Lessons learned from teaching Distributed Systems for 15 years
Introduction
The following lines are not intended as a history of distributed systems nor should they give a canonical view on how to teach the topic. They should should explain the forces that changed my lectures considerably and how this affected the way the lecture worked. If your are interested in historical aspects of DS, I have some diagrams in my intro lecture and I have added a whole session on "Services", as this seems to be a decades-spanning paradigm in DS. In the winter term of 2001/2 I started giving a course on distributed systems at the Stuttgart Media University HdM as an associate professor and in the summer term 2002 I started as a full professor. The Distributed Systems lecture (I will abbreviate it to DS from now) has always been kind of special for me, as it was my first lecture and also the one most tightly connected to my past in the industry. The last couple of years before becoming a professor I used to build large distributed frameworks, banking backbones and corporate portals - basically all distributed systems to various degrees.
Indeed, it was a talk on the scalability problems of large portals that made the university hire me. Without knowing it at the time, the performance and scalability problems found in large enterprise portals were a sign of what was to come a few years later with social media. But at that time many programmers were still rooted in the concepts of distributed objects as a programming model for distributed systems.
The first years: middleware and exercises
The first years teaching DS went without problems. The course was never mandatory but usually between 20 and 30 students decided to take it. The course consisted of lecture (2 hours) and exercises (4 hours) and for a newly assigned professor this is a good division of labor (:-). The theoretical base was rather slim: a few things like delivery guarantees and fallacies and off the students went to try out existing middleware. A few exercises at the beginning of the course made sure that everybody was familiar with socket programming and distributed objects. RMI turned out to be easy to use and an ideal candidate for testing the distributed waters. After those initial sessions groups of students decided on a specific middleware to bild a small demonstration project till the end of term. Some decided to stick with socket programming, some built something with RMI or some messaging middleware. Later, Enterprise Java Beans projects became popular.
In those years, the programming model used was an alias for distributed computing or distributed systems. Actually, the "systems" aspect was very small and the programming model aspect (interfaces, languages etc.) strong. I also had a CORBA session embedded in the lecture as many students still met this technology later in larger corporations. The CORBA frameworks became more complex and then OMG invented model-driven-architectures and model transformations and so on. It was not really so clear at that time, but most of the technology in distributed systems was for INHOUSE use only! And distributed inhouse applications were difficult without doubt, but they never had to face the problems of Internet applications or servers. And their developers never had to worry about those either. This actually was a big part of the problems behind corporate portals, where the distribution specific problems were largely underestimated.. Some peer-to-peer frameworks were popular as well (jxta from sun e.g.) but they were cumbersome to use when really used over the Internet.
Jim Waldo had raised an important issue during the development of RMI: How transparent can a distributed systems middleware really be? How much should it hide from developers? Despite Waldo's critique, EJB and application servers in general gave a clear answer to this: as much as possible. The programming model concept dominated the distributed systems concept clearly. But no ton of middleware is bringing Rome any closer to Munich!
Back then, the lecture really was intended to let students program distributed applications via the use of middleware. The development of middleware itself - or components of it - was not the goal and that explained the lack of theoretical background. Students learned about the problems in distributed systems often in their projects when they were confronted with some unexpected behavior. Such an approach would never do nowadays, but back then - when there were handbooks on DS from Tanenbaum or Dollimore which basically contained a rather static DS world - it was kind of OK.
The Web
A little later business moved to the web and suddenly the inhouse technologies showed their weaknesses. CORBA and RMI suffering from brittleness, performance and security problems and the mandatory use of firewalls killed them off anyway: they used ports other tha 80. EJBs with their stateful entity concept required distributed transactions to be consistent and that was something that nobody knew how to do in larger numbers! Meanwhile the services idea once behind CORBA reared its head again and WebServices were born, only to be followed by SOA. To me WebServices looked like a rewrite of CORBA in XML and quickly a huge tome of documentation was created and almost nobody used it. IBM and Microsoft were unable to convince others of the advantages - which were probably only visibly when you had the same corporate size...
WebServices gave up on the object illusion that distributed objects always insisted on. There were famous discussions on the distributed object mailing list which at that time had members like Werner Vogels (CTO Amazon and responsible for the services architecture of AWS) and Michi Henning). But WebServices made another mistake: The Web ain't not RPC system either. Roy Fielding had it right: create a stupid standard CRUD interface and let machines and people share documents. Don't worry too much about the content, humans will understand or fix it. REST began to dominate and it still does so especially when communication over the Internet happens. Inhouse, many services benefit from more RPC like solutions today so the race is still open.
