What's New
- On Disruption
-
 Recently an alumnus who is now working on business strategies asked me about pointers towards literature on disruption, especially in the area of a joint banking/health business (no, this short piece is NOT about blockchain). After thinking for a while I was no longer sure that the question was clear to me. What do we mean when we look for "disruption"? Do we look for current business models to disrupt? Perhaps with a new combination of the latest technologies? Are we looking for emerging technologies which we can use to find new business models? Or are we looking for new forms of organisation which will cause disruption in those business which are unable to adapt? I - and probably many others - have been viewing the concept of disruption mostly from a technical viewpoint. But is this correct?
Recently an alumnus who is now working on business strategies asked me about pointers towards literature on disruption, especially in the area of a joint banking/health business (no, this short piece is NOT about blockchain). After thinking for a while I was no longer sure that the question was clear to me. What do we mean when we look for "disruption"? Do we look for current business models to disrupt? Perhaps with a new combination of the latest technologies? Are we looking for emerging technologies which we can use to find new business models? Or are we looking for new forms of organisation which will cause disruption in those business which are unable to adapt? I - and probably many others - have been viewing the concept of disruption mostly from a technical viewpoint. But is this correct?If I remember correctly, a nobel prize in economics has been handed out for somebody who had proved the power of organisational change over technical change. The organisational change described e.g. in Frederic Lalou's Re-inventing Organisations might have some disruptive power in itself as it can align differently with new technology. A nice current example of organisation and agility can be found in this paper on How we run bol.com . The role of social factors in creating disruption (or being unable to do so) is nicely described in Marie Hicks study on the role of women in the british computing industry. How to kill your Tech industry
The next question coming to mind is about the perspective with which one is looking at disruption: is it seen as a chance to bypass competition? Is it seen from a desperate perspective of a latecomer who does no longer see a justification of the current business models? Did somebody just say "banking"? Is the current situation of the world still the same as it was when Clayton Christensen wrote his famous book on disruption? I seriously doubt it. The 80s and 90s were still a time of slower changes compared to today. Companies get huge in a short time today - and sometimes disappear quickly also. Perhaps times have changed so much that the good old concept of disruption has lost its explanatory power? We need to reflect on the meaning of disruption today!
What gives me this idea? Well, it is probably caused by reading the new book by Noah Yuval Harari 21 lessions for the 21st century. This book is quite brutal as it shows the critical situation of the earth and the unbelievable changes in biotech, infotech and other areas waiting for us. And it shows that those topics are not yet properly reflected by the political class. Given the amount of change we are going to face in the next couple of years it could very well be that the quest to find disruptible business models turns into the quest for finding ANY job or business opportunity. Take this book as a kind of background lighting on everything you plan for the future. Harari is sometimes quite pessimistic (realistic?) and here is a little bit to support this pessimism: Survival of the Richest and from the World Economic Forum: Report: Machines to handle over half workplace tasks by 2025.
Another thing: I sure hope that a new disruptive business model in the area of banking and health does not follow this US life insurance company with its concept of a Interactive Life Insurance which really achieves new heights in self-optimization and social control. Potential disruptors should probably read Marc Uwe Kling, Qualityland for some ideas like an android for chancelor or TheShop delivering stuff to your house a) when you are there and b) without you even ordering anything - they just know what you want!
Disrupting business models includes always disrupting peoples lives. A good example for this can now be read in a book on the lessons learned with trying to open the UK Government. Opening the Amazon Marketplace for external vendors was supposedly the most contested decision in Amazon's history. Some more in this vein can be found on infoq.com e.g. Engineering Culture Revived. Some are rather critical too.
Finally something more practical: How do you proceed when you want to "break the mold" and get to new business models? I really liked the paper on Invisible Asymptotes by Eugene Wei. Look for an invisible ceiling in your current business. Something that is simply seen as a natural given, not something that might be overcome. Wei uses the example of Amazon prime. Shipping costs have always been a huge problem for online shops as customers just hate them. They understand that there is a cost associated with shipping that cannot be taken away miraculously. And they still hate them. With Prime Amazon was able to break through that ceiling and by now Prime is probably one of the most successful pillars of that company.
- On Causality, Knowledge and Big Data
-
 For the last year I have been pondering over several questions which seemed to be somehow connected. But I could not really find the reason why I thought they are connected nor could I find a solution for each one separately. After reading some more books lately (especially Judea Pearl's Book of Why and re-discovering Rolf Zieglers Korrelation und Kausalität" I think I might have found some answers. Here goes the story:
For the last year I have been pondering over several questions which seemed to be somehow connected. But I could not really find the reason why I thought they are connected nor could I find a solution for each one separately. After reading some more books lately (especially Judea Pearl's Book of Why and re-discovering Rolf Zieglers Korrelation und Kausalität" I think I might have found some answers. Here goes the story: There is no causality states Sean Carroll in his compact overview of current scientific theories. The state of the universe at t+1 is completely determined by the state at t (well, accepting some quantum level uncertaincies of course). And all physical laws work the same way forwards and backwards. Time goes by only due to entropy.
Ok, so causality is a human invention but a quite useful one I might say. Our daily life is full of causal statements, even though science has discovered that we are making causal reasoning up sometimes. Something in us seems to force us towards causal knowledge and I guess that this something is close to what Kahneman calls "System One". The lower level system in our brain that explains the world to us in realtime - albeit not always correctly. But how "scientific" is causality as a concept? Here comes in handy the book by Judea Pearl. Recommended by my colleague Johannes Maucher - the machine learning expert at our university - I immediately ordered it and started reading it. He claims that we can draw causal knowledge from data, but be need a theory and a model to do so. I already had his previous book "causality" on my bookshelf and I knew parts of his "causation ladder" already. E.g. that you have to "wiggle" a factor while keeping other factors stable to detect a causal influence. The first level of the causation ladder ist mere association or "seeing". This is where correlations are detected by statistical methods. The next layer is intervention (the "wiggling") and the final layer is counter-factual thinking: Calculating with causal results of things that did not really happen. Pearl says that human thinking works exactly on those higher layers and current AI methods are unable to work on those layers yet. (For a sound critique of the state of "human imitating AI" see Michael Jordan's Artificial Intelligence - the Revolution has not happened yet. He confirms Pearl's critique and develops a very interesting concept of "human centered engineering - a topic for another time)
Some Big data experts are opposing this view. They claim that causality is anyway not a useful scientific concept and that all that is needed is associations/correlations to draw conclusions. And nowadays the amount of available data is so huge that no models or theories are needed to draw knowledge from them. The data "speak for themselves". This statement from the big data community has baffled me for quite some time - for a reason that you will understand shortly. Pearl deconstructs this claim successfully in his book and shows the value of causal diagrams and models to achieve better knowledge from data. He shows the struggle in the statistical community to work around the missing concept of causality. The book is nicely written and does a very good job to explain causality. But it wasn't the huge eye-opener that e.g. the Kahneman book had been for me. After reading the book I went to my bookshelf and found something in the statistics section, that explained some things to me: I found "Korrelation und Kausalität" by Hummel/Ziegler. A series of three books on the topic of causality and when I went through the list of contents I knew why Pearl's book wasn't such a big surprise for me and why I had troubles understanding the claim of "big data speak for themselves". Rolf Ziegler had been my professor for empirical sociology at the LMU Munich, together with Siegfried Lamnek. And when I saw the articles they had collected I realized that they were following Wright's ideas just like Judea Pearl did. And I saw causal path diagrams and models and started to remember, that we had talked about causal influences of social factors - but always in the context of a theory or a model. And I understood that the problem of correlating everything with everything else raises not only the problem of spurious results. It is actually much worse: You might find correlations, but you don't learning anything about causal relations and without theory you don't have an explicit interpretation of what you have found at all.
