Much of this document has already been dealing with performance and throughput issues. Here I would like to collect some more ideas from the AEPortal team on throughput or performance improvements
Certain Java styles will have a very strong negative impact on system throughput:
In the end it was necessary to walk through Jack Shirazis book on Java performance to fix the worst problems. It turned out that e.g. throwing and catching an exception is worth a couple of hundred lines of Java code or up to 400 ms.
DO NOT USE EXCEPTIONS IN PERFORMANCE CRITICAL SECTIONS – EVEN IF IT IS YOUR "STYLE"!
Excessive object creation and garbage collection can only be avoided using advanced caching and pooling strategies and last but not least interface designs which avoid useless copy’s – this goes deep into architecture.
The old saying: first get it going and optimize afterwards DOES NOT WORK HERE!
The latest garbage collectors work generational: they run through older data less frequently. This is very good for large caches which would otherwise cause a lot of GC activity.
Excessive synchronization is very common. To prevent the framework classes in the critical performance path are either singletons or have static methods.
Double-checked locking as a means to prevent multiple copies of a singleton and at the same time avoiding the performance penalty of using "synchronized" DOES NOT WORK. There seems to be NO workaround right now besides falling back to making the factory method synchronized or "eager initialization" (28).
The following is WRONG:
The parsing and or writing of XML documents or requests turned out to be quite expensive. The recently created weakness-analysis already suggested to replace the DOMParser with a SAXParser. While this would probably improve the performance and throughput, an even more powerful idea was suggested: generate specialized parsers for certain DTDs. This technique has been successfully applied in other projects [CMT99]. The specialized parsers are able to process the XML requests at nearly I/O speed (e.g. like the Expat parser by J.Clark) with minimum memory footprint.
Note:
When considering performance and scalability, the first concern with the DOM approach is the effect it has on system resources. Since DOM parsers load the entire XML document into memory, the implementation must have the physical memory available for this task. This requires the application to manage overflows as there's no real recourse for a document that's too large. Perhaps more important is how this limitation impacts the support for the number of documents that can be opened in parallel by the calling application. Since the DOM specification doesn't enable an implementation to process the document in sections, this request can add significant overhead to the processing of multiple documents. Furthermore, current parser implementations are not reentrant; that is, they can't allow multiple data sets to be mapped against a single DOM held in memory. The upfront resource costs of using the DOM approach are more than justified if the core function of the application is to substantially or repeatedly modify the content or the structure of the document. In this case working with the DOM allows efficient and reusable application calls that can interface directly with the XML document. Procedurally, if the calling application requires this level of access to the entire XML document or the ability to process different sections of the document, the use of the DOM API may be warranted.
SAX Approach
While a DOM parser reads the entire document into a tree structure before allowing any processing, an event-based parser allows the application to have a conversation with the XML document by communicating events in response to invoked methods by the application's implemented handler. Because of this conversational approach, the memory and initial processing requirements are lower for an application processing a document using SAX. This resource efficiency, though, requires the application to manage the various conversation handlers that are necessary to fully communicate with an XML document. Managing these handlers becomes the responsibility of the calling application. (from the XML Journal, http://www.sys-con.com/xml/archives/0203/patel/index.html)
A related problem is the mapping from XML elements to java classes (e.g. in External Data System). Class.forName("TagName") is VERY expensive within servlets. It uses the servlet classloader which is very costly.
This mechanism is used e.g. in MarketDataSelectorImpl, NewsDataSelectorImpl and ResultTagsImpl.
The same mechanism (but not for XML processing) is used extensively by the ProfileManager – another reason to get rid of this component.
Communication with External Data System uses XML messages while e.g. Telebanking uses the CORBA interface of External Data System.
The use of e.g. SOAP as a communication protocol underlying an rpc mechanism carries a performance degradation factor of 10 compared to Java RMI. See "Requirements for and Evaluation of RMI Protocols for Scientific Computing".
XML-RPC type communication is surprisingly fast for short messages. This shows that serialization/de-serialization is expensive, especially if an XML to object mapping is performed using Java reflection. Specialized "PullParsers" could improve the performance quite a bit as well as avoiding to convert too many XML elements into Java objects.
