Table of Contents
- Caching
- The end-to-end dynamics of Web page retrievals
- Cache invalidation
- Information Architecture and Caching
- Client Side Caching
- Results and problems with client side caching
- Proxy Side Caching
- (Image) Caching and Encryption
- Server Side Caching: why, what, where and how much?
- Cache implementations
- Physical Architecture Problems: Clones and Cache Synchronization
- Portlets
- Fragments
- Pooling
- GUI design for speed
- Incremental page loading
- Information ordering
- The big table problem
- Throughput
- Asynchronous Processing
- Extreme Load Testing
A large-scale web application needs to apply an end-to-end view on how pages are created and served: client side and server side.
This covers issues like dynamic page creation, the structure of pages, compression and load-balancing issues and goes from http headers settings over colors and page structure right down into application architecture.
We will talk about the current settings for client side caching in our infrastructure shortly and then move on to server side caching.
The biggest problem in caching dynamic and personalized data is cache invalidation. Client side browser caches as well as intermediate proxy caches cannot be forced to invalidate an entry ON DEMAND. These caches either cache not at all or for a certain time only. The newer HTTP1.1 protocol also allows them to re-validate a fragment by going to the server – driven by cache-control settings for the page.
The result is that cache-control settings for browser and proxy caches need to be conservative.
Server side caches on the other side MUST HAVE AN INVALIDATION INTERFACE and possibly also validator objects that decide about when and if a certain fragment needs to be invalidated.
AEPortal being a personalized service our initial approach to client side caching was to simply turn it off completely.
private static String sExpiresValue = "0";
private static String sCacheControlValue = "no-cache, no-store, max-age=0, s-maxage=0, must-revalidate, proxy-revalidate"; // HTTP 1.1: do not cache nor store on proxy server. AKP
private static String sPragmaValue = "no-cache";
These values are currently set at the beginning of the service method of our controller servlet. They are the same for all pages. It would not be hard to make them page specific – driven by a tag in our ControllerConfig.xml. That’s what e.g. the struts package from Apache.org wants to do in the next release.
We do not use a "validator", e.g. LAST_MODIFIED which means that clients will not ask us to validate a request. Instead they will always pull down a fresh page.
We also do not use the servlet method getLastModified() which has the following use case:
It's a standard method from HttpServlet that a servlet can implement to return when its content last changed. Servers traditionally use this information to support "Conditional GET" requests that maximize the usefulness of browser caches. When a client requests a page they've seen before and have in the browser cache, the server can check the servlet's last modified time and (if the page hasn't changed from the version in the browser cache) the server can return an SC_NOT_MODIFIED response instead of sending the page again. See Chapter 3 of "Java Servlet Programming" for a detailed description of this process.
Jason Hunter, http://www.servlets.com/soapbox/freecache.html
A simple example that a personalized homepage need not exclude the use of client side caching:
If the decision to use the cached homepage can be based purely on the age of the homepage (e.g. 30 secs.) the getLastModified() would simply compare the creation time of the homepage (stored in session?) with the current time.
This would help in all those re-size cases (Netscape). It would also decrease system load during navigation (we don’t have a horizontal navigation yet).
Please note: We are talking the full, personalized homepage here. Further down in "client side caching" we will also take the homepage apart – following an idea of Markus-A.Meier.
First the controller servlet was changed to set the EXPIRES header and the MAX_AGE cache control value both to 20 seconds default per page. To enable the getLastModified() mechanism a validator (in our case LAST_MODIFIED) was set to the current time when a page was created. And getLastModified() returned currenttime-20000 by default. No explicit invalidation of pages was done.
Note: the controller servlet was modified in several ways:
It now implements the service method, overriding the one inherited from HttpServlet. I noticed that this is the method that seems to call getLastModified() – allowing us to distinguish the case where getLastModified() is called to set the modification time vs. it being called to test for expiration (see J.Hunter)
It is unclear if overriding the service() method is actually a no-no.