So it turned out that I had studied empirical socal sciences right at a university which followed the same principles as Judea Pearl. I had found another trace of causality thinking from the initial ideas of Wright and Brook to my university in Munich.
Coming back to machine learning and AI: Pearl says that we need to teach machines causal thinking before we can interact reasonably with e.g. robots. And as far as I know they are trying exactly that at the University of Tübingen.
At the end the open questions from the beginning were really all tightly related. I didn't get an answer on everything: there is still the unsolved problem of no causality (or complete determinism) on the physical side and the usage of causation in our life which simply demands something like a free will and optional paths. It does not make sense to reason about counterfactuals in a completely deterministic world.
Once causal reasoning with data is accepted, the question turns to the concrete ways this can be done and finally, automated. To do this we need a mathematical form of causal reasoning and some algorithmic rules to apply to data. Pearl gives both in his book. He starts with the basic visual forms of causal reasoning: chains, forks and colliders, all visualized with causal graphs (DAGs with a scalar attached which denotes the impact of effect variables by cause variables. I found a nice essay by Adam Kelleher on medium. A technical primer on causality gives nice explanations on how to treat data according to those base forms of causal effects.
 I really liked his Python demonstrations about confounders. Kelleher finishes the short paper with a warning: the problem is in building the correct causal graph! And he distinguishes different interests regarding data analysis: The social sciences have a "beta" problem - they are interested in the effects of variables on social developments. Machine learning has a "y-hat" problem - they are interested in improving predictions, not so much in explaining developments. I guess that points again at the initial statement about "data speaking for themselves" vs. using a model to explain developments.
I really liked his Python demonstrations about confounders. Kelleher finishes the short paper with a warning: the problem is in building the correct causal graph! And he distinguishes different interests regarding data analysis: The social sciences have a "beta" problem - they are interested in the effects of variables on social developments. Machine learning has a "y-hat" problem - they are interested in improving predictions, not so much in explaining developments. I guess that points again at the initial statement about "data speaking for themselves" vs. using a model to explain developments.
After reading about causation, data and techniques for causal reasoning I would like to learn something about how causal reasoning works in human beings. Perhaps this can give us a clue about doing the same in machine learning.
- On language, culture and cognition
-
 (Hopi image: Edward S. Curtis [Public domain], via Wikimedia Commons) I remember reading Benjamin Lee Whorf's famous book on language, thinking and perception of reality and being quite impressed about his discoveries in the Hopi language and culture. Later his methods were seriously questioned and rejected. But in my mind his theory on how the structure of our language influences our thinking prevailed. Now, Lera Boroditsky wrote How Does Our Language Shape The Way We Think. And it looks like things have changed a bit.
(Hopi image: Edward S. Curtis [Public domain], via Wikimedia Commons) I remember reading Benjamin Lee Whorf's famous book on language, thinking and perception of reality and being quite impressed about his discoveries in the Hopi language and culture. Later his methods were seriously questioned and rejected. But in my mind his theory on how the structure of our language influences our thinking prevailed. Now, Lera Boroditsky wrote How Does Our Language Shape The Way We Think. And it looks like things have changed a bit.Will you be more perceptive to different colors of snow when your language has more words for different kinds of white? Theories which claimed this connection had been rejected for many years and to me the whole thing looked like it could not be proved anyway empirically. But Lera Boroditsky invented several clever tests to show that language does influence other cognitive abilities. One example was the way Aborigines performed orientation tasks. Instead of using relative coordinates (right/left) they use absolute coordinates (north/south) and a simple distance metric. Ordering a sequence of events on a timeline is always done east-to-west, no matter how a person sits. This requires a constant awareness of the absolute position and Boroditsky was able to show that this leads to superior navigational abilities in Aborigines. But these abilities are NOT genetically determined. People from other cultures can learn the same system and by doing so, also acquire the associated capabilities.
Does this affect computer science? I think it does. Languages play a big role in CS. Object-orientation is an exercise in categorization and every developer should have read Lakoff's "Women, fire and dangeous things" to understand that there is no "right" categorization anyway. But did you ever notice how similiar we software developers seem to think across cultural, sex or age differences? Just talk e.g. to a chemical engineer and you well notice a substantial difference in how they see e.g. the need for categories or the way they differentiate synthesis from analytics. Could this be a result of learning computer languages? Do we acuire an algorithmic view on life by learning C or Java? Or is it the other way round: we have an algorithmic view on life and therefore learn programming languages?
But that is not all. How important are grammatical things like the association of gender and nouns, which are usually considered as arbitrary selections? Not so, according to Boroditsky. When a noun is in a certain gender group, it seems to acquire properties of other nouns in that group. (I think I read in the Lakoff book, that this is not really the case with women, fire, dangerous things...). How do these discoveries affect gender conflicts about male-only terms for professions? I always considered those fights as futile, but perhaps I was wrong.
Finally, the good news: when we learn a new language, we seem to acquire also the special abilities encoded in the structure of those languages. Learning to differentiate snow better is perhaps not so important for most people, but getting a better functional understanding by learning a functional language might be quite useful.
- Re-inventing the University?
-
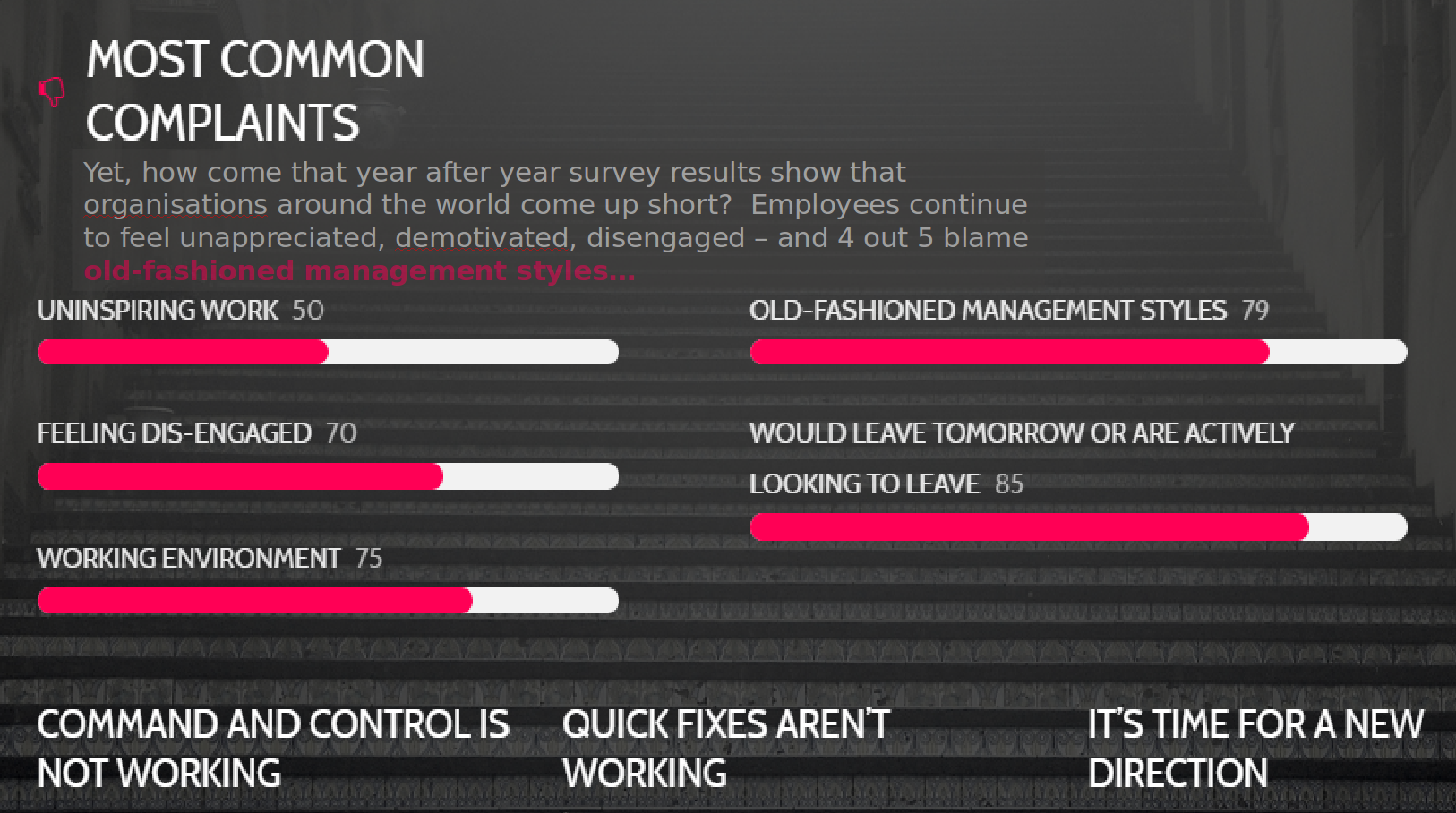 The diagram from Miriam Gilbert from Coincidencity gets right to the core of organizations: bad feelings everywhere! But is this true? Aren't companies like Netflix or Spotify leaders in corporate culture? Isn't change now everywhere, e.g. within Siemens (link to interaction day), caused by Digitalization pressure? Or is it just state-authorities suffering from deficits? As the book from Frederic Laloux is already the second one on organizations this term and being responsible for the development of a corporate culture document for the University, it is about time to write down some experiences made during the last term. A big thank you to my colleague Oliver Kretzschmar who recommended the book to me. Embarrassingly it turned out that lots of colleagues had already read it. Here is the document: Update University which is not final yet.