Does it pay to use a special parser for XML-rpc? From Graham Glass:
When my company decided to create a high performance SOAP engine, we started by examining the existing XML parsers to see which would best suit our needs. To our surprise, we found that the commercially available XML parsers were too slow to allow SOAP to perform as a practical replacement for technologies like CORBA and RMI. For example, parsing the SOAP message in Listing 1 took one popular XML parser about 2.7 milliseconds.
<SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/1999/XMLSchema-instance" xmlns:xsd="http://www.w3.org/1999/XMLSchema"> <SOAP-ENV:Body> <ns1:getRate xmlns:ns1="urn:demo1:exchange" SOAPENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/" <country1 xsi:type="xsd:string">USA</country1> <country2 xsi:type="xsd:string">japan</country2> </ns1:getRate> </SOAP-ENV:Body> </SOAP-ENV:Envelope><SOAP-ENV:Envelope xmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/1999/XMLSchema-instance" xmlns:xsd="http://www.w3.org/1999/XMLSchema"> <SOAP-ENV:Body> <ns1:getRate xmlns:ns1="urn:demo1:exchange" SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/" <country1 xsi:type="xsd:string">USA</country1> <country2 xsi:type="xsd:string">japan</country2> </ns1:getRate> </SOAP-ENV:Body> </SOAP-ENV:Envelope>
Since a round-trip RPC message requires both the request and the response to be parsed, using this popular parser would mean that a SOAP RPC call would generally take at least 5 milliseconds to process, and that doesn't include the network time or the processing time on either side. This doesn't sound too bad until you consider that a complete round-trip RPC message using RMI takes about 1 millisecond. So before giving up on ever building a SOAP engine that could compete against traditional technologies, we decided to experiment with building our own XML parser. (See http://www.themindelectric.com/products/download/download.html for how to download Electric XML, which developers may use without charge for most commercial and noncommercial uses.) XML compression is also discussed in the context of XML-RPC: According to Gerd Mueller (gerd@smb-tec.com ) the ozone/XML project uses "binary XML" to transfer XML from the clients to the database server and back through a socket connection. It is based on some work of Stefano Mazzocchi from Apache/Cocoon.
He called it 'XML compiler' and it compiles/compresses SAX events.
Our database is currently NO bottleneck – I wish it were!
Why is our database no bottleneck? Simply because we spend less than a second in our database driven services combined and several seconds in our services that access external sources like MADIS.
But once this problem is fixed THE DATABASE WILL BE OUR BIGGEST BOTTLENECK- confirmed by just about every paper on dynamic web content delivery (see Resources below).
And the reason for this is not bad DB design or large amounts of data transferred in single requests. It is simply the huge number of requests per personalized homepage or regular page driven against the DB.
I had a hard time to get everybody to recognize this. Especially if the amount of data in retrieved was considered to be small. Or the DB was used for filtering. This is true for regular stand-alone web applications. It does NOT apply for an enterprise portal that runs a lot of services in parallel just to satisfy ONE client request!
The golden rules:
If it changes only every once in a while – use the cache automatic reload feature to retrieve it
Don’t "abuse" the DB to get a convenient filtering mechanism – even so you could and should do so in a regular application.
If it’s personalized – still do cache it! The client might do re-loads.
It it’s small and personalized – put it in session state (e.g. greeting)
Connection Hold Time: given the fact that the number of connections to a DB is limited for each application server it is vital for the overall performance of the portal that requests do not hold on to a DB connection for longer periods of time.
The calls to getConnection() and freeConnection() have been instrumented to record the hold time. The architectural problem lies in the fact that proper system throughput depends on proper behaviour by the service developers and cannot be enforced by the system itself. Watch out for coding patterns that allocate the DB connection and then let it flow through nested sub-routine calls. This will typically result in overly long hold times.
The logging mechanism could be used to print warnings if a certain time limit is exceeded!
Currently we do not have framework support for selective and partial DB reads – e.g. caused by a user paging through documents. JDBC2.0 provides support for this. Some of it has been backported to JDBC1.0.