The servlet now also implements the destroy() method – even if it only logs an error message because right now we are not able to re-start the application (servlet) without a re-start of the application server. This is because we use static singletons. The destroy method should at least close the threadpool and the reference data manager.
It is unclear under which circumstances the websphere container would really call destroy(). Could our servlet and container experts please comment on this?
We did not set the MUST_VALIDATE header yet but some pages would probably benefit from doing so.
Problems:
the expiration time need not only depend on the page. Different users could possibly have a different QOS agreement for the same pages. Real-time quotes are a typical example. Either we use different pages for those customers (could force us to use many different pages) or we can specify an array of expiration times per page
After changing the homepage layout (myprofile), a stale homepage containing the old services was served once to the user. We need to use MUST-VALIDATE and a better handling of the getLastModified() method.
We don’t know if business will authorize an expiration time of 20 seconds for every service.
We don’t know how clients will use our site. (Our user interface and usability specialist Andy Binggeli has long since requested user acceptance tests) and therefore we must guess usage patterns, e.g. navigational patterns
Results:
Three out of four homepage requests for one user came from the local browser cache
Navigation between the homepage and single services was much quicker
Browsers treat the "re-load" button differently, e.g. Opera requests an uncached page when the re-load button is hit. Netscape needs a "shift + re-load" for this.
Javascript files seem to get no caching, at least within our test-environment. This would mean a major performance hit as some of them are around 60k big.
While client side caching will not affect our load tests (e.g. login, homepage, single-service, logout) regular work with AEPortal would benefit a lot.
A possible extension of the page element that covers the content lifecycle could be like this:
Example 5.1. Lifecycle definitions for cachable information objects
<!ELEMENT page (...,lifecycle ?,..) > < !ATTLIST page -- refer to a named lifecycle instance by idref (optional)-- lifeCycleRef idref #implied > < !ELEMENT lifecycle (#empty) > <!ATTLIST lifecycle -- allows to refer to a certain lifecycle definition name ID #implied -- after x milliseconds the user agent should invalidate the page. The system will assume a reasonable default if none given. A zero will tell the user agent to NOT cache at all -- expires CDATA #implied -- the user agent should ask server after expiration time -- askAfterExpiration (yes|no) yes -- the user agent should ALWAYS ask for validation -- askAlways (true|false) false -- the system will ask the given validator for validation during a getLastModified() request OR when a validator (LAST_MODIFIED or ETAG needs to be created. Allows pages to specialize this -- validator CDATA #implied > -- experimental: what to do in case the backend is down: -- useCachedOnError (y|n) n >
Note
The lifecycle element is an architectural element. It is intended to be used in different contexts e.g. pages, page fragments etc. Therefore a lifecycle instance can have a name that serves as an ID. Users of this instance can simply refer to it and "inherit" its values.
This does not prevent users from specifying their own lifecycle instance and STILL refer to another one. In this case the users own instance will override the one that was referred to.
AEPortal includes a number of static images that should be served from the reverse proxies. The same is true of our Javascript files.
Note: who in production will take care of that?
Further caching of information is a tricky topic because the information might be personalized. We do not allow proxy side caching right now. But for some information it might be OK to use the public cache-control header.
This chapter obviously needs a more careful treatment.
"Encryption consumes significant CPU cycles and should only be used for confidential information; many Web sites use encryption for nonessential information such as all the image files included in a Web page" (23).
Is there a way to exclude images from encryption within an SSL session?
Can we cache encrypted objects (e.g. charts images, navigation buttons, small gifs, navigation bars, logos etc.)? At least an expiration time and or validator would be necessary. What about Java Script?
BTW: I don’t think that the image handler (who writes the images directly to the servlet output stream) does set any cache-control values that would allow client and/or proxy side caching.
BTW: how does socket-keep-alive work?
Which services (fragments) really need to be encrypted?