Peer-to-Peer lost its shine when more and more services became centralized on large servers (and many P2P services never were serverless anyway, like Napster). Client/Server became once again the dominating distributed computing model and huge servers suddenly started hosting centralized services (and discovered new sources of income and client tie in).
Web2.0 and Social Media
This changed everything. At that time the faculty was writing a series on "computer science and media" and my job was to write something about distributed computing. My problem was, that I didn't want to write another blurb on DS without a connection to media (media were considered "soft" and not really fitting a decent computer science person. Typical stack fallacy of course). When I started to look at Social Media, I realized, that user generated content and user interaction on servers would make scalability paramount. And traditional distributed computing techniques faired badly in this discipline. Remember: Most developers came from intranet distributed projects where most of the famous eight distributed computing fallacies by Peter Deutsch did not happen so clearly. But now the server side of client/server paradigm had to scale in an unprecedented way. One Example: User generated content as e.g. in games requires many more writes than good old information distribution with its comfortable read/write ratio of 20 or more to one.
But scalability wasn't the only thing that changed. Content creation and distribution changed as well. As did business models with mashups etc. Even today new forms of collaborations are created frequently through the web and suddenly a computer science and media faculty was right at the center of technological change.Ultra-large-scale Systems
The rest cannot be told without telling about a new master course first: ULS. When I saw the massive requirements towards DS coming from social media applications and sites, I realized that this would change the DS technology considerably. Todd Hoff's wonderful portal highscalability.com gave me the input in form of reports from the leading architects on the scaling of their sites: Twitter, myspace, facebook and many many others. I noticed that the descriptions of architectures or technologies frequently were very dense and without a solid background in distributed systems hard to understand. The new master level course looked at those sites and started to explain the scalable technology behind. Very quickly it became clear, that scalabilty at the facebook level meant to take a new look at everything: business requirements, requests, monitoring and especially storage of those unbelievable amounts of pictures, text and soon video. And not only technology was affected: business requests had to be engineered to fit to SLAs and soon websites turned into request processing engines operating under the laws of queuing theory and hejinka. All "moral values" seemed to have disappeared: sites shut down single functions in case of overload (e.g. flicker at the christmas holiday overload). And worse: Consistency became "eventual" which in english does NOT mean perhaps but finally at some point in time. Re-evaluating everything in request processing led to decreasing constraints e.g. for transactions. The CAP theorem made it clear, that compromises had to be made and many sites found things that were not exactly transactional.
NOSQL was born and gave up on lots of dogmas from the RDBMS side - only to learn later on, that live gets sometimes rather hard without consistency and atomic transactions. But at that time scalabilty was paramount.
And suddenly I had a problem with the bachelor DS course: None of those things were part of this course. This meant that those concepts had to be introduced in the master level class as you go along. But over the time I became more and more uncomfortable with this division between bachelor and master. Suddenly, much more DS theory was needed to understand the distributed operating system that Google and others built. Paxos was no longer of only theoretical interest. You absolutely need a tightly replicated cluster to keep everything up and running consistently. And I felt that the bachelors would get shortchanged by keeping the scalability technology in the master only. They would need all this in small and mid-sized companies soon, because the mesh-up principle of todays web-business forced SMBs into the scalability rat-race too.
The Current DS Lecture
I decided to radically chance the DS lecture and add much of the scalabilty technology there. This required a complete re-build of the lecture. What should happen to things like EJB? Mostly obsolete, but a great learning example on technology and paradigms. Where should all the new theory go? When consistency becomes eventual, message ordering becomes very important. To scale, different combinations of processing and I/O handling are needed, with an emphasis on asynchronous tasks. Queuing theory and monitoring become very important. And finally failure models turn out to be the real basis of DS. So the new DS lecture sets out to teach distributed operating systems and how you build them. In other words: how to build the basics of a cloud system. No longer were distributed applications the goal. Several problems came up: There was no handbook with all that technology. I had tried to create one, but gave up after roughly 400 pages because it was clear that I could not keep up with the new things being added constantly: CRDTs as an example for a new way to look at datastructures and how they perform in an unrealiable network context. So much technology was missing: NOSQL needs a good understanding of ACID and consistency levels. High-speed messaging needs an understanding of concurrent non-blocking software like in Aaron or the LMAX disruptor (as does e.g. Memcached). I chose to integrate some concepts from Peter Bailis in the lecture and pushed other things like non-blocking concurrent algorithms in my lecture on concurrency and parallelism . Living from papers, blogs and portals, I created a lecture with mostly the new technology and its theoretical foundations (CAP, replication, Paxos, Causal order, time in DS and so on). I wish I had Martin Kleppmann's book at that time...