The diagram from Miriam Gilbert from Coincidencity gets right to the core of organizations: bad feelings everywhere! But is this true? Aren't companies like Netflix or Spotify leaders in corporate culture? Isn't change now everywhere, e.g. within Siemens (link to interaction day), caused by Digitalization pressure? Or is it just state-authorities suffering from deficits? As the book from Frederic Laloux is already the second one on organizations this term and being responsible for the development of a corporate culture document for the University, it is about time to write down some experiences made during the last term. A big thank you to my colleague Oliver Kretzschmar who recommended the book to me. Embarrassingly it turned out that lots of colleagues had already read it. Here is the document: Update University which is not final yet. - 19th Gamesday at HdM - more than just fun, more....
-
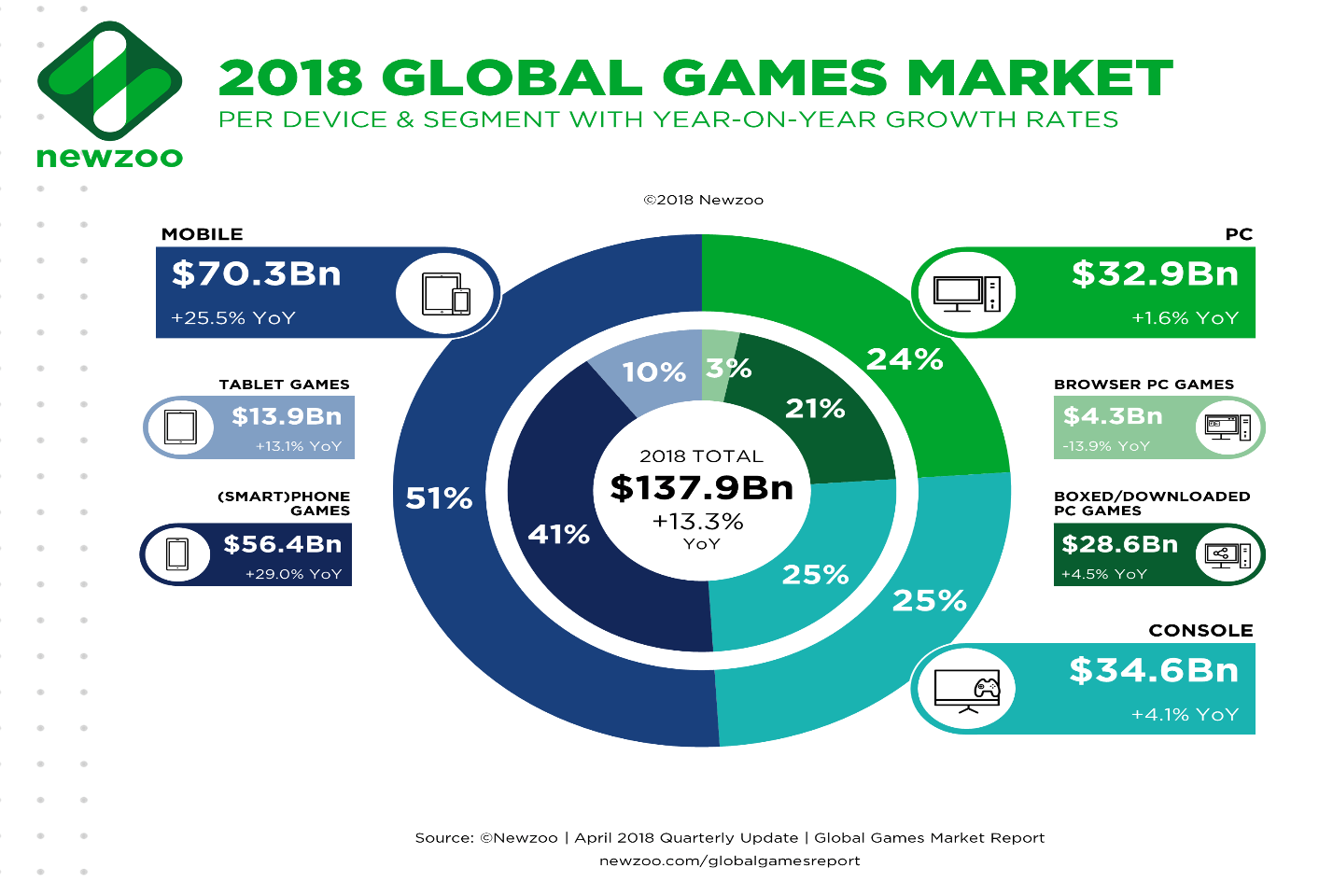 Game development is much more than design, arts and fun. It is about platforms, publishing, marketing and last but not least money as you can see. A few more numbers I just found at highscalability.com .
Game development is much more than design, arts and fun. It is about platforms, publishing, marketing and last but not least money as you can see. A few more numbers I just found at highscalability.com .138 Billion: global games market $50 billion: 2017 Angry Birds revenue; $296 million: Fortnite April revenue;
That is why our Gamesday has its focus on publishing, platforms and marketing, especially for Indie-Developers. How do I create my own game? How does publishing work? What channels are available? We will start with an unbelievable amount of money spent on eSports: Companies spend beyond 100 mio. dollars per year on player profits. (Which is not really such a surprise given the numbers above, but still..). StarCraft II, Dota 2,League of Legends, Counter-Strike: Global Offensive etc. - the prices handed out in big tournaments are substantial. Time to take a closer look. Mike Fischer will start with an overview and will then concentrate on the importance of eSports incl. non-competitive streaming for the games industry. Game platforms are of core importance for game developers. And it does not have to be Steam all the time, as Daniel Rottinger will explain in the second talk. He studies PR at HDM and is part of a developer collective "How to Dev a Morgue" which published its first game recently. It got an honorable mention in PC Gamer. And while we are at it: Why not publish for the game console world? Is it to difficult/expensive or unfit for Indies? Benedict Braitsch studies online media management at HdM and is a co-founder of Strictly Limited Games. he will give an overview of what is needed to publish on game consoles. Before everybody will run away to start their own game development, Danny Fearn and the game-dev team of HdM will show their milestone of "Mayhem Heroes". Certainly something to look forward to! Last but not least a well known face from past Gamedays will have an appearance: Andy Stiegler works now as a Creative Technologist at Strichpunkt Design and he will tell us what a techie is doing at an agency and where to find game technology outside of games. Why are designers interested in game loops and ray tracing? He will finish with a few insights from the last GDC. Agenda: Wann und Wo? am 15.6.2016 um 14.15 im Audimax 011, Nobelstrasse 10, Stuttgart. Wie immer wird der Event aufgezeichnet und kann unter https://events.mi.hdm-stuttgart.de verfolgt werden. Ein chat für Fragen aus dem Internet ist ebenfalls verfügbar. Der Event ist kostenlos und offen für Interessierte aus der Industrie und Akademie sowie für Privatleute.