AEPortal currently uses a caching infrastructure that allows various QOS, e.g. asynchronous requests. This infrastructure should be used for domain object caching needs. It can be found in the package comaepinfrastructure.caching. For caching in other layers the following chapters suggest some other techniques too.
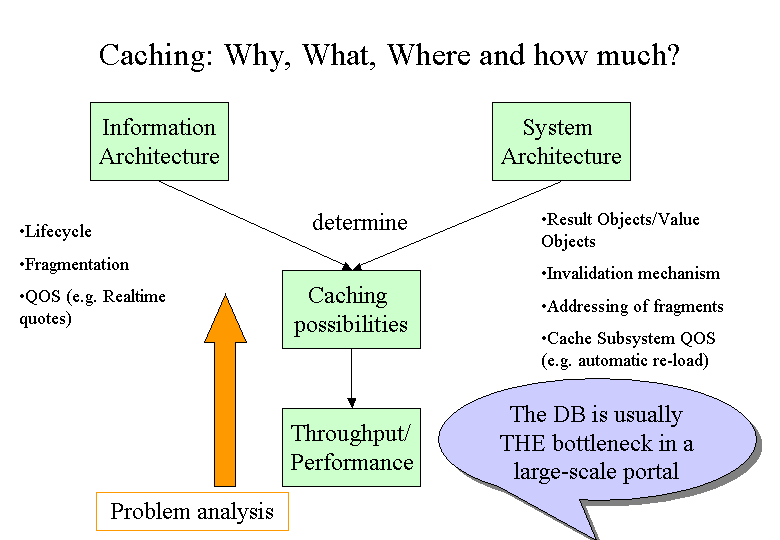
The reason for caching is quite simple: Throughput (and in some cases availability). In some cases – especially when dealing with personalized information - caching will speed up a single new but the effect may not be considered worth the effort – e.g. because the single user case is already fast enough. But on a large-scale site caching will allow us to serve a much larger number of requests concurrently.
This is the reason why in many projects caching gets introduced at a late stage (once the throughput problems are obvious). And it takes some arguing to convince everybody about its importance because it does not speed up a single personalized request as long as there is no clear distinction between global pieces, individual selections of global pieces and really individual pieces like e.g. a greeting.
Note: The possibilities for caching are restricted by the application architecture. Caching requires a decomposition of the information space along the dimensions time and personalization
The results from our load-tests are pretty clear: homepage requests are expensive. They allocate a lot of resources and suffer from expensive and unreliable access of external services. And last but not least we would like to avoid DOS attacks caused by simply pressing the re-load button of the browser.
Sometimes caching can also improve availability e.g. if a backend service is temporarily unavailable the system can still use cached data. This depends of course on the quality of the data and excludes things like quotes. The opensymphony oscache module provides a tag library that includes such a feature:
<cache:cache <% try Inside try block. <% // do regular processing here <% catch (Exception e) > // in case of a problem, use the cached version <cache:usecached /> <% > </cache:cache> see Resources, Opensymphony
Our original thinking here was that most of our content is NOT cacheable because it is dynamic. A closer inspection of our content revealed that a lot of it would actually be cacheable but this chance has either been neglected or even prohibited by architectural problems.
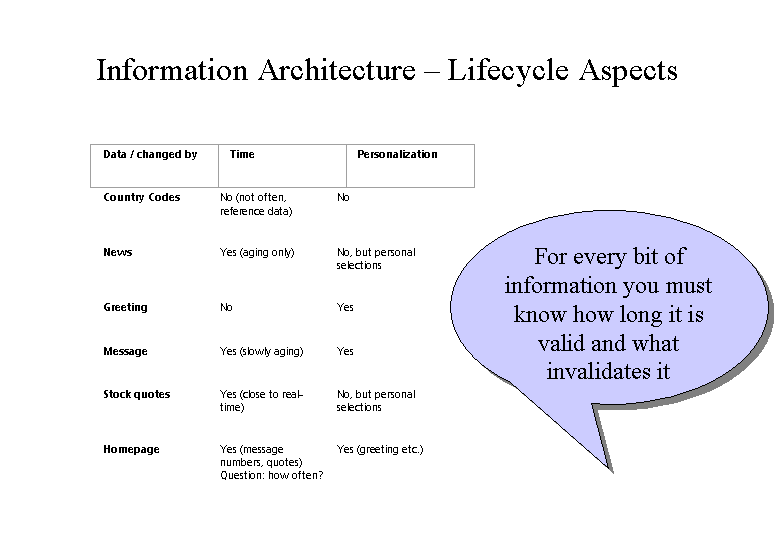
Let’s look at some types of information and their behavior in case of caching: The difficulties for caching algorithms increase from upper left to lower right.
