Apaches Jetspeed etc. Fragments provide an information view on content and stay valid even if base technology changes.
Fragments are pieces of information that have an independent meaning and identity in the user’s conceptual model. This can be a piece of news or research or a single quote.
Fragments can contain other fragments or references to those.
Fragments have names and identities and can be associated (via a catalog) with a system identifier that allows the system to load or store a fragment through a specific service in a specific place.
Fragments can have one or more subjects associated. They can form a dependency chain of fragments. If fragments lower in the chain change, the higher fragments need to be re-validated or updated.
Fragments are the basic unit for caching.
Fragments can be persisted and have a read/write interface.
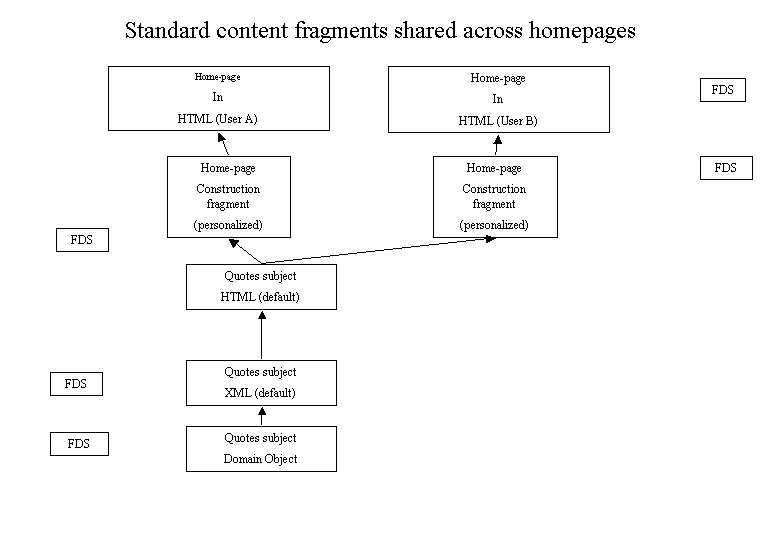
Fragments appear in various formats. An example:
The subject "news service" of the homepage includes several fragments in one fragment chain.
Html XML(pers) XML(common) Domain Object Database Row(s)
The difference between these fragments is that various transformation processes have been applied. A high-speed site needs to store fragments in various formats to avoid repeated and costly transformations. At the same time the site needs to guarantee the consistency of the subject e.g. the news block in the homepage by invalidating all fragments in the chain.
A single page as well as a homepage can be composite fragments. Composite Fragments are described by Fragment Definition Sets FDG (which are fragments as well that define what can/must go into a certain fragment. The composite fragment contains complete sub-fragments or references to other fragments).
The fragment definition sets form an object dependency graph (ODG). This graph is used to invalidate fragments and fragment chains. The real invalidation needs to be performed by going through the object dependency graph formed by the fragment instances themselves.
The lifetime of individual fragments can be very different and is defined either by the FDS or other rules.

Every Fragment can be referenced from various other fragments. As long as a fragment is only referenced, an update of this fragment will immediately become effective. Derived fragments still have to be updated too if they somehow embed the sub-fragments content.
Every Fragment has an associated Validator FV. This object will be contacted if a system component needs to find out if a certain fragment is still valid. If the answer is no, the fragment itself should be invalidated. In addition to this The fragment should know how to update itself – or at least contain all the meta-information or configuration information to make this possible.
The diagram below gives an overview of the information flow in a portal. The explanation starts as usual with an incoming request but there are certainly asynchronous information gathering processes active at the same time (read-ahead etc.)
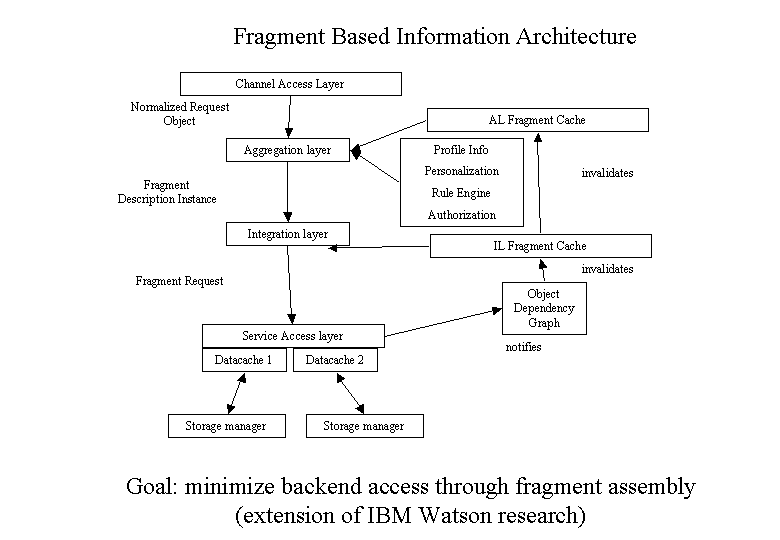
All incoming requests from various channel go through the channel access layer (CAL). This layer does a normalization of the requests by creating a platform independent request/response object pair.
The request object enters the aggregation layer (AL). It is the responsibility of this layer to map the request to a certain fragment (a page or parts of it).
The first responsibility of the AL layer is to create a validator for the requested fragment. Using this validator the layer can question cached information (e.g. a full-page rendered information cache) whether the fragment is cached and still valid. If the fragment is still valid, AL layer returns immediately.
Alternative: We could use Data Update Propagation (DUP) to notify caches about invalidation and avoid the validator concept at this level. Validators would then only be necessary if something changes and the scope of associated changes needs to be determined.
In case no suitable fragment was cached, a fragment definition instance for this user is then either created (contact the profile information) or retrieved from a cache (with write through) The fragment definition instance contains the fragment type information, filtered by the personal settings and authorization information:
User X requests fragment "homepage". The type definition for the fragment homepage defines that an instance of a homepage fragment can contain fragments of type "quotes" and "news". The access control subsystem and the user profile contains the information that both fragments are active (not minimized) and the "news" fragment has been personalized (topics, rows) while the quotes fragment is the default quotes information (no personal selections, no GUI changes like more rows etc.)
Please note: if the fragment definition instance has been cached too, then the aggregation layer saves the work to create a user specific fragment request!
Best-case scenario is of course if the fragments all exist in the cache and are valid. (Do they even exist if they are not valid?)
Please note: system information from catalogs map fragments to services. The fragment itself does not contain that information. Aggregation and Integration only deal with fragments, not with services (that will probably use something like a handler to retrieve fragments)