14.15 Welcome, Prof. Walter Kriha 14.20 "eSports - Neuer Marketingkanal für Spielemacher?" , Mike Fischer, HdM VS 14.50 „Indie-Publishing: itch.io als (gute) Alternative zu Steam?“, Daniel Rottinger , HdM Studiengang PR und Indie-Team How to Dev a Morgue 15.25 Pause 15.30 "Indie-Publishing auf Konsolen: Just do it!", Benedict Braitsch, HdM Studiengang OMM und Strictly Limited Games 16.00 "Mayhem Heroes" - Präsentation zum Milestone vom Games Praktikum HdM, Danny Fearn und Team 16.30 Pause 16.40 "Game Dev beyond Gaming", Andy Stiegler, Creative Technologist, Strichpunkt Design Any questions? mail to: kriha@hdm-stuttgart.de - Physics fooled by (mathematical) beauty - is this true for software development as well?
Well, obviously software development is not fooled by the beauty of its mathematical models. Todd Hoff gave this quote from a book on physics: “Can the same be said for software development? Dan Falk: In a new book entitled "Lost in Math: How Beauty Leads Physics Astray," Hossenfelder argues that many physicists working today have been led astray by mathematics — seduced by equations that might be "beautiful" or "elegant" but which lack obvious connection to the real world.” The reason why this effect does not show in software development is quite easy: we never tested our assumptions/models etc. on how to develop in an empirical way. The few "laws" we have detected are based on experiments which were so small or skewed that any empirical researcher would never accept any conclusions from them. I've learned this from watching Peter Norvig: As we may program: the future of programming and computer science.
I do believe that we are fooled by beautiful and good sounding concepts or paradigms (functional, OO, UML, you name it). We just don't even think about empirically verifying them.
- Shlor's algorithm and the current state of quantum computing
I have to admit that last years event on quantum computing at HdM left me kind of puzzled about those machines. After dealing with Elliptic Curve Cryptography and Homomporphic Computing in this terms journal club, we ended up wondering about the robustness of trapdoor functions using factorization of natural numbers or discrete logarithms in modulo operations. And after Shlor's algorithm has been discussed in the morning paper, we decided to take a stab at it. The discussion in morning paper and the original paper by Shlor Polynomial time algorithms for prime factorization and discrete logarithms on quantum computers .
Well, the original paper is REALLY hard to read. But Shor, I’ll do it by Scott Aaronson helps a lot.
So do several videos by Robert Smith in the computerphile series on youtube like The current state of quantum computing or especially Quantum computing instruction set.
Let's start with prime factorization. Shlor's algorithm basically transforms the problem of finding the right value in a possible huge sequence into finding a period in a large sequence.
 This is called a Quantum Fourier Transform and the problem is to find the right period. The trick is to specify the solution in a way that allows the quantum computer to create the proper probabilities when you extract the result. In the QFT case this happens because the period contained in the sequence leads to one amplitude getting stronger and stronger (longer) with each sequence while the other amplitudes cancel themselves out
This is called a Quantum Fourier Transform and the problem is to find the right period. The trick is to specify the solution in a way that allows the quantum computer to create the proper probabilities when you extract the result. In the QFT case this happens because the period contained in the sequence leads to one amplitude getting stronger and stronger (longer) with each sequence while the other amplitudes cancel themselves out  . In trying to understand how this could really work a few important things about quantum computing became a little clearer to me: The problem needs to be transformed into something that a QC can do very fast. The solution must be a GLOBAL property of the probabilities contained in qbits. Some comments from Robert Smith of Rigetti Computing helped some more: The QC is more a coprocessor or GPU than a reglular CPU. It feels more analog sometimes than digital: It can perform a huge matrix multiplication of the probabilities in each qubit with the column vector across all qubits see:
. In trying to understand how this could really work a few important things about quantum computing became a little clearer to me: The problem needs to be transformed into something that a QC can do very fast. The solution must be a GLOBAL property of the probabilities contained in qbits. Some comments from Robert Smith of Rigetti Computing helped some more: The QC is more a coprocessor or GPU than a reglular CPU. It feels more analog sometimes than digital: It can perform a huge matrix multiplication of the probabilities in each qubit with the column vector across all qubits see:  and it can do so no matter how many qbits are involved in a few hundred nanoseconds. But it is not a discrete computation of each cell. It is much more like an analog pulling on one spot in a tightly connected web of nodes and rubber bands where the positions and forces automatically adjust in every node when you pull somewhere.
and it can do so no matter how many qbits are involved in a few hundred nanoseconds. But it is not a discrete computation of each cell. It is much more like an analog pulling on one spot in a tightly connected web of nodes and rubber bands where the positions and forces automatically adjust in every node when you pull somewhere. The final surprise was that Smith considers stuff like encryption breaking as not ideally suitable for QCs. He thinks that molecure simulation is much better suited for QC. This has to do with the "noise" or error included in quantum computations. It affects sensitive algorithms like Shlor's much more than e.g. molecule simulation. As for our initial question about breaking encryption keys with QC, it looks like we need one qbit per digit of the key which means that a solution is still some years away as we are now building QCs with 10-50 qubits. Spatial partitioning breaks superposition and does not work.
- Speech recognition on the Internet - Google Duplex and beyond
The article on Google Duplex raised a lot of comments and sometimes worries about machines pretending to be humans. But first, the quality of text-to-speech processing has gotten amazingly good, thanks to technologies like recurrent neural nets and the addition of "filler sounds" like "hm" which are very common in speech.See WAVENET : A GENERATIVE MODEL FOR RAW AUDIO . One immediate consequence of this progress is the total loss of identifying quality of spoken words. This gives a new perspective on telefone based social engineering e.g. where somebody claims to be your nephew. Today this does not work often due to dialects or individual speech features which allow us to recognize somebody we know. Tomorrow: not anymore. And on a grander scale, when we think about video characters with arbitrary textures/gestures etc. that can mimic real persons. Or arbitrary image manipulation. In other words: biometric features are no longer proof of your identity (we already know that they are no secrets). What is proof of you identity on the Internet? It can only be your private key used to sign statements. It used to be the other way round: When I started working all things digital seemed to be temporary, mallable, simply not sturdy like analog things. Now it is the analog stuff that can be manipulated in arbitrary ways and no longer serves for identification purposes. When will DNA lose this quality as well?
Of course natural TTS creation allows new business models. Google can now use Duplex to query small companies like restaurants for their opening hours during special holidays and put this information on maps. Many small companies do not have an online query service.
People using digital assistents will be able to save a lot of time as repetitive and delayed tasks can be delegated. At the price of a complete loss of privacy of course. The latest Alexa problems showed two things: First, digital assistants are only useful, when they know everything about you. Second, token based speech recognition leaves ample room for parse problems. In this case, Alexa picked key words from a longer discussion between several people - including "record" - and - after finally understanding "right" - delivered the recorded stream as a voice message to somebody on the address list of the couple. This shows a fundamental limit of keyword parsing to save energy and privacy and smartphone vendors are working on local only speech recognition e.g. based on two NNs.
