What's New
- Mathematical background for books on logic, knowledge representation and computer science
-
John F. Sowa, american philosopher, mathematician and computer scientist wrote some well-known books on causality, knowledge representation and is also the inventor of conceptual graphs. He has collected a few math bits which are needed to read books on logics, knowledge representation and computer science. The paper contains the basics of propositional and predicate logic (first order), graphs and lattices and some formal grammer and model theory stuff along with the usual set math. It is called Mathematical Background and it is quite easy to read.
For good measure I'd like to throw in also a presentation by Judea Pearl (1999) "Reasoning with cause and effect," Proceedings IJCAI99.. Can't wait for the second edition of his famous book on causality.
- The Future of Communications - the NETT Kolloquium at University of Freiburg
-
Yesterday I attended NETT - Neueste Entwicklungen in der Informationstechnologie. Organized by Prof. Müller who holds the chair in telematics at the University of Freiburg, the kolloquium gave an overview of current developments. Unfortunately I could only stay for the first two tracks on communications and economy/technology. I missed the talk of Prof. Pfitzmann on "multi-lateral security 2.0" but I will try to get the slides.
While I started my work in the industry in communications I am no longer really familiar with this area and was kind of surprised by the title of the first talk by Prof. Eiffelsberg "The Internet works -why do we still need network research?". I thought indeed, why? It turns out that the beauty of the internet starts to suffer when we look at the control protocol part of it instead of the nice hourglass-shape of its data layers.
Now this does not really bother me much but the difference in architecural clarity was quite stunning.
Next the term "network coding" was introduced. It is actually a very simple way but could reduce the communication overhead in routers considerably. Imagine two computers sending messages via a router to each other. Currently the router will have to forward all messages to the recipients in single message sends. Using network coding the router could save from half to one/nth of all message responses with n being the number of communicating nodes.
The trick is quite simple: Two participants are required to store the message they sent for a while. The router will xor the messages it received and send them out via broadcast to both participants. Now imagine a wireless access point. This works like a broadcast or multicast system and all participants can receive all messages. If they store these messages the router can combine ALL responses in a certain timeframe and send them out in one broadcast message. As all participants know what everybody else sent initially they can use those messages to xor the broadcast response and recover the response sent to them.
In a private mail Marc Seeger pointed out some potential problems with network coding. In wireless networks so called "hidden nodes" exist. Each of them can contact an access point but they cannot reach each other because they are at opposite sides of the access point and their signal is too weak. This would be a problem for network coding because participants would miss messages from others and couldn't decode the broadbast messages for this reason. The problem of hidden nodes led to collision avoidance instead of collision detection in wireless networks for this exact reason. In regular LAN infrastructure broadcasting responses turns switches into hubs and also requires a switch to send all messages also upstream. This in turn would cause a reduction in traffic in relation to the number of participants.
So there are a number of open questions behind network coding. Another point currently unclear to me is when a router would assemble a combined message and broadcast it. There seems to be a trade-off between latency and possible traffic reduction. A last point: distributed algorithms for highly-available systems, so called group communication algorithms used e.g. to achieve virtual synchrony, use multicast or broadcast intensively and - in connection with asynchronous messages - achieve extreme levels of replication across compute nodes (see Birman, Reliable Distributed Systems).
Interestingly Prof. Eiffelsberg considered most current research in communication networks and new internet technologies as rather unfocused and kind of helpless.
The second talk in the communications second had some surprises in store as well. Prof. Steinmetz from TU Darmstadt talked about communications and services for Next Generation Networks. And he mentioned e.g. the need for communication specialists to investigate the ways social communities are formed on the web. I guess communication technology has come a long way from e-tech to this point of view..
Prof. Steinmetz also mentioned Cross-Layer Architectures. Communication networks are typically organized in strictly separated layers and cross layer dependencies are usually shunned. But being a multimedia-communications specialist he also saw the need to break those layer-separations in order to achieve necessary qualities of service.
The next two talks were about economy and technology. Dr. Sackmann from the University of Freiburg explained the "Freiburg model for compliance". Compliance and in its tow risc management are currently hotly debated topics. The crash of companies like Enron and Worldcom during the burst of the DOTCOM bubble triggered new legislation (Sarbanes-Oxley, Basel II and so on) which required huge investments in software for the companies listed e.g. at the NYSE.
There are two different approaches in how to deal with compliance issues. The first is to design systems that make compliance violations impossible, the second is to detect those violations after the fact. Dr. Steinmetz explained that a combination of both are needed in reality, e.g. for cost and efficiency reasons.
He then showed an approach to combine the regular business process rules with rules for compliance. Technically they are both just rules and it is much easier to model the whole process (business and compliance) separately for reasons of re-use but to realize that finally they are just that: rules.
Necessary exceptions e.g. from the four-eye-principle in case of employees being sick, need to be modeled as well and controlled by compliance policies.
I learned from this talk that the wave towards "total control" does not stop at the state or at citizens being controlled anytime anywhere. IT penetrates companies and employees just as deeply and thoroughly. For me this raises some questions: Will we finally burn more energy to control things than to build them? Is total control really an effective way to run a company or a state? And finally: the current financial crisis happend in spite of SOX, Basel II. So what does this say about compliance requests in general? Was there to little compliance? Or was the reason for the financial crisis not a compliance issue at all (I know only of the Societe General case where compliance violations seemed to have played a major role).?
Finally Dr. Strüker also from the University of Freiburg talked about communicating things, calculating clouds and virtual companies. I found especially interesting what he said about cloud computing. I am currently assembling a paper on media in distributed systems and I was not sure how to deal with cloud computing yet. The referent gave some interesting numbers on the size and numbers of datacenters built by Google, Amazon and now also Microsoft. According to him Microsoft is adding 35000 machines per month. Google uses 2 Mio. machines in 36 datacenters worldwide.
But the way this compute power is used surprised me even more. The first example was the converson of 11 Mio. New Your Times articles to pdf. Instead of building up an internal infrastructure of hundreds of machines somebody decided to rent compute power from the Amazon Elastic Compute Cloud EC2 and ended up with the documents converted in less than a day for only 240 dollar.
Then he mentioned the case of animato, a company creating movies from pictures. Interesting about this case is that animato used the EC2 cloud to prepare for incredible growht. I don't remember the exact numbers but the growth of requests was so big that without an existing, scalable infrastructure, the users of animato would have experienced major breakdowns. There would have been no way to increase compute power quickly enough to comply with this growth rate.
But the last cases were even more astonishing. They were about businesses using the cloud to do all kinds of processing. This includes highly confidential stuff like customer relationship handling which touches the absolute core of businesses. I was surprised hat companies would really do this. In large corporations this type of processing is done internally on IBM Mainframes. The whole development could spell trouble for the traditional IBM Mainframe strategy as a new presentation at infoq.com already spells out: Abel Avram asks: Are IBMs Cloud Computing Consulting Services Generating a Conflict of Interests?
- The design of ultra-large scale, self-sustaining systems
-
Going through the talks about scalability and reliability covered on infoq.com (and also the qconf talks of this and last year - conference I was not really aware of but which looks like something exceptionally good)I saw this talk on ultra-large, self-sustaining systems by Richard Gabriel. What a crazy and inspiring talk this was! Richard Gabriel is talking about systems with trillion lines of code. Far beyond what is called a single system concept (a concept basically created by a single architect: relatively consistent and understandable). Actually beyond human abilities to design.
He mentioned all kinds of problems with those systems: maintenance, the growth over decades which leads to an ultra-heterogeneous system landscape, no central administration posssible, developers no longer available after so many years and so on. He also cites several different architects like Guy Steele trying to define what design really means.