Data / changed by | Time | Personalization |
Country Codes | No (not often, reference data) | No |
News | Yes (aging only) | No, but personal selections |
Greeting | No | Yes |
Message | Yes (slowly aging) | Yes |
Stock quotes | Yes (close to real-time) | No, but personal selections |
Homepage | Yes (message numbers, quotes) Question: how often? | Yes (greeting etc.) |
Country codes are reference data. They rarely change. In AEPortal there is a separate caching mechanism (described below) that deals with reference data only.
All other kinds of data are either changed by time or through personalization and require a different handling. The next best thing to reference data are data that change through time but are at least GLOBAL. Examples are news and quotes which should differ by person (This does not mean that everybody will get the same news)
A greeting (welcome message) does not change at all during a session but is highly personalized. This reduces the impact of caching but does not make it unnecessary for a large site. Reading the same message on every re-load from the DB does not cost a lot but with hundreds of users it is unnecessary overhead.
The homepage is a pretty difficult case. Our initial approach was to not use caching at all because the page was considered highly personalized and also contained near real-time data (quotes)
This was a mistake for the following reasons:
Page reloads forced by navigation or browser re-size would cause a complete rebuild of the homepage
According to a report from the yahoo-team (communications of the ACM, topic personalization) 80 % of all users do NOT customize their homepage. This would mean that besides the personal greeting everything else would be standard on the homepage
Even a very short delay for quotes data would save a lot of roundtrips to the backend service MADIS. Right now we are going for EVERY STANDARD quotes request (i.e. the user did not specify a personal quotes list) to the backend!
The homepage could be cached in parts too (see below: partial caching)
Let’s first draw a diagram of possible caching locations:
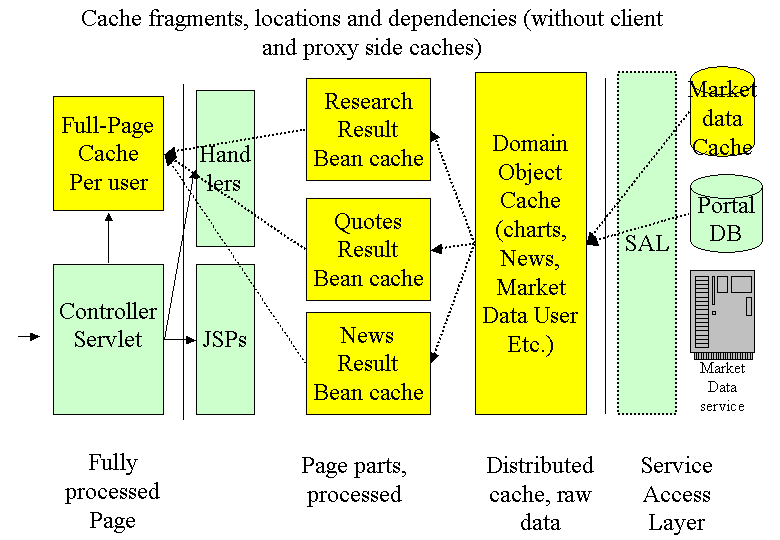
An example for full-page caching is taken again from servlets.com:
Server Caching is Better
The problem with this use of getLastModified() is that the cache lives on the client side, so the performance gain only occurs in the relatively rare case where a client hits Reload repeatedly. What we really want is a server-side cache so that a servlet's output can be saved and sent from cache to different clients as long as the servlet's getLastModified() method says the output hasn't changed.