We talked about social engineering with TTS. How about attacks on speech recognition? Nowadays adversarial deep learning networks are able to manipulate images and video in various and mostly for humans undetectable ways. What are the core requirements? a) hide existing information in the input stream from the NN. b) create information and embed it in the input stream. c) change existing information in the input stream the way you like it. In all cases the delta to the original input needs to be below human detection levels. Audio Adversarial Examples: Targeted Attacks on Speech-to-Text, Nicholas Carlini, David Wagner, University of California, Berkeley show that these requirements can also be fulfilled in the case of speech manipulation. Currently only with a white box approach (attackers have full access to the NN), but other adversarial attacks on images and video started in the same way and turned into black box attacks shortly after.
But how can we make the manipulation pass the human ear? The morning paper has a nice discussion of so called Dolphin attacks, described in Inaudible voice commands: the long-range attack and defense Roy et al., NSDI’18 . The authors describe how commands for digital assistants are made inaudible by transforming them into a high frequency space (e.g. 40khz). When played, the high frequency parts are inaudible even to the receiver, but they create audible shadows in lower frequency bands which can be received and understood. This goes without humans noticing it, especially when the spoken phrases are split into several partitions and replayed from different loudspeakers to keep the volume down. This works beyond 7 meters already. Combined with adversarial attacks, perfect and individualized speech generation, this makes it very hard for digital assistants to prevent spoofing attacks. The paper shows, that such attacks through frequency shifting generate suspicious frequencies and amplitudes though, which can be detected by receiver circuitry. The question is no longer only whether you can trust your digital assistant. It is now the digital assistant worrying about you...
Well, what is left then? Perhaps thinking about something inside your head and have gadgets listening to your mind But can you trust this conversation? Does your mind have a digital private key? And finally: do you trust your mind?
- The Client-Server Internet and its forces
 What have IPV4 addresses and submarine cables in common? They are indicators for the client-server structure of communications on the Internet. The IPV4 address space should be gone by now - replaced by IPV6. This hasn't happened yet despite enormous growth in mobile and IoT devices. The reason this has not happened yet is that mobile service providers use carrier grade NATs to map private addresses to public ones. This in turn forces C/S style communication. Is this bad? Well, from looking at the traffic patterns in the Internet it looks like C/S communication IS the dominant type of traffic on the Internet. This is largely due to few content providers dominating content and using private CDNs to ship the content to users. Clients initiate the communication and after that it is all within the providers CDN. Which leads us to the second indicator: submarine cables. They are nowadays owned by single content providers for their closed networks.
What have IPV4 addresses and submarine cables in common? They are indicators for the client-server structure of communications on the Internet. The IPV4 address space should be gone by now - replaced by IPV6. This hasn't happened yet despite enormous growth in mobile and IoT devices. The reason this has not happened yet is that mobile service providers use carrier grade NATs to map private addresses to public ones. This in turn forces C/S style communication. Is this bad? Well, from looking at the traffic patterns in the Internet it looks like C/S communication IS the dominant type of traffic on the Internet. This is largely due to few content providers dominating content and using private CDNs to ship the content to users. Clients initiate the communication and after that it is all within the providers CDN. Which leads us to the second indicator: submarine cables. They are nowadays owned by single content providers for their closed networks.More and more the Internet is split into a few content silos with the public transit channels becoming less important.
Ihe Internet of the future a big private CDN? Geoff Houston is discussing this in The Death of Transit and Beyond and Alan Mauldin adds additional information on submarine cables etc. Looks like the Internet is getting restructured and privatized even more. A good explanation and overview in German from Monika Ermert, Heise.de
Does this mean that the discussion about net-neutrality and the whining by carriers about the imbalance between content and transit needs to be reconsidered? At the first glance it looks like net-neutrality favors the big content providers and endangers public transit and its infrastructure. But if we look at the winners of anti-net-neutrality laws, we will probably find some telcom giants like AT&T and not the many small and medium sized ISPs which feel the pressure from CDNs much more.What becomes clear is that the original self-government concept behind the Internet is gone and will be replaced more and more by regulatory acts. Depending on the current political direction some sides are going to win and others are going to lose. What is sure about this is: the general public, small company newcomers and peer-to-peer architectues will not win at all. More on US monopolies in media can be found in Tim Wu, the master switch.
- A new and better Facebook?
There is quite some commotion in the social media. Facebook and Youtube are deleting massive amounts of extremist postings. Zuckerberg is promising better protection of user data and there are rumors about Facebook creating a paid version without ads. And it looks like Facebook will enter the dating app scene as well. At the same time many people publish harsh criticism of the current social media sphere, e.g. Mike Loukidis with "The second time as a farce". And there are some interesting ideas and sometimes even running systems for a decentralized - perhaps only federated - social network.
Before we speculate about a new and different social network - and a real chance for succeeding- we need to clarify how Facebook is used today. A short query in my course on current internet topics uncovered some major use cases: Surprisingly, the "original" Facebook effect: finding friends and being found by friends is still seen as a core feature, even though most friends have been found by now. Some students mentioned getting infos about events or using the timeline alike an entertainment channel on TV. The bad news for Zuckerberg is, that in this age group (20-30) most accounts are not used on a regular base. But most did not cancle the account though. Some Facebook users use pseudonyms, most use their real identity. Some are aware of companies checking facebook accounts during the job application process and many are unsure about the effects on reputation if you have a Facebook account or not.
So why is Facebook no longer in use with many people? The students mentioned that the timeline contains too many things which are simply of no interest to them. They realized that communication with many people is simply impossible due to time reasons and lack of interest. And the massive amount of "brand" news is a real nuisance. In other words: the radical and extreme engagement model of Facebook turns out to drive people away, just as Mike Loukides had written in his blog entry.
So is it time to start a Facebook competition and what would be the chances of doing this successfully? One idea could be to create a very simple user interface - basically a google-like look-and-feel for social network information. I could subscribe to this because when I tried to cancel my account after 5 years of inactivity, the amount of crap that Facebook presented to me at login was simply a turn-off and I went to google to search for "delete Facebook account". Another idea would be to combine the current Facebook universe consisting of FB, Instagram and Whatsapp into one new servide. Students guessed that they are still kept separate for reasons of resilience in case the main product FB goes south. Finally, a payment service integrated into the social network could be a killer feature. Who could start a FB competition? All agreed that it should not be Google as they have proven that they can't do it. Somebody like Netflix perhaps? Adding a social network to their streaming offer? Or a highly integrated chinese giant corporation?
The final question is: should this new social network be distributed or federated? Going through some papers (e.g. Mathias Beyer's idideas for a dsistributefd social network and the comments on y-combinator it looks like going distributed is not a very realistic proposition right now. It is too complicated and there are many basic questions open without a clear idea for a solution. Previous distributed solutions like Diaspora were simply unusable by non-CS-people and current systems seem to be playgrounds for extremist views due to moderation problems. And how do you moderate a distributed social network?
- Off-chain transactions (PBT)
Due to the limitations of current blockchain technology with respect to scalability, speed and costs of transactions (both environmentally and transactional), off-chain approaches have a lot of appeal. They do not use the blockchain to secure every single transaction. Instead they rely on an initial money transfer via blockchain and then allow micro-transactions between participants. Those micro-transactions are routed through a network of credits between participants. They are supposed to be anonymous wrt value, sender and receiver.
Settling payments fast and private: efficient decentralized routing for path-based transactions by Roos et.al. describes various routing schemes. Unfortunately, the paper is a bit disorganized and hard to read. The whole business background is not mentioned at all and we had a hard time in our Journal Club to make sense out of it. A discussion of the paper in morning club did not help much. It would have been better to start with the Lightning Networkto understand the business side first.