But to me the most fascinating part was when he gave the example of a digitally evolved algorithm (on a FPGA which is an IC where the logic - the routing between the gates to realize elements of cominatorial logic - can be specified later. In other words: a programmable chip) used to distinguish two different circuits. Gabriel mentioned several hard to believe statements about this algorithm: Grown on one FPGA it does not run well on a different instance of the same FPGA type. The reason might have to do with a really strange thing: Disabling cells in the FPGA which seem to be totally unconnected (and unused) by the algorithm, the algorithm fails. Looks like the digital evolution process on real hardware took specifics of this hardware into accout. As Fred Brook always said: intelligence needs a body..
For those with little time: there is a nice paper version hidden on Gabriels homepage with the title Design Beyond Human Abilities
I always wondered if the way we program systems was the best way to use the computational power of those systems to the max. I guess we try to program systems in a way that makes them at least partially understandably and (also partially) predictable. What if we have to give up some of these properties to achieve new levels of computation? It is a well known architectural pattern that reduction of trusted and tried requirements can lead to a totally different and in certain ways much more powerful system. The web is a typical example: Get rid of transactional control and reliable retrieval und you can scale across billions of documents. Peer-to-peer systems also give up on certain guarantees and are rewarded with incredible scalability.
Growing digital systems in an evolutionary way is certainly both a scary and an attractive idea. But what kind of systems could grow out of this? Will those systems even be able to develop intelligence is certainly one of the more interesting questions. In this case I presume they would go way beyond human abilities simple due to size and resources available. There is only so much room in our brain... Another would be: Can these systems grow beyond the abilities of a turing machine? Solve the halting problem, the Entscheidungsproblem (whether a formula in predicate calculus is a tautology) and others. You might want to take a look at some hypermachines which are buildable in the paper by Toby Ord on Hypercomputation: Computing more than the Turing machine.
- Architecture and Design vs. Programming Language, a proper antagonism?
-
Recently we had a discussion about more software architecture classes in our faculty, mostly driven by student demand. While there is little doubt about the importance of software architecture and the deficits we had in our curriculum some statements were made during the discussion that made me a bit incomfortable about the rationale and motivation behind the demand. What can you reasonably expect from architecture and design and what is the relation to programming languages?
But before I talk about specific things I'd like to mention that the second edition of an excellent book on software architecture has just been published.
 Software Architektur: Grundlagen - Konzepte - Praxis
The book will be used in new seminars on software architecture and design and provides a very systematic introduction and overview on this complex topic. And what makes me especially proud is that three of the authors are either faculty members or have been associated for a long time with the faculty. They are also friends and in some cases go back a long way to the time when I had just finished a large framework project and written a little draft on "frameworking" which summarized the lessons learned in this early framework project. The draft turned into an incubator for many discussions and projects later.
Software Architektur: Grundlagen - Konzepte - Praxis
The book will be used in new seminars on software architecture and design and provides a very systematic introduction and overview on this complex topic. And what makes me especially proud is that three of the authors are either faculty members or have been associated for a long time with the faculty. They are also friends and in some cases go back a long way to the time when I had just finished a large framework project and written a little draft on "frameworking" which summarized the lessons learned in this early framework project. The draft turned into an incubator for many discussions and projects later.Just to make sure that everybody understands that I do value architecture, design and making models.
Now about the things that make me a bit uncomfortable because I feel there are common misconceptions in the heads of management, developers and students behind. Perhaps at the core of the discusson on the value of software architecture I smell traces of false expectations and hopes and sometimes a wrong idea on how development groups do work. I have always rejected the classical split of software activities into roles like architect, desinger, coder. My sociologist mind knows that such role definitions will lead to social and financial separations and create a very difficult work environment. Once these roles are assigned to different persons, e.g. the architect will typically no longer be involved with implementation - and no longer get feedback on the consequences of her architecture. Architects are chickens, not pigs . (Thanks to Frank Falkenberg who made me aware of the fact that not everybody might know the story about the different commitment of chickens and pigs in projects. And he sent me the link to the wikipedia article.)
Don't get me wrong: there are different activities in a software project. But try to combine them in people instead of assigning them to different persons. Organizations who break the unity of analysis, design and implementation do not work well. I have described the rationale behind this in a paper on "social structures in software development".
Another uncomfortable idea is that beginning software developers might consider software architecture as a "kings way" to project success. Now there is nothing wrong with reading about software architecture - you should go ahead and read the book by my colleagues and also others on design patterns etc. But be aware of one effect that you won't be able to escape: Software architecture requires developing software first. From this practical knowledge abstraction is born. This abstraction will be presented in books on software architecture, hopefully together with many examples. But be aware: those abstractions are powerful and reflect a lot of practical experience. But they are not your abstractions yet. You will have trouble understanding them as they are not yet based on your experiences. But they can at least serve as valuable beacons to warn you ahead of problems. After reading about software architecture you will be able to recognize problems in your design when they show up. And recognizing them as probably the most important thing anyway.
More about false expectations and attitudes: "the programming language is not important". "It is all about design". Those statements were made during our discussion of software architecture and I consider them as very dangerous.
Let me quote a couple of sentences from a student currently doing his internship at a software and consulting company. He was told in his office that “the programming language is only a means to an end. Really important is that the design of the system is correct.” And he told me that he recognizes this attitude throughout the company. The actual programming - it does not matter in which language - is seen only as the final finger exercise. The real work is done in designing the system. And he continues that he has a colleague who is working now for one year as a software engineer in this company and who didn't write a line of code yet.
There are a lot of things left unsaid behind such statements. After more than 20 years of development work in the industry I am able to add what was left out: mere finger exercises must be cheap. We can easily outsource this activity. "Techies" are of a lower caste than business analysts and designers. And there is a certain model of software production behind. It is a linear model starting with analysis and architecture and it ends with the implementation as a logical consequence of good design. Such a process removes the sometimes not so calculable things from the software development process. It turns art and craft into automated production and looks so much more modern. But reality frequently does not comply to the linear model. I am not talking about needed iterations. This is evident. I am taling about existing platforms and programming languages with restricted abilities. Every architecture and design needs to finally work on those platforms and work within the abilities of programming languages. Not knowing and respecting those limitations puts your project at risk. Model Driven Architecture (MDA) and Model Driven Development (MDD) do know about this and defined the way from desing to implementation as a process with several transformation steps.
I see many companies with a strong emphasis on design and an high-ceremony, elaborate development process building tomes of documentation, analysis information, requirements and so on but little working code. Requirements seem to play a major role there as well. The religion of "requirements" goes well with the image of a linear software process: the requirements must be right because the implementaion is just a derivative of them. What about flexible implementations? What about changing requirements? "Requirement management" for those companies does not mean: we will build flexible designs and implementations because we realize that the requirements of our customers are incomplete and change over time. Requirements management means using a system that records all requirements a customer has mentioned, timestamps them, digitally signs them and holds the customer hostage to them later on ("you said on 12.December 10.00 sharp that you require X..)
Some companies just can't do better software without help. Say a bio-tech company which excels in biotechnology but struggles with their software. But others - especially software consulting companies - turn the problem of software creation into a religion. Like state employees in public offices like to put dividing walls between them and the citizens those companies create concepts and processes and methodologies of software production and put writing code behind those walls. And as an employee you can hide perfectly behind those walls. Hide your deficits in programming technology and your lack of programming concepts. And there are more arguments against the importance of a programming language: the language might be replaced one day with a different one and then all my knowledge and craft is gone. But more abstract knowledge prevails, doesn't it? Finally these companies are like eunuchs - they can still talk about it but they can't do it anymore...