This is a hot topic within the servlet discussion groups.
Several packages are available that provide on the fly compression of http content (29, 17). Reductions in size of more than 90% are possible, reducing the download of e.g. the 50kb homepage substantially.
The basic requirement is that the browsers follow IETF ( Internet Engineering Task Force ) Content-Encoding standards by putting
"Accept-Encoding: gzip, compress"
in the http header.
Ideally compression should not happen at the application server. Reverse proxies seem to be a good place to perform compression without putting further load on the application server(s).
SSL processing puts a heavy load on systems. Not all systems are well equipped to do key processing at high speed (e.g. PCs outperform Sun Ultras by quite a margin).
Some numbers:
Depending on how many server requests are necessary to display a page the rendering time can grow from 5 seconds (http) to 40 seconds or more (https) (33).
A standard Web server can handle only 1% to 10% of its normal load when processing secure SSL sessions (34).
Note: KNOW YOUR PAGES! It is absolutely vital to know the structure of your pages and what it means in http-terms, e.g. how many individual requests are necessary to build a page.
Note: KNOW YOUR SSL PERFORMANCE! It is absolutely vital to have proper performance data on the throughput of your SSL processors (reverse proxies etc.). If the physical architecture seems to always get bigger and bigger here you can assume that the architecture is based on guesswork.
The authors of (30) suggest the following architecture:
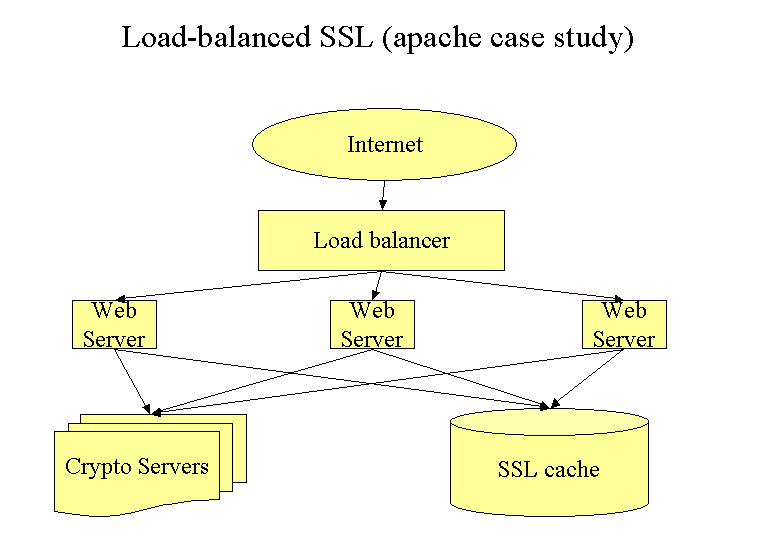
This architecture allows the sharing of SSL sessions e.g. for concurrent requests during embedded image load or generally to achieve a better load-balancing. Without a shared SSL cache (e.g. a shared memory session cache only) moving to a different web server would cause new SSL negotiations.
Note: Currently there are no performance data available. The portal physical architecture now includes SUN E4500 with 8 GB Ram and 6 CPU’s to perform authentication and SSL management. Also missing is the separation of static images from dynamically served content. Do the concurrent requests for embedded images have to go through SSL or not?
Using synchronized blocks for access to independently updated resources is very costly. The solution is to use Reader/Writer locks.
From Billy Newport (32):
"The reader writer locks have nothing to do with reading and writing actually. It is really a lock that splits parties that need access to the resource in to two groups. Anyone from the first group can concurrently access the resource. However, when someone from the second groups needs access, we block everyone in the first group until we get access. So, the second group has priority over the first group."
(37) suggests several ways to improve session performance:
Caveats:
Session sharing between servlets has consistency, classpath and performance problems (no multi-row capability, servlets do not have class files for objects from other servlets, servlets need to de-serialize many objects they don’t use. A multi-framed JSP cannot combine 2 Web Applications because they cannot read in the same session concurrently.??? Different web-applications used in one JSP break session affinity. When application server security is enabled, all resources need to be either secured or unsecured, no mix and match is possible.