Still, some valuble insights could be gained. Credit networks backed up by blockchains seem to follow the same deflationary principle: you can give only so much credit to somebody as you really have. No virtual credits like in todays banking system and no chance to increase the amount of money in the system. Routing can be done via central landmarks or through a coordinate system as an overlay. The most interesting aspect was receiver anonymity. It does not work like an onion network (tor). The trick is basically for the receiver to generate a long route in advance which includes her own address but does not end there. Observers cannot know whether the transfer stopped at a certain receiver or not.
Many other points are still in the dark: a credit usually does not mean that at any moment funds can flow back. The arbitration and conflict resolution is completely unclear to me. s
- What's so special about GraphQL?
-
 After discussing GraphQL both in current topics of the Internet and our master journal club, GraphQL got much clearer to me. While Rest Uri are non-hierarchical (i.e. they focus on one endpoint and allow some query parameters on it, GraphQL uses Json to model a hierarchical view into a data model, much like SQL does. It allows the client to specify joins of REST endpoint data in a query and the server will use so called resolvers to aggregate the data parts and send a response in Json back. Basically everything that GraphQL does can be done in REST too. But providing all the query options in advance would be not only tedious in REST: it would also require many more requests (the n+1 problem of requests: a collection of items given back from a REST endpoint will require n more requests to the endpoint of the returned elements of this collection. An example: a bookshop wants to offer you the books your friends have liked. It sends a query to the friends endpoint of a social network, with your ID as a query parameter. A collection of friends of yours comes back. Now for every friend another request is make for the books they liked. And then the answer can be presented to you. With GraphQL all this is just ONE request. And on top of this: ONLY the data really needed on the client side are selected for the response. The client can e.g. say to skip additional author information. This means that GraphQL is an optimization for certain types of queries. It also decouples front-end and back-end development a bit as it allows many query types and subtypes. The queries are defined in a schema and controlled by the server, but subsets of queries can be spontanously requested by clients and need no work on the server side.
After discussing GraphQL both in current topics of the Internet and our master journal club, GraphQL got much clearer to me. While Rest Uri are non-hierarchical (i.e. they focus on one endpoint and allow some query parameters on it, GraphQL uses Json to model a hierarchical view into a data model, much like SQL does. It allows the client to specify joins of REST endpoint data in a query and the server will use so called resolvers to aggregate the data parts and send a response in Json back. Basically everything that GraphQL does can be done in REST too. But providing all the query options in advance would be not only tedious in REST: it would also require many more requests (the n+1 problem of requests: a collection of items given back from a REST endpoint will require n more requests to the endpoint of the returned elements of this collection. An example: a bookshop wants to offer you the books your friends have liked. It sends a query to the friends endpoint of a social network, with your ID as a query parameter. A collection of friends of yours comes back. Now for every friend another request is make for the books they liked. And then the answer can be presented to you. With GraphQL all this is just ONE request. And on top of this: ONLY the data really needed on the client side are selected for the response. The client can e.g. say to skip additional author information. This means that GraphQL is an optimization for certain types of queries. It also decouples front-end and back-end development a bit as it allows many query types and subtypes. The queries are defined in a schema and controlled by the server, but subsets of queries can be spontanously requested by clients and need no work on the server side. The discussions unearthed a few distributed computing problems: Powerful single-request queries require fan-out architectures on the server side in addition to performance intensive parsing of a context-free language. But there are many performance tricks available for this type of requirement like intensive caching, query optimization and so on. The response to the client needs to be paged as well in case there are many data. The protocol probably allows paging hints on the client side or will include paging information in the response about additional data being available.
GraphQL is easy to understand and - due to some good literature led to a good discussion on the differences between REST, SQL and WebServices in general.
A special problem is how to prevent clients from requesting to much data - which transforms into the problem of determining response size of a query ahead of time. Luckily I stumbled over a formal solution for guessing the size of the response set in polynomial time which was discussed in the morning paper recently.
- Culture Code - three simple ways to get successful teams
-
 When you see how digitalisation changes work organization (like in the post below), it makes you wonder if this is only the result of e.g. an agile methodology being used. Or if there is something even below that socio-technical level. The book "Culture Code" gives a clear an simple answer by explaining three core rules for team culture:
When you see how digitalisation changes work organization (like in the post below), it makes you wonder if this is only the result of e.g. an agile methodology being used. Or if there is something even below that socio-technical level. The book "Culture Code" gives a clear an simple answer by explaining three core rules for team culture:Create a safe space! By doing so you encourage team members to take over responsibility and voice concerns and new ideas. Blameless post-mortems are key to that. Encouraging a failure culture, supporting struggling members and avoiding ego games and extreme competition, you help creating that space. Without it, members will hold back and run defensive strategies.
Show vulnerability! Show that you need help in a leading position. Show when you have no idea on what to do and you will encourage people to step up and help solving the problem. It motivates members to play an active role and much better results will show up.
Create purpose. That is probably the hardest one for many leaders. It requires charisma (something not easily learned but mostly given) and other abilities like touching somebodies heart and soul. It is best explained by the famoud quote from Antoine de Saint Exupery about building ships. If you want ships you should not teach your people about hammers, nails and planks. Instead, you should create the longing for the sea in them. In more earthly terms it means to share goals, keep your people informed, notice when they start getting anxious or think that goals are unreachable and in general follow the principle of "loosely coupled, tightly aligned" (Netflix). If your people do something stupid, ask yourself what you missed telling them. (Netflix)
The book explains the principles with stories from the military and corporations. Stories about very special people who can create excellent teams, sometimes mostly by listening to people. It is easy to read but gives you the explanation for spectacular failures of some methodologies. It is not the methodologies (scrum, extreme, Prince II etc) that fail, it is the social base that the groups are missing!
- Interaction Day at HdM - Digitalisation changes everything
-
 A few comments on the talks at our Interaction Day. First, there was little about UI/UX and lots about organizational changes due to the fast going developments in digitalization. The first talk brought back an alumnus who had only two years ago left our faculty and started work at stoll.von Garti, an Internet agency working on process automation topics in the industry. Much to his suprise our alumnus told us, he found himself not right in the development group but deeple involved in customer relations, concepts and architectures. The project involved optimizations through bluetooth beacons which make industrial devices much trackable through mobile phones etc. The corresponding mobile apps were developed according to user centered design principes and the overall process hat many agile elements. While optimization seems to rule in the IoT area, AR and VR provide ample opportunities for ground-breaking developments.
A few comments on the talks at our Interaction Day. First, there was little about UI/UX and lots about organizational changes due to the fast going developments in digitalization. The first talk brought back an alumnus who had only two years ago left our faculty and started work at stoll.von Garti, an Internet agency working on process automation topics in the industry. Much to his suprise our alumnus told us, he found himself not right in the development group but deeple involved in customer relations, concepts and architectures. The project involved optimizations through bluetooth beacons which make industrial devices much trackable through mobile phones etc. The corresponding mobile apps were developed according to user centered design principes and the overall process hat many agile elements. While optimization seems to rule in the IoT area, AR and VR provide ample opportunities for ground-breaking developments.The second talk came from Siemens Karlsruhe - a 4000 heads strong location of the Siemens corporation. The talk centered on agile methodologies and architectures like cross functional teams, scrum, best of breed software languages and products, supporting tools and basically everything that helps to speed up development. It was very obvious that Siemens has read the papers on corporate culture of the Internet unicorns and carefully picked things that help without destroying everything. The speaker claimed full support by top management. Development groups have the autority to decide on technology and method and communication between cross functional teams is supposed to keep choices within reason. "bottom up intelligence" is clearly no stranger at Siemens Karlsruhe and they seem to be proof of successful transfer of agile culture to large corporations.