There were no more exercises or projects in this lecture. At least not exercises where students install and run stuff. There is no time for this anymore with only four hours left in the bachelor. What I do instead is paper and pencil exercises to get a concept across. An Example: I found a nice game which tested the understanding of eventually consistent API requests by looking at what kind of quality is needed for e.g. the referee, the news-reporter, the stadium speaker and the fan. The students who get by with the "cheapest" API calls while still meeting the requirements win. I am now a firm believer in paper and pencil experiments and exercises and think that they get the concept across much better than running some containerized storage system and try a few puts and gets.
Well, I noticed of course that this approach seems to run diametrically to other DS lectures. Cindy Sridharan (©construct) posted this observation.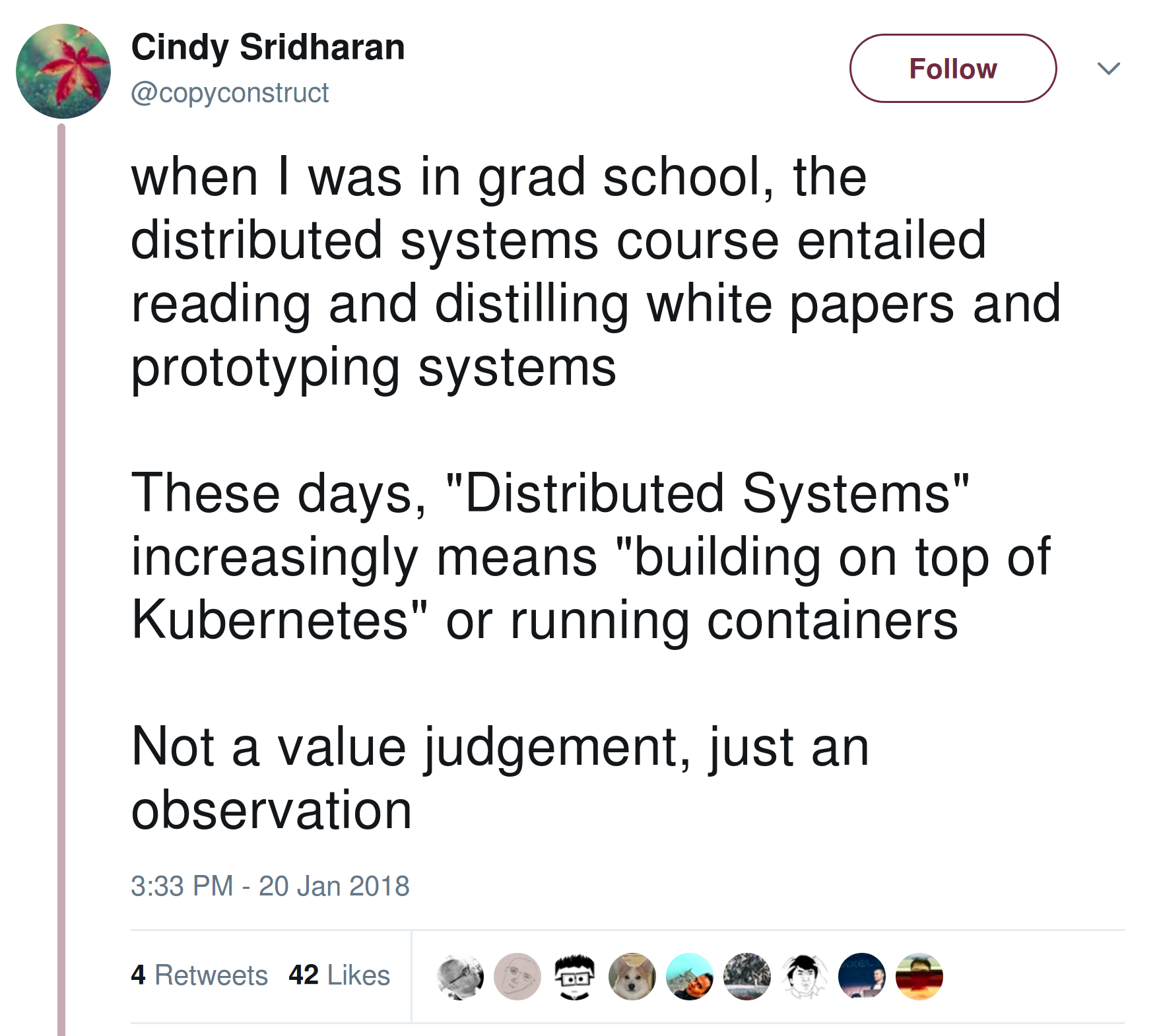 . After doing some innovation projects on containers, there were two things to learn: First, doing research on container technology is very cumbersome and takes resources a university typically does not have. Companies like Docker can raise much more funds to do this. And second, using containers to pre-pack DS tools and services and let students run those in exercises does zero for their understanding of distributed systems. In other words: containers, rump-kernels etc. are important, fast changing and stuff for DevOps courses.