Some companies resist the methodology trap. They realize that the creation of software is sometimes hard work and needs real specialists and they try to support this with generative techniques (which automatically need more and better modeling). Now there is no doubt that generative know-how belongs into any software developers toolbox, just as a good command of modelling techniques like UML belongs there. But these companies also learn that a generative approach is not everything that is needed. It turns out that it is rather difficult for team members to follow such a technology. Developers realize that they need a good understanding of programming concepts as well as a good understanding of target languages and environments. They learn that a complete end-to-end generation process is almost always a dream only and that they need to mix and match generated and handwritten code sometimes and that a lot of generation technology is just needed to support several platforms like JEE or DOTNET.
So why should you still respect programming languages? Let's first use a defensive argument. You should have an excellent command of a programming language because those beasts are a danger to your project. Countless c++ developers had to learn the hard way that a small c++ program is a very different beast from a large one. They had to learn the really nasty properties c** develops in large scale architectures (see the framework paper). And this goes for any program language: it has properties that affect scalability, maintenance, security etc. and which mostly become visible only after a certain code size has been reached.
There is also a more offensive arguement for the importance of programming languages. And it has to do with an understanding of programming concepts and new programming languages.
Currently there seem to be two very different philosophies on the future of programming languages. One philosophy seem to follow the "means to an end" argument and puts a lot of emphasis on modelling and generation. IBM is currently probably the most prominent representative of that thinking, followed by companies like iLogics. And IBM is currently assembling the biggest piece of modeling bloatware this planet has seen yet with integrating the Rational, Telelogic and other procuct lines all into one modeling and development tool. As a regular and forced user of this platform I can only state that we had to replace thousands of laptops with the biggest desktop machines available to be able to read mail while running the RAD tool at the same time...
The goal of this approach clearly is in generating all source code one day. I don't know whether we are really getting any closer to this vision. The dependencies between platforms, languages and methodologies is very high. I believe e.g. that the trend towards generative methods is partly driven by the uglyness of the current platforms which require huge amounts of stupid glue code or descriptions to work. And many companies admit that they use generation mostly to overcome the platform deficiencies. But again: generative technologies used wisely are a major advantage for software production.
The other approach currently used goes towards better programming languages. Languages that are able to express the major models of computation (functional, declarative with data flow, imperative, logic and constraints, concurrency and distribution. See Peter van Roy and Saif Haridi "Concepts, Techniques and Models of Computer Programming to learn about those concepts). Programmers follwing this approach usually like modern languages like Ruby because it supports higher-order functions and is dynamically typed. They quickly adopt a new technique or special language if it turns out that there is an important concept behind a problem and the new tool or language solves it cleanly. They are not shy of a multi-paradigm approach. They work agile and produce code quickly and frequently. They use advanced testing strategies like unit tests and continuous integration with automatic tests. And they seem to be able to build applications on the web faster than ever before using Rails, Grails etc. Those programmers follow scalability discussions on infoq.com or theserverside.com and they are quick in developing a small domain specific language if needed, e.g. to automate testing. And they are absolutely conscious about the programming language they use and think about improving it with more and powerful features and concepts.
Is this a competitive approach for software development in industrialized nations? I am convinced that inferior ways to produce code will no longer be possible in those nations. Developers with a toolbox that contains "if-then-else" and nothing else (believe me, there is plenty of those developers..) will not be able to compete and their job will not go to India - because the Indians can already do better. Their job will just be gone. The trick is to produce excellent code using the best programming languages and an excellent command of programming concepts, desing and architecture know-how. This is even possible with hardware. Yes it is hard to believe that a German or Swiss company could compete a Taiwanese company in producing hardware. But a visit to Supercomputer Systems in Zurich's Technopark yesterday demonstrated exactly this: An integrated web-cam module for aroun 100 Franken was designed and assembled in Switzerland. Assembly is done by a robot and the price would be hard to beat even in Asia. And on top of that the design is open source (or better: open hardware).
So why don't we turn the initial arguments against the importance of a programming language around and say: architecture and design are just a means to produce correct and effective source code? After all, it is the source code that will finally do the job.
- Security in Virtual Worlds
-
The european network and information security agency (enisa) just published a position paper with the title "Virtual Worlds, Real Money - Security and Privacy in Massively-Multiplayer Online Games and Social and Corporate Networks". While being a bit verbose and dry to read it contains lots of interesting links on past attacks on MMOGs, interesting legal deisputes and tons of open questions. According to enisa Second Live caused more than 2000 so called Online Dispute Resolutions per day - in a population of 30000 active users during the day.
Of course users soon detected ODR as a means to start a Denial-Of-Service attack on other users.
The paper raises interesting questions about the relation between the virtual and the real world. It is quite clear that the virtual worlds are not really de-coupled from the real world, no matter what the EULAs etc. of the providers say. Many legal questions are completely open: when I buy a CD I am allowed to play it at a private party with my invited friends. Why shouldn't I be able to do the same in my virtual house in some virtual world? What is the difference?
The ways people can misbehave within or against the virtual worlds seems to be endless. Gonking (killing other avatars repeatedly), griefing (like bullying others) and external DOS attacks to disrupt transactions of goods with the intent to create illegal duplicates of objects are just some examples.
The section on countermeasures contains some interesting ideas like building safeguards into the game or world software which restricts the amount of actions in a certain time a player can perform - just in case the software contains bugs like the Everquest bug that caused an increase in game currency of 20% within one day.
Automated attacks play a major role in virtual worlds and the paper provides links to the glider case in WoW and on countermeasures (the warden). Bots and bot detection are going to be major problems for virtual worlds - under the assumption that they try to reproduce real world features like scarceness, human limitations etc. But what about worlds that do not follow the real world metaphor?
And of course the virtual worlds have their share of social engineering tactics which can lead to involuntary suicide and the disclosure of private information. Building an online identity in a virtual world which gets reinforced by the same identity in other places (social networks, blogs etc.) finally leads to a rather convincing overall identity, doesn't it?
Primed by the paper I ordered Exploiting Online Games: Cheating in Massively Distributed Systems which I will talk about later.
- 6th IBM Day at HDM: the many facets of modern Information Technology, more...
-
 Organized by Bernard Clark, IBM University Relations Program Ambassador to HDM, representatives of IBM Global Business Services (GBS) are presenting current topics in information technology at the 6th IBM University Day. The Computer Science and Media faculty at HDM welcomes the opportunity for industry specialists, students and accademia to learn about the many faces of modern information technology - presented by world class specialists who are involved in large scale international projects.
From 9.00 - 15.15 a range of interesting work and strategies from different areas of IT are presented. It starts with "change management" and already the first topic shows how interdisciplinary modern IT has become. Next to technical know-how soft-skills are absolutely necessary for successful change management projects.
Organized by Bernard Clark, IBM University Relations Program Ambassador to HDM, representatives of IBM Global Business Services (GBS) are presenting current topics in information technology at the 6th IBM University Day. The Computer Science and Media faculty at HDM welcomes the opportunity for industry specialists, students and accademia to learn about the many faces of modern information technology - presented by world class specialists who are involved in large scale international projects.
From 9.00 - 15.15 a range of interesting work and strategies from different areas of IT are presented. It starts with "change management" and already the first topic shows how interdisciplinary modern IT has become. Next to technical know-how soft-skills are absolutely necessary for successful change management projects.Everybody talks about Web 2.0. But how do you use it in the context of a large portal? What kind of AJAX framework could be integrated? Here is a chance for everybody to get some hands-on knowledge about those new technologies and their successful implementation.