The existing code for a full page server side cache from Oreilly could easily be extended to support caching of personalized pages. Page descriptions elements should get an additional qualifier to allow this kind of caching.
For a discussion of cache size see below (How Much?)
The full page caching approach suffers from a number of restrictions: While solving the re-load problem (caused by quick navigation or browser re-sizing) it forces us to keep a separate homepage per user. Also, the cache time will depend on the page part with the shortest aging time: we can’t store the homepage for a longer period of time. 30 seconds seems to be the limit. And: if many users do not change their settings or only a few, we keep many duplicates in those homepages.
These problems could be solved by using a partial caching strategy IN ADDITION or as a replacement for the full page cache.
Partial page caching see: http://www.opensymphony.com/oscache/
Dynamic content must often be executed in some form each request, but sometimes that content doesn't change every request. Caching the whole page does not help because parts of the page change every request. OSCache solves this problem by providing a means to cache sections of JSP pages.
Error Tolerance - If one error occurs somewhere on your dynamic page, chances are the whole page will be returned as an error, even if 95% of the page executed correctly. OSCache solves this problem by allowing you to serve the cached content in the event of an error, and then reporting the error appropriately.
Currently we have a problem providing partial caching: We don’t have the infrastructure to support it properly. Within AEPortal for every request a handler needs to run. This handler allocates resources and creates the result-beans (models). These models are not cacheable (they store references to request etc.). The homepage handler could be tweaked to supply cached model objects without running the respective handlers but this would be a kludge.
If we had this functionality we could assemble homepages from standard parts (not changed by personalization) and personalized parts that cannot be cached at all or a longer time. The standard and non-personalized parts would be updated asynchronously by the cache ( using the aging descriptions).
Again, if the 80% rule (yahoo) is correct, this approach would increase throughput enormously. In a first step we would probably cache only the non-personalized parts.
The Domain Object Cache already exists in AEPortal. It is currently used for pictures (charts), profiles and External Data SystemUser: a mixture of personalized and global data. This cache should actually be a distributed one (see below: cloning)
Last but not least the diagram shows a special cache DB for MADIS on the right side. Here we could cache and or automatically replicate frequently used MADIS data (or data from other slow or unreliable external services)
Results from Olympic game sites (Nagano etc.) indicate that navigation design has a major impact on site performance. The 98’ Nagano site had a fairly crowded homepage compared to previous sites. This was to avoid useless intermediate page requests and deep navigation paths (see Resources 6).
While the AEPortal homepage is already the place for most of the users interests the page structure could be improved in various ways according to Andy Binggeli. Some of his ideas are:
Separate the personal parts from default/standard parts. This is especially important for the welcome message. If the welcome message is the only personalized part in an otherwise unchanged homepage we could past the unchanged part easily from a cache.
Separate the quick database services from slow external access services. Flush every page part as soon as possible
The proposed changes would NOT require us to use frames. But we would have to give up the single large table layout approach and possibly create some horizontally layered tables.
A full-page cache that holds every page for every user for a whole session could become very large and pose a performance and stability problem for the Java VM.
Some quick guestimates:
A homepage has an average size of 30 kb. Let’s assume 500 concurrent sessions per VM. Just caching the homepage would cost us 15 Megabyte.
The partial caching of non-personalized homepage parts doesn’t cost a thing. For the personalized parts we would access the domain layer and not the cache.
Domain object cache: This cache holds currently pictures for the charts service (global), profile information (per user) etc. The size of this cache is hard to estimate.
Currently we do not know how big our cache can become on a very busy clone. Critical objects are images and other large entities. How do we prevent the cache from eating up all the memory? Should we store e.g. the charts images in the file system?