The presentation included a short video Digital Enterprise -implement now, Siemens at Hannover Fair 2018. I may be wrong but to me videos on digitalization tend to show people in a rather special way: mostly alone against machines, watching, observing, monitoring. There is no tight interaction shown. Frequently machines (robots) take center stage. I am not sure if this is the right way to show the future interaction between humans and machines. Humans are bad monitors. And why would you need humans to monitor if machines are much more reliable observers too? To me it looks like the optimization approach mentioned above automatically leads to humans becoming mostly superfluous. We need to reach for new goals to make the combination men-machines useful and necessary.
The final talk by a top manager from AEB - a company that runs about 30% of Germanies export/import data on their machines and software - centered even more on the mixture of emotions and agile methodology: "Scrum Yoga" is their concept of basing the methodology on Scrum without beeing too religious about the rules. "Principles are more important than rules" is their motto and this helps to introduce the methodology at customers who are not willing to a) learn scrum completely and b) hire a Scrum master for the project. AEB made a list of 5 topics which they found most important for project work: self-driven responsibility, time-boxing, customer centricity and the last two I have forgotten... The AEB speakter was very clear about the emotional side of work and emphasized, that knowing what drives people is key on supporting their development. AEB is also fairly new to agile methodology (5 years compared to 35 years of classic project management) and not everybody was initially keen on getting on the agile train at AEB.
What are the key lessons learned this afternoon? Digitalisation really seems to change everything, including the internal organization of work. Self-controlled and managed work is key. Hierarchies play a smaller role. People only stay when they find fulfillment in their work and that means that work has to be fun. If you hear about the changes necessary to be fast and digital, it makes you wonder when and how this wave will reach the universities. There seems to be an abyss between industry and academy in our days and it looks like academy has no clue on how to bridge this gap. But that is a topic for a different day.
- Where has all the power gone?
-
There is a paragraph in Harari's "Homo Deus" that is almost visionary when you look at the current situation in Britain, Germany and other western countries (except the USA). ““Ordinary voters are beginning to sense that the democratic mechanism no longer empowers them. The world is changing all around, and they don’t understand how or why. Power is shifting away from them, but they are unsure where it has gone. In Britain voters imagine that power might have shifted to the EU, so they vote for Brexit. In the USA voters imagine that ‘the establishment’ monopolizes all the power, so they support anti-establishment candidates such as Bernie Sanders and Donald Trump. The sad truth is that nobody knows where all the power has gone.” ”And, a few lines later: ““Precisely because technology is now moving so fast, and parliaments and dictators alike are overwhelmed by data they cannot process quickly enough, present-day politicians are thinking on a far smaller scale than their predecessors a century ago. Consequently, in the early twenty-first century politics is bereft of grand visions. Government has become mere administration. It manages the country, but it no longer leads it.”― Yuval Noah Harari, Homo Deus: A Brief History of Tomorrow ”
Harari quickly adds, that not all visions have been good, and that a state that just needs administration is probably not in a bad shape. But it leaves a void. A void that is even more problematic as after 40 years of Neoliberalism and the triumph of human liberalism, the field of public participation and engagement has eroded. The idea of society as being fair und just and for everybody to live in comfort has disappeared and been replaced by market religion. Who are the culprits? The digital revolution with its massive influence on our behavior? Jakob Augstein has collected several opinions in the new book "Reclaim Autonomy" but if you read through those, they mostly blame the big 5 (Google, Facebook, Amazon etc.) for all the evil that fell on us. (I am going to comment some more on this book later). The refugees overwhelming the western states have become another negative vision and it has been claimed by the far right corner of the society (Filling the void left by the dying social democracy). I recently went to a talk by Harald Melcher on "the process of civilization" where he claimed, that we seem to have no positive visions left. Which visions are we currently left with? The "data religion" as described in Harari is a rather cold and techno-centric vision that leaves lots of people not knowledgeable enough in Cybernetics and Biotechnology behind, as he admits. And then there is only two others left: The dream of an Islamic world according to the IS, or "lets make America great again", which is an isolationist and backward looking vision.
Again: where did all the power go? It went into process. James Beniger's Control Revolution is now - supported by Big Data and Machine Intelligence - running the world like a clockwork. Except that some of those processes are on a track that is going to hit obstacles rather sooner than later. Obstacles like the climate change, the pension problem, automations effect on jobs, diesel exhaust gases etc. ( TTIP would have been the mother of all control revolutions: economy regulating itself with the help of some lawyers from New York and London). People notice those problems and -as they have a lot to lose in western societies - they get scared. People know that they are only passengers in the western representative democracy. And now they wonder if there is somebody left in the driver seat. Fear turns into rage easily and that is what we see.
How about driving by yourself? Well that's REALLY uncomfortable for all participants, but mostly for those in power as can be seen with the BREXIT. Or with the Trump election which surprised the political elite and Silicon Valley a lot. I don't think people are unwilling to accept change. They accepted the Energiewende and are paying for it. Just to see later on, how it got lost somewhere. The economic imperalism behind globalization, Europe, TTIP etc. is now causing its downfall als people are starting to lose trust in the systems. Will more direct democracy replace the losing power of representation? The economy and political parties will fight it to the end, as it is quite uncomfortable for "the process". It is so much easier to tell people, that things are without alternative ("alternativlos" - Merkels most favourite word). But how come we hear about alternatives like free public transit once the political establisment faces a serious crisis like right now in Germany? That leaves us with the hope that change is still possible! For the rest, I guess we will just have to wait and see what is going to happen in Asia. Could be that they are not only taking over economically but also with respect to future visions of society based on social credits.
- Security problems - nobody can say they didn't know!
-
I wanted to write a bit on security several times now but never really got around to do it. It started when Linus Thorvalds and the Google team that chases security problems had that little dispute on how to deal with security relevant bugs in the kernel. While the Google team implemented a hard kernel panic when they realized some exploitable bug, Thorvalds got mad and told them to fix the bugs instead of shutting down live systems. I guess both sides have some good arguments for their strategy. I am sure users hate kernel panics which in most cases would not have prevented a security exploit because the system wasn't under attack anyway. But what if the bug doesn't get fixed because nobody cares?
That scenario reminds me about something that happend when I was a young system programmer in the Unix kernel devision of Siemens. As usual in such kernel teams, young professionals take over responsibilities for drivers and other low level stuff and gradually move into more complex areas. One morning I had just started my workstation and ran a testprogram against one of my drivers, just to be rewarded with a nice kernel panic! As more and more developers slowly trickled into the office, you could hear astonished calls throughout the floor. Soon we realized that we ALL got those panics with our respective drivers! What had happened. As usual, a new kernel had been built over night and we installed it in the morning on our development machines. Something had to be wrong with the kernel built last night. We started to look at the error message which said something about interrupt levels not being cleared at return to user. Hm, sounded kind of strange. Finally, after some confusion, guessing and reboot, a mail from an experienced developer in the kernel team told us what was going on: He had detected one major reason for performance issues in the kernel: Many drivers have to block interrupts from the hardware while they are doing critical operations like updating shared structures (this was in the old days of monolithic kernels and shared threads between kernel and user area). After the critical section they unlock interrupts as quickly as possible because otherwise events from the hardware are not handled as fast as possible. The problem was very simple: The driver developers tended to forget the unlock operation. We all know that developers are unable to handle pairwise operations, because there are endless ways of bypassing the unlock statement. This is true for memory allocations, open/close style APIs and of course also for locking and unlocking interrupts. Some kind soul had made a little change in the kernel at exactly the moment, when a users call into the kernel would return to the user. If the interrupts were still blocked, the code would simply reset the mask and unlock everything. It may have even printed some warning in some logfile, but I never saw anything and most developers probably wouldn't have cared anyway.
After many futile attempts to make the colleagues aware of the performance consequences of forgetting the unlock call, he simply changed the code at return to the user into a call to panic! What can I say? It worked. On that day EVERY driver developer found SEVERAL places in his or her code, where the unlock call had been forgotten. The impact on kernel performance was measurable. Of course everybody was mad at the guy who changed the code to panic. But honestly - would things have improved otherwise? It would have been better to tell the colleagues in advance about what he was going to do. But changing the code to panic was definitely the right way to go.
