Modeling Distributed Systems
Note
Please feel free to contact me in case you got practical ideas on how to solve this problem
The modeling of distributed systems in general, that includes subject based approaches like client/server systems as
well as de-coupled, event-driven systems is a yet unsolved problem. Let's start with a small example of an enterprise integration project which is supposed to link content management and search engine in a reliable way. 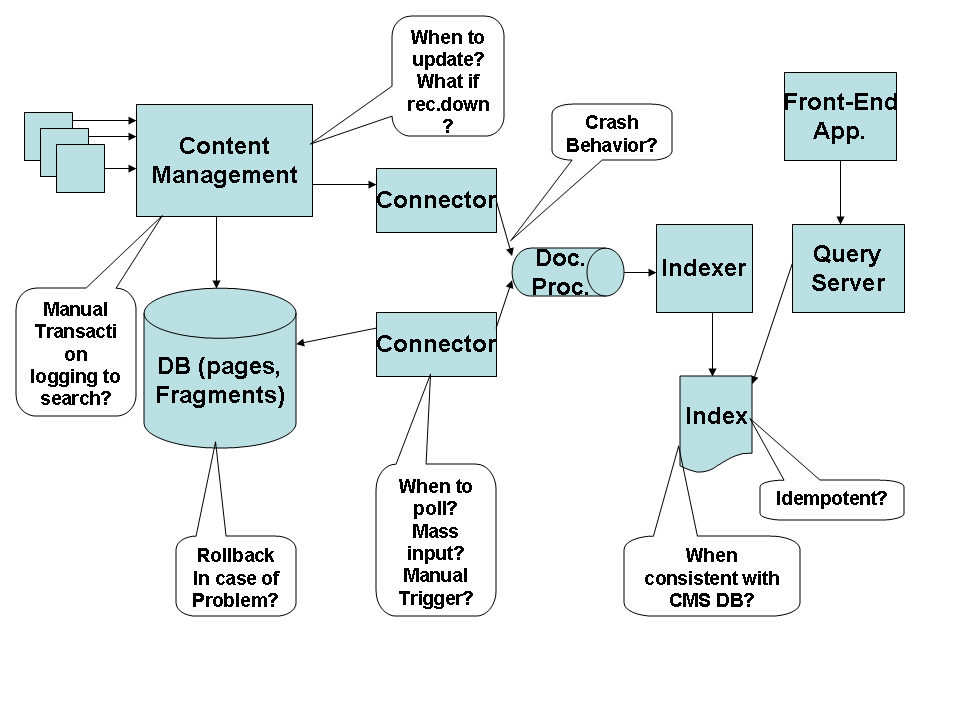 The diagram shows a few components or processes which try to extract document information from the CMS and enter it into the indexing process of the search platform. This is a rather simple example and it does not involve core enterprise transaction data like e.g. an e-banking application would.
The diagram shows a few components or processes which try to extract document information from the CMS and enter it into the indexing process of the search platform. This is a rather simple example and it does not involve core enterprise transaction data like e.g. an e-banking application would.
And yet, a number of surprisingly tricky questions pop up during the conceptual integration phase. But let's start with a description of the components and some requirements. The CMS component consists of a process which does the administration (e.g. publosishing tasks) and which uses a database to store all page and fragment data. The search engine component consists of several processes which extract, process and index document data. Interfacing between CMS and search is done using so called connectors: processes which can use JDBC calls against the database to extract document meta-data or processes which expose a push interface and let others push document content right into them. The connectors themselves are pusing documents or meta-data toward a document processing pipleine which will forward the processed documents to the indexing process.
So far so good. From previous experience it is known that indexing a complete CMS can take a couple of days if done through a web-crawler connector. Sometimes a CMS develops a problem and needs to fall back to a backup version e.g. 3 hours old. Sometimes new documents should show up in the index rather quickly, e.g. important financial news.
What kind of requirments are we facing here? The most important one is probably that documents within the CMS should be found through the search engine - not too long after they were published. Unpublished documents should NOT be found. We can add some additional security requirements by stating that access to documents and document-meta data through the search engine still needs to follow the original access control policies. In other words: you should not be able to find what you are not allowed to view.