And everybody talks about the "internet of things". Sensors, actors and computers all connected and all talking to each other in a rather autonomous fashion. Few people realize that something rather critical is needed to make those plans fly: a new internet is needed. Or better: an internet that has many more computer (IP) addresses available as the current one. After all, all these sensors and actors need a name to be addressed later. The presentation will give a short introduction to IP Version 6, the next generation of internet protocols and its consequences for makers and users of the internet.
Finally another hotly debated concept: ITIL - a new standard for successful management and maintenance of large scale computer infrastructures. After all, Flickr and Co. need huge computing resources to fight flash crowds and to be available at all times. The immense costs associated with those infrastructures need careful management an planning. Learn how to use the ITIL standard for this purpose.
A more detailed program can be downloaded.
The presentations are running concurrently to the Master Information Day at HDM. For visitors the IBM Day is an excellent opportunity to learn more about the themes covered in computer science and media and perhaps to talk to some business consultants or representatives of CS&M directly.
PROGRAM for 12.12.2008
- 9.00 - 9.30 Uhr
-
Welcome and a short presentation of the University Relations Program of IBM und its relevance for HDM Prof. Walter Kriha, HdM, Computer Science and Media, HDM Bernard Clark - Senior IT Architect, Managing Consultant and IBM University Relations Program Ambassador to HDM
- 9.30 - 10.30 Uhr
-
Management of Change in IT Projects Dipl.-Ing. Markus Samarajiwa, Senior Managing Consultant, IBM Global Business Services
- 10.45 - 11.45 Uhr
-
Web 2.0 with Dojo and WebSphere Portal: Less talk, more action! Peter Kutschera, Senior IT Architect and Managing Consultant IBM Global Business Services
- 11.45 - 13.00 Uhr Lunch Break
-
The S-Bar at HDM offers several different dishes and snacks
- 13.00 - 14.00 Uhr
-
IP Version 6, the Next Generation Internet Protocol allows all people and things on earth access to the global Internet. Peter Demharter, IBM Certified Senior IT Architect Infrastucture IBM Global Technology Services
- 14.00 - 15.00 Uhr
-
ITIL or "How to manage IT Services". An overview from a practical perspective. Dr. Martin Lubenow, Managing Consultant IBM Global Business Services
- 15.00 - 15.15 Uhr
-
Wrap-Up Walter Kriha, HdM Bernard Clark, IBM
Contact: Prof. Walter Kriha Computer Science and Media, HDM E-Mail: kriha@hdm-stuttgart.de
Note
The presentations are free and open to the interested public. No registration is needed. All talks will be recorded and streamed live to the internet. Please visit the HDM Homepage for updates to the streaming URL or for driving directions. The presentations are held on December 12 2008 at HDM, Nobelstrasse 10, 70569 Stuttgart. Room 056.
- Security Architecture in Browsers and Operating Systems
-
Several papers on Chromium/IE8, Vista security, Sel4, tainting and concurrency are proof of an increasing interest in a secure architecture of mission critical software. And there are interesting commonalities to be detected between different platforms. Let's start with the new Chromium Browser from Google. Adam Barth, Charles Reis, Colin Jackson and the Google Chrome team wrote on "The Security Architecture of the Chromium Browser" . The short paper explains why the team decided to use a sandbox model and where the overall isolation barriers have been drawn: between the browser kernel and the (possibly compromised) renderer.
There seems to be no doubt about the necessity of further isolation between components. Unclear is how granular the isolation has to be (e.g. every page running in a different process or just every site or only the plug-ins). But there is the big enemy of all those approaches: compatibility. The paper makes it very clear that once you want your browser to act compatible to others you will have to make major compromises in security. Chromium finally tries to prevent the installation of malicious code or the exposure of user data. It does so by separating plug-ins into different processes connected via IPC (a common method for isolation between core and extensions). And it uses different instances of renderers for sites. But if one instanc of a renderer is compromised there is nothing stopping it from compromising pages from other sites.
Going further in isolation - e.g. the way the DARPA browser operates - would make some sites unusable with Chromium.
If you look at the second paper by Mark Dowd and Alexander Sotirov "Bypassing Browser Memory Protections - Setting back browser security by 10 years" then compatibility is again the major culprit behind security vulnerabilities: for reasons of backword compatibility Vistas memory protection mechanisms like DAP and ASLR or the canaries have so many exceptions that it is possible to assemble the ideal attack base using the dynamic load mechanism of e.g. a browser. I won't go into details here but I've discussed the problems in our upcoming second volume on "Sichere Systeme" .
The google paper uses known security vulnerabilities from the past to judge the effectivity of their new mechanisms. This is a clever use of those databases but does not constitute a more stringent security analysis with proofs (e.g. by showing that certain effects are not possible because a component is unreachable from compromised code). Again, parsing turns out to be a major weakness. The team found that the parsing of call parameters frequently created security holes which would not be prevented by the sandbox. This is a well known attack path and is discussed under the term "designation vs. authority" in the capability movement.
Some interesting papers were also published by people at HDM. Rene Schneider - well known author of the "mobmap" add-on to WoW and the SpeedyDragon web application - has written a paper on tainting as a general security mechanism. He shows how tainting is used in WorldOfWarcraft: to prevent illegal or UNEXPECTED call graphs between framework and extensions. And he explains how certain frequently happening browser bugs could be prevented using tainting (I don't think e.g. that the two world model of Chromium really prevents scripts from being executed in the wrong security "mode" - problem that all mode like architectures present and that could be mitigated using taints.
Kai Jäger wrote a thesis on "finding parallelism - how to survive in a multicore world". Besides an extremely readable introduction to the problematic world of concurrency with its non-determinisms and its problem with composability the thesis contains statements from famous language designers like Stroustrup, Wall etc. on how to deal with concurrency at the language level. A must read.
Secure Microkernels are getting more and more attention. Benjamin Zaiser "Sel3 - Ein sicherer Microkernel, HDM 2008 wrote an introduction to L4 and its many derivatives. The paper collects the work done in this area and includes also information on the formal verification technology used. The way the kernels prevent DOS by applications using resouce capabilities is also explained.
And last but not least Marc Seeger wrote an excellent thesis on Anonymity in P2P File Sharing Applications . He investigated how Gnutella and many other distributed systems work, explaining mechanisms and deficiences like vulnerabilities due to hop counters. He also explains the concept behind so called "bright nets" whick present a very interesting approach - legally, socially and technically. Of all platforms P2P systems seem to be the least known with respect to security and present a major field for research.
- Finally - the second volume "Sichere Systeme" is done!
-
 And just at the right time: system security is slowly getting more attention with google and microsoft trying new browser architectures. The book covers a lot of critical areas: usability, attacks, platform security and frameworks, browser archtictectures etc. I will also post links to papers and thesis work from HDM people. We had some good work recently on concurrency, anonymity, tainting and Sel4. And we managed to get a guest author: Fred Spiessens wrote a chapter on a langauage and model checker for capability systems. Scoll and Scollar are now an open source projects.
And just at the right time: system security is slowly getting more attention with google and microsoft trying new browser architectures. The book covers a lot of critical areas: usability, attacks, platform security and frameworks, browser archtictectures etc. I will also post links to papers and thesis work from HDM people. We had some good work recently on concurrency, anonymity, tainting and Sel4. And we managed to get a guest author: Fred Spiessens wrote a chapter on a langauage and model checker for capability systems. Scoll and Scollar are now an open source projects. - 5th gamesday at HDM - development of computer games
-
 I almost can't believe it myself. But the beautiful poster - again created by our graphic artist Valentin Schwind - is proof: This is really our fifth gameday event at HDM. And it looks like it is now reaching beyond mere academics. More and more companies (large ones like Microsoft with Xbox live) and smaller, regional game companies both will be present to demonstrate their latest game engines, boxes and strategies for the ever booming game market.