Is this example the same as calling panic when a bug is detected, that might have a security consequence? Yes and no I guess. Yes, because it WILL cause the bug being fixed quickly. No, because unlike the first case, the kernel itself might be corrupted. And how would you deal with this? In the first year of my work as a kernel engineer I remember a course from Instruction Set (a British company doing IT-courses). I saw a call to panic in the kernel code and asked why the code did this? I remember saying that this could cause data loss for users and that there should be a better alternative. The instructor simply asked: Which one? Once a kernel discovers an inconsistency in its own data structures, it cannot trust anything within the kernel anymore. By continuing and trying to save user data e.g. it could even destroy more of those data. So the best decision is to stop working at all. (on a sideline: what if the kernel would run in an autonomous car? Can we just call panic? I guess not. So what kind of architecture is needed in this case?). I don't do kernel work anymore and I don't know how microkernels could handle those situations better. But I think if a cloud datacenter discovers that its zookeeper cluster is inconsistent, there is little that can be done except for a reboot of everything if a fallback to a previous, consistent state is not possible. It is like in the case of the lost Ariane rocket due to an exception not handled. It sounds really stupid to lose a 500 Mio Euro rocket because of such a thing. But once you start thinking hard about other options you realize that those are far and few.
So how should we handle bugs in the kernel that (might) have security consequences? Are they just bugs as Thorvalds claims? I tend to agree. A potential buffer overflow is a software bug first and for all. The fact that it can be used for a security exploit is secondary. Bad input validation that crashes or corrupts an application is a software bug and nothing else. Quickly pointing at potential hackers or even blame them for insecure systems just lets developers hide behind their buggy and bad code.
This brings us to another trigger for writing all this: the paper Adrian Coyler discussed today in the Morning Paper: Daniel Bernsteins 10 year old paper on his product qmail. Reading how Berstein created qmail without a security bug in many years makes you realize that secure software IS possible. And sadly, how little changed in software development with respect to security in all those years. One year after the Bernstein paper Roland Schmitz and myself published our second book, this time on secure systems. We discussed the Bernstein paper in our book and extracted his methods for bug-free software to be put in our toolbox for damage reducing systems. And Adrian Coyler mentions three things Bernstein said to not do: Don't blame insecure software on hackers. It is your software bugs that make the attacks possible. Not the other way around. Don't focus on attacks - focus on making your system robust, e.g. with watching out for integer overflows.
People are usually suprised when I claim that pen-testing is a very limited and unsustainable approach to secure software or systems. But pen-testing won't make your systems any safer except for the few bugs found an fixed. Nothing in the architecture has been changed and you are just waiting for the next security bug to be detected by hackers. As Bernstein said, we need to fix the foundations of our systems and the way we develop software, not focus on attacks.
Coyler was surprised that Bernstein accused the concept of least privilege to lull us into a false sense of security. Bernstein said, that minimizing privilige does not mean minimizing trusted code. And he is right of course. Trusted code is nothing else than "ambient authority" lying around, waiting to be exploited with attacks like "confused deputy". If those terms don't mean anything to you, read our book or go to erights.org for further information from the capability movement.
And with the last of Bernstein's no no's: speed over security, we get straight back to todays problems. Qmail carefully splits dataflows between users and lets those flows run with the respective users rights instead of root. There are certainly faster ways of doing things, but are the as safe? And a total focus on performance over security seems to be behind todays IT-nightmares with the names Meltdown and Spectre. The morning paper has discussed the main scientific papers and on highscalability.com the latest papers on Retpoline - Googles magic code rewrite technology that supposedly even cures Spectre-attacks (this is actually disputed) can be found. I won't go into the details here but one thing is clear: we could have known this long ago. Two years ago in my master seminar we looked at Intel Uefi and system management firmware attacks. The firmware used unprotected function pointers to call into the OS. A year later we learned about major problems in Intels remote management firmware. I do not know any fundamental cure against covert channels. It is true that the attacks mentioned combine an isolation failure caused by parallelization with a covert channel. The isolation failures itself would be inconsequential. But again, as no fundamental cure against covert channels is known (finally, all information processing has a physical dimension as well, which, given exact tools, can be traced and measured. This fits nicely to the revelation, that EVERYTHING on earth is uniqe and can be used for identification, as long as tools have the necessary granularity for their measurements. From how far can we read RFIDs? Your CPU/Network Connection etc. are all unique even without IDs, just because of their unique behavior.) optimizations for speed that weaken isolation (e.g. shared branch prediction) turn out to be deadly. Looks like hardware developers are not so much different from software developers. Bruce Schneier in his January cryptogram predicts 2018 to be the year of the processor bugs. Now that researchers really take a look at what is going on in our CPUs we can expect many more problems. Just compare the features of a 8088 with todays core-7 CPUs. When I started developing system software I frequently had to port realtime executives to new CPUs. Since we were only developing in C, few assembly code was needed for interrupts and context switches and a short look into the CPU handbook usually was enough to come up with the necessary code. I probably wouldn't understand half of a Intel handbook on core-7 CPUs. Hardware transactional memory, support for VMs and way below the surface the translation from CISC to RISC. Not to mention the magic chip designers use to keep the CPU cool by turning off units etc. I think Schneier is right, it will be an interesting year for everybody responsible for critical infrastructures.
A litte bit of guessing: I would pick complex features like hardware transactional memory to find race conditions and isolation breaking optimizations for performance. I remember a chapter in Jim Gray's famous book on transactions with the title "A shadow world" (or something close to it). To speed up parallel transactions you let every one work on its own copy of the world and at the end cancel those histories which can't become reality due to conflicts. This requires extensive state management and I suspect that there are many functional units involved which will show side-channel effects both for sensing and acting. A test scenario would be to run parallel HTM blocks in different processes and look for cross-process influence.
So what can we do for those infrastructures when our whole hardware/software stack is compromisable? Only the overall architecture of a critical infrastructure can bring damage reduction and resilience. No single IT component will do. Concentration and remote control will weaken our solutions. Decentralization and data flow over control flow will harden them. Many and sometimes even expensive or unconventional ideas will have to be used to ensure damage reduction. In my talk on our security day I gave an overview on the desperate situation in the industry and some ideas for such a system. Looks like the talk is still quite relevant.
- 17. GamesDay at HdM
-
Another Gamesday is coming up with a broad an interesting line-up of topics and speakers. We will start with a technical talk on rendering techniques by Clemens Kern, a long term game engine specialist and Alumnus. Next, (name removed on request) will explain his way into the game industry, followed by Alina Dreesmann from Deck13. She will show us, that environmental storytelling removes the need for huge numbers of NPCs. Finally, Maximilian Krauss from our games institute will show you, how the serious parts of a serious game can indeed improve your game experience. Lessons learned from a current research projekt.
Agenda 14.15 Welcome, Prof. Walter Kriha 14.20 "Rendering pipelines in games: How to render many lights", M.Sc. Clemens Kern 15.25 "Mein Weg in die Gamesbranche", (name revovedon request), Iron Beard Games, Stuttgart 16.30 "Environmental Storytelling - warum Welten für sich selbst sprechen sollten", Alina Dreesmann, Leveldesigner, DECK13 Interactive GmbH 17.05 "How 'the serious' can enrich your game experience", Maximilian Krauss, HdM Stuttgart 18.15 Wrap Up
Judea Pearl, The Book of Why 
Frederic Laloux, Reinventing Organizations 
Rutger Bregman, Utopia for Realists 
Yuval Noah Harari, Homo Deus 
Jakob Augstein (Ed.), Reclaim Autonomy 
Judea Pearl,
Causality 2nd ed. 
The Art and Science of Cause and Effect, Judea Pearl
The Art and Science of Cause and Effect, Judea Pearl