. After doing some innovation projects on containers, there were two things to learn: First, doing research on container technology is very cumbersome and takes resources a university typically does not have. Companies like Docker can raise much more funds to do this. And second, using containers to pre-pack DS tools and services and let students run those in exercises does zero for their understanding of distributed systems. In other words: containers, rump-kernels etc. are important, fast changing and stuff for DevOps courses.
Is this now a dry, frontal lecture? I don't think so. It is certainly quite demanding because there is so much technology covered. The theory behind is kept at a necessary minimum but still, understanding consensus algorithms is not easy. The lecture is very interactive and lots of discussions happen. Many times, solutions are developed on the whiteboard step by step and with everybody involved. This is e.g. true for the concept of RPC, where we develop the software to call a c-function on a different host right at the white-board. So really no more exercises? In fact, the exercises have been pushed into other classes, e.g. on programming for the cloud or on systems engineering and management in the master level. The clear split serves both types of courses much better.
What is the most important thing students learn in my distributed systems course? Simply that there is no free lunch! Whenever you want to gain some performance or scalability by giving up on some constraints - there is a price to pay. Google e.g. is very careful in introducing "unconventional" APIs because application developers tend to have problems with those.
Final thoughts
So is everything perfect now? Of course not. The changes to the bachelor course should be small and just to keep up with the latest developments. And there are now good books available, e.g. the one by Martin Kleppmann, that give students more background information. It is the master course that creates problems now, especially for those without a foundation in new style distributed systems. I will have to tighten the pre-requisites for the master course, because some students lack too much background information. The good side is, that we can now concentrate much more on the latest developments (e.g. probabilistic algorithms or distributed deep and reinforcement learning frameworks) and design issues on the master level. What comes after scalability through distributed systems? I guess in the nexts couple of years reliability and availabilty in mission critical infrastructures will become very important, including security. And I just saw on infoq, that Werner Vogels did a talk on “21st Century [Cloud] Architectures”: Availability, Reliability and Resilience . The blockchain shows an increasing interest in peer-to-peer solutions and it is possible that p2p moves back out from large storage systems into the wild of the Internet. New ways of development will match the requirements of ultra-large-scale systems and new technology based on deep learning will become part of the distributed systems toolchain (optimized index access through a deep learning component was mentioned recently). Finally, the role of developers in a cloud-based world will change dramatically as Will Hamill pointed out in this quote: "If you’re implementing low-level configuration type work, or anything else now offered by an AWS service, you’re essentially now competing with Amazon...Unless you work for a company whose actual core business is in providing these kinds of platforms, then the bulk of your work should be done at higher levels. Look at PaaS over IaaS, evaluate Lambda seriously, prefer managed services by default. I’d go so far as to say that in most cases, Infrastructure as a Service isn’t for you, it’s for Amazon and Azure and Google’s own service teams to build stuff on top of. What you want is to then build on their offerings instead of duplicating them. If you don’t do it, your competitors will!"
Perhaps developers do no longer need to learn the basics of DS? Of how a distributed operating system works? After some more years of AWS everything distributed will be transparent to developers? Or is this simply repeating the mistakes from the early days of distributed systems and their promise of hiding the dirt behind wonderful programming models? And another thing: If Enterprise Java Beans have told us anything at all it was to realize that just pushing buttons and not understanding the consequences does not work. And understanding requires a look under the hood, even if later on tools will hide the worst from you.