I almost can't believe it myself. But the beautiful poster - again created by our graphic artist Valentin Schwind - is proof: This is really our fifth gameday event at HDM. And it looks like it is now reaching beyond mere academics. More and more companies (large ones like Microsoft with Xbox live) and smaller, regional game companies both will be present to demonstrate their latest game engines, boxes and strategies for the ever booming game market.This time the focus is on game development and we will learn about all kinds of development in games, e.g. how to build a WOW client extension backed by a large server side application. Or how to build game engines, simulations of business processes etc. Artificial intelligence in games will be covered as well as development of mobile games.
Never before we had such an international program that includes companies from all over the world. If you want to get on overview of the extremely active game industry and its products and technologies - the gamesday is your event. And if you want to get our hands dirty: game demonstrations and a 3D workshop will let you get first hand knowledge about game development.
Note
The 5th gamesday at HDM will be held on 13.06.2008. It starts at 9.00 in the audimax at HDM Nobelstrasse 10. The day is open to the interested public and free of charge. The orgnization team provided a special gamesday homepage where you can find the agenda, links to live stream, chat and blog and participating companies.
- Infoq.com - a new information portal
-
Frank Falkenberg pointed me to infoq.com , a new portal site created by the founder of theserverside.com, the most important portal site for enterprise development on J2EE platforms. I am rapidly becoming a regular visitor on infoq.com. I found good articles on map/reduce technology as well as the latest on the SocGen scandal which cost 5 billion euro. Frank also pointed me to a very interesting video on the design of infoq.com itself.. According to Frank it shows clearly that such a special piece of website requires special programming and cannot easily be done with a COTS content management system.
- Software Quality - not really a secret
-
A few afterthoughts on our Test and Quality day recently. One of the goals of this day was to see testing and quality strategies from different areas and branches. Starting with a Telelogic based project of RUS - the datacenter of the University of Stuttgart - we saw an approach that tries to put the quality right into the model. An enriched model contains almost everything necessary to perform model-checking. This means that we can ask the model whether the system that has been modelled will perform correctly.
That's a big step of course. Of course the next step would be to generate code (or to build a server to interpret the model) and thereby almost guarantee the correctness of the code. The generation of test code and test cases should be possible as well. Test code is still needed because generation or the runtime platforms might introduce errors and bugs. Even monitoring should be created from the model.
While a perfectly reasonable approach it is still very advanced technology and raises the bar for developers considerably. They have to work on much higher levels of abstraction. IBM has just acquired Telelogic of Sweden and agains emphasizes that they see the future clearly in modeling instead of writing code. But the integration of another modeling technology after swallowing the Rational modeling and tool chain might prove to be very challenging. Already now the new RAD tool is a monster regarding CPU and RAM requirements.
In most cases the test code will still be created after the application has been written. This is a sad fact of life for test tool builders like the company eXept with their eXpecco workflow and test tool suite. And it makes it paramount to make test case creation as easy as possible, clearly separating work for developers (like building interfaces to the system under test) from test personell writing test cases. eXpecco uses activity diagrams to achieve this goal and is quite a bit more user friendly in this respect than the model-checking approach mentioned above which uses test drivers written in C.
Still, software architecture should be created with testing in mind. Small things like binding GUI elements to fixed IDs which are explained and maintained within repositories would make test case creation much faster and safer. Is it really asking for too much when I say that the bindings for an advanced test tool like eXpecco should be generated or written during the software development already?
Ruby is big at Ascom - this has been demonstrated by Christian Kaas who presented a thesis by Markus Zobel. The thesis was a joint work between HDM and Ascom and had its focus on a further enhancement and integration of the Ascom test suite for their operational base software, built on oopen source standards and tools. Besides the successful implementation of test drivers, reporting interfaces etc. I had the feeling that the thsis excelled in another area as well: Markus Zobel really went to the different stakeholders (developers, project managers, testers) and asked for their requirements. The resulting test suite offers different interfaces for different groups and is fully integrated into the development and deployment cycle at Ascom.
Slowly the focus switched more and more to the source code itself. Everybody agreed that we end up with way too many defects after development. Test-driven development seems to be an answer to this problem and M. Baranowski gave us an excellent introduction first into Unit Tests and then into building and running a test-driven development process. He showed us how the Internet agency he is working for moved to a test-driven development process and what the company gained by doing so.
And it looks like that the introduction of such a methodology is more of an organizational and perhaps psychological challenge than a technical one. Of course, there are subtle dependencies, e.g. on a dependency injection approach like it is used in Spring. Dependency Injection or Inversion of Control as it is also called enables us to easily feed mock up objects for testing purposes into code without requiring code changes.
In the meantime I had the joy of spending a whole day debugging GUI and other application code with a colleage. Of course it was fun to do pair programming again. Only that we had to debug code from others and the tool we used was our debugger. After finding and fixing a number of bugs I realized that the whole day effort kind of left us with nothing much at the end of the day. Sure, we had made some minor changes to code and fixed some bugs. But what could we show for automation of our process? Next time we would again be forced to use a manual debugging session to find problems OR TO VERIFY THE CORRECTNESS of our code. With unit tests we could have put our experience into cans and reuse them later. Let's face it: debugging with a good debugger is fun and quite effective with respect to finding bugs. It is absolutely useless for improving our development quality for the future and forces us into manual mode again and again where we should use automatic tests instead.
I skipped one talk between the last two and the reason is that this talk was special. Thanks to my colleague Roland Kiefer I was able to invite a specialist from a completely different area - in this case from a telecommunication instruments company. The idea was to take a look at a different branch to compare the way they detect errors and deal with bugs. Mr. Heider did an excellent job in showing us the differences and they are not as we expected them.
We all know that multi-tier applications are hard to write and test. In most cases there are several different components on sometimes three or four different machines involved: front-end (browser), middle-tier (business logic) and backend (database, mainframe). How complicated and error prone! But it turned out that telecommunication is WAY MORE DISTRIBUTED and has WAY MORE ERROR CASES due e.g. to physical effects like wire bendings etc. But they seem to be able to find and fix bugs much faster and easier and they certainly can provide a better level of service in most cases than we can. How come?
If we take a closer look at their procedures we can discover a number of rather big differences. E.g. that base components are usually rather completely tested. They even have parts of the test routines already built into them. This e.g. allows powerful diagnostics to run quickly. Complete test coverage and built in test routines for a start.
But it goes on. On every hierarchy level there are monitoring and test tools working at all times. They report problems to higer level test and monitoring components and so on. The higher level components perform aggregation of test and monitoring results from different lower parts and can thereby generate semantically meaningful messages. This process resembles Complex-Event-Processing and Mr.Haider mentioned that it wil be further extended in the future.
The granularity of monitoring and tracking is enormous. Cable problems need to be identified quickly and exactly where they happen. Any kind of machine failure needs to be detected, recognized and reportet. And in many cases test equipment will be dynamically enabled in case of diagnostic problems.
All in all I got the impression that other branches like telcommunications are much more advanced with respect to testing and quality. Testing and quality seem to have become an integral part of their development and operational strategy and otherwise the whole system with its many levels and protocols and physical equipment types would probably never work.
- Security Day on Risks, Anonymity, Underground Economy and Abuse, the rhetorics and reality of control, Safer Visa etc.