The core requirement has one big problem: it mentions time as an additional constraint. And on top of this - time is specified rather losely: "soon", "sometimes quickly, sometimes not", "takes a long time".
But it gets worse. Neither of the connections in the system has yet been specified with respect to delivery guarantees. That leaves all kinds of questions open: What will happen if e.g. the push-update from the CMS cannot proceed because a connector is not running? Will this stop the CMS process itself? Will the update get thrown away? will the CMS keep book about a missed update and try it later again? When will that happen? Soon flags get introduced in the design and they only raise the next question: who resets a flag, e.g. when the indexer has successfully received a document? Will the search engine go straight to the CMS DB and reset the flag? Sureley not as this would create a very ugly form of tight coupling. But then how will the participating processes know that a document has finally been delivered? This calls for a distributed transaction but the costs of such a beast are prohibitive in many cases and most components in our diagram do not support them anyway.
Enter crash mode. What happens when the CMS gets corrupt? What happens when the index needs to be rebuilt? (this can happen not only in case of a crash but also when configuration parameters change). When the CMS DB is rolled back to an older version we see a funny side-effect: Search now offers documents which do not really exist yet. Those documents which have been published during the last three hours e.g. and which are now lost due to the rollback. When the index needs to be re-built (assuming a configuration change) the logic to do this should work like this: a) create the new index and then b) exchange it with the existing index. Why? Deleting the old index and creating the new one is logically the same. Yes, but building the new index takes three days and that makes the first solution so much better. Otherwise the company won't have a search capability for three days. This is simple and obvious but not so obvious that we did not try it the other way round first (;-).
Our little example soon exposes surprising complexity when errors etc. are introduced and we start forgetting about constraints and problems of our implementation. We would be better off if we could create a model for our solution. To do this we need a list of things that we would like to be put in a model and then we can think about how to express this and what to do with such a model. But before we do so we can already state what we don't need! We do not need a modeling language that is so formal that few people will understand it. Modeling distributed systems should be for the masses - because distributed systems nowadays are too. Model checking is nice but it should not be our first priority. Timo Kehrer suggested to build an ontology of things which are important in distributed systems. This could be a DSL, a UML profile, an ontology etc. What we also not need is kind of a connectivity diagram which includes port numbers, protocols etc. If those are important for a reason, the reason should be captured in our model, not the implementation.
- Constraints
-
We need to put the requirements from business and implementation into our model, otherwise we will forget about them. Later model-checking algorithms can validate our model.
- Time
-
That might be the hardest one to solve. We need constraints but we need them as time dependent. Most logics do not even include time. How would we express the state of the system in the rollback example form above? How do we express "soon should documents show up in the index?".
- Phases/states
-
The complexity increases a lot once different phases of our system are considered. This includes the bootstrap phase (who starts first? will a wrong startup order be fatal or will processes defensively try again to connect? Or are we using technologies that are rather independent of ordering problems? (which are probably a result of side-effects).
Can we use the state chart approach to map the phases of our distributed systems? Is this feasible?
The two connectors from above are only here for one reason: the initial load of the CMS content into search can be rather expensive in terms of processing time and bandwidth. So the initial load phase needs to be fast and lean and can later be switched over to the regular push phase when documents are published. But the transition between both phases gives headaches. Can they run in parallel for a while? What happens during regular runtime when a major crash happens? Can we repeat the initial load phase? Who triggers it? How autonomous are our processes?
- Delivery Qualities
-
Unreliable connections (should we just call them direct connections between partners?) are a major reason for the fragitlity of distributed systems. They just leave to many error scenarios open and the system complexity explodes.
What is the proper set of qualifiers to tag our connections?
- Qualities
-
Some of our components and processes expose certain qualities. It is e.g. very important to know whether the index server can handle duplicate documents or whether this will have a negative impact on performance or storage size. Other important qualities are e.g. the CMS ability to define a document and also define whether it should be indexed. Does the low level connector which uses JDBC calls directly to the DB know those rules?
- Availability
-
It would be very nice to have a set of tags to describe basic availability requirements, in our case e.g. the need for a two-locations solution.