Domain Object Cache:
Creating a new object cache is simple: A new factory class needs to be created by deriving from the PrefetchCacheFactory and new requester class needs to derive from a request base class.
To allocate a resource from the cache a client either calls PrefetchCache.prefetch() or PrefetchCache.fetch().
Prefetch is intended for requesting the resource asynchronously (i.e. the client does not wait for the resource to be available in the cache). Fetch will – using the clients own thread – go out and get the requested resource synchronously. The client might block in that case.
Both methods will first do a lookup in the cache and check if the resource is already there. And both methods will put a new resource into the cache.
A quality of service interface allows clients to specify e.g. what should happen in case of a null reference being returned from the requester object (should it go into the cache? This could mean that subsequent requests will always retrieve the null reference from the cache instead of creating a new request that might return successfully)
Reference Data caching:
The package comaepinfrastructure.refdata contains the basic infrastructure for reference data handling. A reference data manager (initialized during boot) reads a XML configuration file that describes what data need to be cached and also defines the QOS (aging, reload etc.). A new reference data class can easily be created (probably in comaepAEPortal.refdata package) and a new definition added to RefdataConfigFile.xml
Note: There used to be different RefdataConfigFiles for production, test and development, due to the long load times initially. This has been fixed and there is no longer a real reason for separate configurations. Basically everything is loaded during boot.
We need to clean up the configuration files!
If you need more information on reference data – go and bugger Ralf and Dmitri!
An important part of a caching infrastructure is the quality of service it can provide to different types of data. Some data are only allowed a certain amount of time in the cache. Others should not be cached at all . Some should be pre-loaded, some can use lazy load techniques. Aging can be by relative or absolute time. The currently available QOS for reference data caching are described in the RefData dtd.
The current cache solution has three problems:
All of them are related to the peculiarities of the current physical architecture, especially the existence of several clones per machine and the lack of session binding per clone.
Note: Websphere 3.2.2 provides session affinity per clone
In effect this means that a session can use two or more clones on one machine. Since there is a cache per application or clone this in turn means that while one clone might have already cached a certain data – if the next request goes to a different clone on the same machine, its cache again has to load the requested data. Worst case, if we have n clones on a machine we can end up with loading the same data n times onto this machine. This fights the purpose of caching and puts unnecessary loads on network and database.
Besides being a performance issue this raises a much bigger problem: What happens with data that are not read-only? Unavoidable we will end up with the same data having different values in different caches. Currently we can only do two things about it:
Note: the 80% have not been tested yet!
User access tokens and profile entries are the most likely candidates to cause problems here.
Cache maintenance is impossible too because we have no way to contact the individual clones. If we could we could as well synchronize the caches in case of changes....
This has already hit us once: In case of a minor database change which requires the database to be shut down and restarted there is a chance that id’s have changed. Without recycling the clones they will have still the old values in the cache.
If we give up the idea of session affinity to ONE node – e.g. if we want to achieve a higher level of fail-over, then we have the same problem between ALL nodes!
Inter-clone communication is a very important topic for the re-design. Websphere needs to provide a mechanism here or cloning does not make sense in the longer run.
In this case a change to the database would be sprayed to all clones – possibly using a topic based publish/subscribe system and the clones would then update the data.
The Domain object cache on each clone or application instance would then need to subscribe for each cache entry to get notification of changes.
On top of solving the cache synchronization problem this would also give us a means to inform running application instances about all kinds of changes (configuration changes, new software, database updates etc.)
CARP (Cache Array Routing Protocol) could be used to connect the individual caches of all clones.
"CARP is a hashing mechanism which allows a cache to be added or removed from a cache array without relocating more than a single cache’s share of objects. [..] CARP calculates a hash not only for the keys referencing objects (e.g. URL’s) but also for the address of each cache. It then combines key hash values with each address hash value using bitwise XOR (exclusive OR). The primary owner for an object is the one resulting in the highest combined hash score." (15)
This solution would only provide a means to synchronize (actually, to avoid the synchronization problem) several caches.