-
Are you getting a queasy feeling while driving under highway-bridges with people standing on the bridge? Does it help to think about the odds of becoming a victim? Or is there a layer just below rationality in your brain that makes you look, worry etc. even when your brain says that the chances of becoming a victim are slim? Besides security technology we will talk about our "stone-age brain" and how it deals with risk. And we will learn how the attitude towards risk changes over time.
 This security day takes us way beyond the classical view of security as a technological problem. Now we go after the core concepts like risks and how we deal with risks on a psychological and sociological level. And we ask what security really is: is it unilateral? Is it by necessity something bilateral or multi-lateral? How can we be tricked into accepting things "for our safety"? Dr. Michael Zwick (Social Sciences Faculty at the University of Stuttgart) will explain to us the "social construction of risk" and the evolution of the risk concept from the middle ages till today.
This security day takes us way beyond the classical view of security as a technological problem. Now we go after the core concepts like risks and how we deal with risks on a psychological and sociological level. And we ask what security really is: is it unilateral? Is it by necessity something bilateral or multi-lateral? How can we be tricked into accepting things "for our safety"? Dr. Michael Zwick (Social Sciences Faculty at the University of Stuttgart) will explain to us the "social construction of risk" and the evolution of the risk concept from the middle ages till today.The question of risk awareness is core for IT security specialists as well. We - developers and security people - are not beyond making grave errors in risk assessment: "it won't happen to me" is the title of Dr. Volker Scheidemanns talk (he is a cryptography specialist and manager with apsec . What makes us so sure that we won't be next?
We will also learn new things about the underground economy and how to fight abuse of systems. Tobias Knecht will give us an upgrade on what is going on in the underground economy currently. I still remember his first talk here at HDM and it has been a highlight ever since. This will lead over to a short talk by Christian Fesser (Computer Science and Media Faculty): Electronic commerce has always been a target for the underground economy and its players. Christian Feser will explain "Verified by Visa" and other technologies as a follow-up to SET.
These issues are closely tied to the question of anonymity: is anonymity necessary? evil? and what kind of tools and concepts exist for anonymity e.g. in peer-to-peer networks. Marc Seeger (Computer Science and Media Faculty) is currently finishing his thesis on anonymity and he will give us a short overview on the results. This is work in progress though.
The rhetorics of control will be explained by Sandro Gaycken, the author of 1984.exe . What makes new control measures necessary? Are the dangers real? Or do we see the expansion of security technology into every day life simply because it can be done? The video practices of Lidle and many (most?) of the other stores make this topic more important than ever.
Unconfirmed rumors have it that the Chaos Computer Club Stuttgart (CCCS) will be present to take your fingerprints (or why else would they bring 20 litres of gooey stuff?).
Again, the program of this Security Day goes well beyond mere technology. If you are interested even a little bit in what is going on in the areas of safety, security and control you should join us on this day.
Note
25.4.2008, 9.00, room 011 (audimax), Security Day at HDM Nobelstrasse 10. Open to the public and free of charge. You can find directions to HDM at the HDM homepage . Agenda, url for live stream and chat can be found at the Security Day Page.
- API is UI or "Why API matters"
-
The cryptic title stands for an important but frequently overlooked aspect of API design: an API is a user interface for programmers. True, its design should be stable, perhaps extensible etc. But finally programmers will have to live with it and its quality - or the lack of it.
Christophe Gevaudan pointed me to an article by Michi Hennig (I know him from the former disobj mailing list) in the queue magazine of ACM on the importance of APIs. The author used a simple but striking example: the select system call API in .NET as a thin wrapper on top of the native W32 API. The way the select call was designed had already its problems but the port to windows made it worse. The author lists a couple of API defects that finally resulted in more than 100 lines of additional code in the application using it. Code that was rather complicated and error prone and that could have been avoided easily with a better interface specification of the select API.
For the non-unix people out there: The select system call lets one thread watch over a whole group of file descriptors (read input/output/error sources). Once a file descriptor changes its state, e.g. because of data that arrived, the thread is notified by returning from the select call. The select call also allows the thread to set a timeout in case no file descriptor shows any activity.
What are the problems of the select API? The first one according to the author is that the lists of filedescriptors that need to be monitored are clobbered by the select system call every time it is called. This means that the variables containing the file descriptors are used by the system call to report new activities - thereby destroying the callers settings who must again and again set the file descriptors it is interested in. The list of error file descriptors btw. seems to be rather unnecessary as most callers are only interested in errors on those sources they are really watching for input or output. To provide an error list of file descriptors to watch should not be a default.
But it gets worse: The timeout value is specified in microseconds which leads to a whopping 32 minute maximum timeout value for a server calling select. This is definitely not enough for some servers and now callers are forced to program code that catches the short timeout and transparently repeat the select call until a resonable value for a timeout is reached. Of course - on every return from the select caused by a timeout the callers data variables are desroyed. And on top of this: the select call does not tell the caller e.g. via a return call, whether it returned due to a timeout or a regular activity on one of the observed file descriptors. Forcing the client to go through the lists of descriptors again and again.
The author found a couple of anti-patterns in API design, one of them being the "pass the buck" pattern: The API does not want to make a decision and pushes it to the caller. Or the API does not want to carry a certain responsibility and pushed it to the client as well. A typical example in C/C++ programs is of course memory allocation. To avoid clobbering the callers variables the API could allocated memory for the notifications containing file descriptors which showed some activity. While this certainly IS ugly in those languages as it raises the question who will release that memory finally it can easily be avoided by forcing the client to allocate also those notification variables when he calls select.
But passing the buck can be more subtle: An API that does not allocate something definitely is fasater. But you have to do an end-to-end calculation: somebody then HAS TO ALLOCATE memory and the performance hit will simply happen at this moment. So while the API may test faster, it does not lead to a faster solution overall.
Similiar problems show up when there is the question of what a function should return. Lets say a function returns a string. Should it return NULL or an empty string in case of no data? Does the API REALLY need to express the semantic difference between NULL and an empty string? Or is it just lazyness on the side of the API designer? How does the decision relate to the good advice to program for the "good case" and let the bad case handle by an exception?
API design is difficult as it can substantially decrease the options of clients. But avoiding decisions does not help either. The select example really is striking as it shows how much ugly code needs to be written to deal with a bad API - again and again and again...
Finally, another subtle point: The select API uses the .NET list class to keep the file descriptors. First: this class is NOT cloneable - meaning that the client can always iterate over the whole collection to copy an existing list. A mistake in a different API causing problems here. And second: A list is NOT A SET. But select PROBABLY needs set semantics for the file descriptors - or does it make sense to have one and the same file descriptor several time in the list for input or output? This hardly makes sense but - being pragmatic - it might work. The client programmer does a quick test with duplicate FDs and voila - it works! The only question is: for how long? The behavior of select with duplicate FDs is NOT specified anywhere and the implementors are free to change their mind at any time, lets say by throwing an exception if duplicates are found? Suddenly your code crashes without a bit of a change on your side. Usiing a set type in the API would have made the semantics clear. Ambiguous interfaces and one side slowly tightening the screws causes a lot of extra activities in development projects. I have seen it: A losely defined XML RPC interface between a portal and a financial data server. And suddenly the server people decided to be more strict in their schemas...
All in all an excellent article on API design. Read it and realize that API design really is human interface design as well. It also shows you how to strike a balance between generic APIs on lower levels and specific APIs, perhaps overloaded with convenience functions, closer to applications. Method creep, parameter creep etc. are also discussed.
- Test and Quality Day at HDM
-
 The thesis work currently done at our faculty is a clear indicator for the pain in the industry: testing and quality are really big topics in the industry right now. Especially test automation and model driven testing are hot. But what does it take to do model driven testing? What kind of role does open source software play for testing? Are there tools that support an automated approach? And what should applications provide to make testing easier? Test-driven development is the keyword here and it is easier said than done. But we must start to build software for testing right from the beginning of our architectural plans.
The thesis work currently done at our faculty is a clear indicator for the pain in the industry: testing and quality are really big topics in the industry right now. Especially test automation and model driven testing are hot. But what does it take to do model driven testing? What kind of role does open source software play for testing? Are there tools that support an automated approach? And what should applications provide to make testing easier? Test-driven development is the keyword here and it is easier said than done. But we must start to build software for testing right from the beginning of our architectural plans.Do other areas have different approaches towards testing and quality? We are glad to present a representative from the telecommunication industrie to give us an overview of their testing methodologies and procedures. Software can only win by learning from others. To me a visit to the IBM mainframe test department in Böblingen opened up a whole new view on software testing: it needs to start small otherwise the system under test quickly leaves what can be covered by test routines.
Note
Test and Quality Day at HDM, 11.04.2008, 9.00 room 56 at Nobelstrasse 10, Stuttgart. Live stream and chat channel are provided. Please see the HDM homepage for agenda and travel info.
- Rational Risk Assessment?
-
 I guess it is about time for our Security Day with its focus on the psychology of risc assessment and handling. The online version of the welt newspaper reports that 60% of Germans are scared of becoming a victim of freeway killers, "especially women". On March 27 somebody had dropped debris from a highway bridge killing a young mother of two instantly. The hunt for the murderer(s) is still going on 10 days later. The image shows a phantom picture of a group of youth suspected of being involved in the killing.
I guess it is about time for our Security Day with its focus on the psychology of risc assessment and handling. The online version of the welt newspaper reports that 60% of Germans are scared of becoming a victim of freeway killers, "especially women". On March 27 somebody had dropped debris from a highway bridge killing a young mother of two instantly. The hunt for the murderer(s) is still going on 10 days later. The image shows a phantom picture of a group of youth suspected of being involved in the killing.This sad story has all the ingedients for a completely unrealistic, irrational reaction from the general population: The incident is spectacular and gruesome. It also relates to everyday experience (driving under bridges) and could in theory happen anytime and to anybody.
It's real risk potential - real in the sense of cold statistical data - is way below the risc felt by the population. It is important to understand that this reaction is very natural because it is caused by our genetic substrate formed at a time when this kind of risk assessment might have been useful. That 60% of the population now looks worried at passengers walking across freeway bridges really is natural as another story proves: Did you ever hear about hidden holes below sandy beaches? In VERY rare cases thes holes exist and might collapes - burying children in their rubble. The following link tells the story of a person that spends his vacation with his family at a beach. He spent his youth at beaches but after reading the article on hidden holes he starts worrying and watches out for suspicious looking spots. Rationally he knows that this is complete nonsense. After all, nothing ever happend to him on a beach and statistically there are clearly more dangerous things that could happen there (like drowning, heat stroke etc.). But his stone-age brain keeps looking for the rare, unlikely but spectacular risk. The author of this story argues that the so called "full disclosure" of risks might have rather irrational side-effects on our brain.
Again, we need to realize that this is a natural reaction strong enough to fight the rational parts of our brain. And that this reaction is easily abused by politicians and companies. Given such risks we are ready to give up civil rights or to buy useless security junk that might even decrease our security.
The cited article also contains the excellent diagram from the National Security Council (NSC) agency on real risks and probabilities, e.g. of dying in a car or plane accident.
 It is in stark contrast to the way we feel about risks.
It is in stark contrast to the way we feel about risks. - The IBM Unified Method Framework
-
 The workshop on IBMs very successful method for architecture development - the brandnew IBM Unified Method Framework - a unification of the Global Services Method and Rational technology - will now be held for the fifth time at the computer science faculty at Hochschule der Medien. Again presented by Bernard Clark, Senior IT Architect and Managing Consultant at IBM GBS and University Ambassador for HDM, the workshop will introduce participants to a fast, semi-formal approach towards large projects. Developing visions, strategies, architectural and operational models, risc and governance aspects etc are all included..
The workshop on IBMs very successful method for architecture development - the brandnew IBM Unified Method Framework - a unification of the Global Services Method and Rational technology - will now be held for the fifth time at the computer science faculty at Hochschule der Medien. Again presented by Bernard Clark, Senior IT Architect and Managing Consultant at IBM GBS and University Ambassador for HDM, the workshop will introduce participants to a fast, semi-formal approach towards large projects. Developing visions, strategies, architectural and operational models, risc and governance aspects etc are all included.. Today new media and platforms like virtual worlds affect business plans. One of the tasks in the workshop will be to include new channels and media into an overall strategy..
Participants need to prepare for a rather busy two weeks (with one week off between) and three workshop days. Between the workshop days they will have to create workproducts. Those products will then be presented and aligned with other groups on workshop days.
Note
Starting Friday 28.4.08, 9.00 at HDM Nobelstrasse 10, room 041. Contact me if you want to attend
- OpenID and the Cross-Site-Access-Control Specification of W3C
-
These are the two specifications I have read recently. And I am not really sure about their quality. The openID spec. invents a vompletely new kind of terminology for web based single-sign on. No Liberty, no web-services, no SAML. Just new. It seems to have problems with attacks by services on the user. And its overall security is unclear to me. If you know better, please let me know!
The other spec puts meta-data into http-headers or XML attributes to tell the browser from which sites cross-site requests to those pages would be OK. This puts a lot of responsibility on the browser. At least it got clear that SSO (perhaps with silent login) in the intranets is rather dangerous as those pages are only protected by a firewall and the browser behavior. Same as abovoe: if you know better, let me know!
- Thou shallst not write parsers by hand!
-
Just a short reminder: Again and again I see parsers implemented by hand. This approach has a large number of disadvantages: it is hard to find bugs in source code, much harder than finding them in a grammer. And when the grammer changes you will have to adjust your code manually. I have seen changes happen to specifications so many times that I know what I am saying. Once a project dealing with financial instruments (and lots of them) had to recognize a major change in the international standards only four days prior the planned release day. Luckily the project had decided on generating all the mappings from those specifications automatically via a generated Compiler-Compiler and was able to keep the release day.
There are endless numbers of tools for parser construction available. Take a look at the "Antlr" book by the creator of ANTLR, Terrence Parr. If you are lacking some theoretical background you can either go for the huge (1000 pages) "Dragon-book" by Aho/Ullman or get the beautiful and much shorter book Compiler Construction by Niklaus Wirth (sencond edition). Please go to the amazon page as it has a fix for the installation bug on the disk.
And don't forget that network protocols are languages too!
- Morphware and Configware - the impact of reconfigurable hardware on software methodology
-
The paper in "Nature based Computing" by Reiner Hartenstein from the technical University of Kaiserslautern caught my attention because it mentioned configuration. Hartenstein describes the move towards configurable hardware as a new computing paradigm. Morphware means some form of FPGA type of hardware (field programmable gate array). Its special cabability lies in its possibilities for reconfiguration instead of having to develop a new ASIC (application specific integrated circuit). ASICS have lost a lot of their charme because FPGAs allow faster and cheaper solutions.
How does it work? At the core of morphware is a static or dynamic configuration of configurable hardware blocks (CLB), in ohter words the configuration of the routing of those elements.
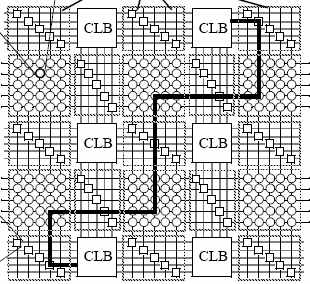 (diagram from the Hartenstein paper)
(diagram from the Hartenstein paper)What are the differences to regular computing in the classic von Neumann architecture sense? Regular means that computing resources are fixed (e.g. the CPU) and algorithms are flexible. The CPU loads algorithms and data and performs the computations. This happens at runtime and is mostly procedural (time based).
Configware or morphware changes the hardware up front (sometimes dynamically) but it is not procedural. Configuration information is of structural nature (space based). The advantages of configuration are that it can happen BEFORE runtime and it frees the architecture from instruction loading (the von Neumann bottleneck). The disadvantages are considerable complexity of this structural information and a very delicate situation when dynamic reconfiguration is needed.
Hartenstein pleads for a better support for this computing paradigm by computer science. Special compilers e.g. are needed. And he claims that most students never learn this type of computation and have a hard time translating procedural algorithms into structural configuration. Data flow approaches are also rather unknown to most.
From a software development point of view unfortunately I do not know whether his expectations are justified. We are now looking back at about 10 years or more of configuration information being pulled out of software languages. J2EE may be the best example for this but configuration information has played a huge role in operating systems and regular applications as well.
To separate context and concerns from applications (e.g. to make them independent of specific environments and allow shippping as a component) or simply to make an application a little bit better customizable we have created huge configuration bases, mostly based on XML nowadays. I cannot say that this approach has really been a big success. What we see now is configuration information as a huge source for mistakes. Configuration Information that does not fit to the code anymore and so on. It looks like modern languages like Ruby try to avoid this chasm and make the software flexible instead.
What Hartenstein wants really is a hard software problem: there a different environments (code, configuration) with the configuration information working at a higher level of abstraction which might not be represented directly in the code or hardware. But it is a very interesting idea and finally: a programmer changing something in code must have some kind of structural information in her head if the code has structural elements as well.
- Cold Reading Patterns - when profiling meets the astro channel
-
I just updated my introduction to desing patterns with some input from others. Bruce Schneiers cryptogram recently had a feature on how profilers (specialist who are supposed to give hints on serial killers etc.) frequently phrase their "results". The language constructs used come suspiciously close to those used in cold reading, e.g. on the astro channel (this is where you go if you want to know your future (;-)). The trick is to use patterns that make it very hard for others to accuse you of saying something wrong. Patterns for vagueness and so on. I had lots of fun with those.
Another link added came from Marc Seeger. He pointed me to an excellent new pattern repository with 100 of the most popular software development patterns with diagrams .
- The current banking crisis - dangers and consequences
-
Banks and financial services in general are rather important subsystems within the economy - Lenins famous words on banks and insurances being the commando heights of capitalism are unforgotten. The current crisis, mostly driven by the break-down of US subprime mortgages, shows serious weaknesses and perhaps fatal flaws in the banking and political systems. Heise featured a nice article on the banking system and its financial tools like derivatives under the title Depression 2.0: Die Inflation frisst ihre Kinder by Artur P. Schmidt/Otto E. Rössler.
Two things are memorable in this article. The first is the mechanism by which bad real-estate mortgages can be sold as reasonable investments to clients. The trick is to partition those bad credits, mixing them with some better real-estate mortgages and turning them into DERIVATIVES - financial instruments which are not available on public markets. Those derivatives are created by mathematicians and their value is determined according to some mathematical model (marked to model) and not by market forces (marked to market). This is inherently a danger for banks and that's why they like to sell those derivatives to their clients (or other banks). The problem here is - as the Heise article points out - that the bad mortgages do not REALLY disappear. Once the mortgage takers default on their payments some buyers of those derivatives will have a problem.
We have now the situation that banks do no longer accept those papers from other banks and they do not trust each other anymore because nobody knows how many of those bad papers are still owned by banks. Selling those positions is a long term process and takes many month, so a fast solution for banks is not in sight.
This situation has some consequences on a worldwide scale. The US dollar needs to be cheap now to avoid even more US mortage takers going bankrupt. The price of houses falls due to many owners being forced to sell. The solution chosen by the US national banks is easy: print more and more dollars. And the US are not the only ones running the money printers at high speed. Another side-effect is that mergers and acquisitions do no longer find financing because M&A specialists cannot assemble enough credit to buy the target.
In Germany we see another result: an unusually high inflation rate of nearly 3 percent. This is simply stealing money from the common people. And that is not all. Recently we learned that the German Landesbanken lost about 20 Billion Euro with subprime credits etc. This is not shareholder money like in the case of UBS, Credit Suisse etc. This is taxpayer money, gambled away by state-backed institutes run by greedy politicians. There is now only the hope that the EU will take those Landesbanken out of the hands of our politicians. Obviously, doing risky deals while having the taxpayers as backup is a rather simple business model....
Is this all about the banking crisis? If so, we would have to ask ourselves questions like "with how many billion Euro did Europe support the US consummation of goods for free?" Unfortunately this is not all there is. It makes our politicians, bankers and finally ourselves look rather stupid but that is not fatal. It gets worse!
Take a look at the following article about the next bubble about to burst: The Credit Card Bubble. The following is an excerpt from this article: “In case you didn't know, there is another bubble, growing massively in this country, getting ready to burst. Revolving consumer credit card debt continues to grow each month, finally breaking the $900 Billion dollar mark for the first time last June. The Federal Reserve reports that this year, Americans have piled on $39 Billion in new credit card debt. We refer to the looming crisis as the credit card tsunami. You better batten down the hatches! For the month of August 2007, USA, consumers added another $6.2 Billion in new debt, on top of the $5.6 Billion they racked up in July. Overall, including everything except mortgages, Americans owe almost $ 2.5 TRILLION DOLLARS in debt! Now that the mortgage game is over, and all that easy money has been made, the next big thing the banks will milk for maximum growth and profits are credit cards. Fees and penalties have been steadily increasing for years, as have average interest rates. Last year, the banks made over $100 Billion in interest & another $50 Billion in Fees & Penalties; these guys are not your friends. Many people, who are being squeezed by the bursting housing bubble, are increasingly relying on their credit cards to live. Since the spigot to the home equity money has run dry, and their lifestyles are not changing, or circumstances like lost jobs or medical hardships cause them to continue to rely on credit cards, there is no end in sight to how much additional debt John Q. Public will take on. At some point, the dam has to burst, and a lot of people are going to drown. .... ”
What makes many people rather angry currently is the fact that greed and stupidity are now threatening once of the most important subsystems within economy and society. Right now the danger lies in institutes or financial service companies that insure credits and mortgages going belly-up. This would turn hundreds of billions of credits into low security values whose values need to be downgraded. To avoid this disaster banks are now forced to support those institutes with billions. And we have the crazy situation that on one side we should let financial institutes go bancrupt due to mismanagement and gambling, and on the other side we cannot afford to let this happen for the resons spelled out above.
The FED is now also putting a lot of money into the hands of the banks. There is talk about interest rates going down to TWO percent for fear of a recession and even more financial institutes getting into trouble. But what kind of security does the FED get for its money? Guess what - the junk bonds and subprime shit that the banks seem to have heaps of. Ain't life great?
Update after the dramatic events around the so called bail-out of bad US credit derivatives worth 700 Billion dollar and the rescue of Germany's Hype Real Estate bank at a huge cost for the tax payer. And real dramatic estimates of losses in the hundreds of billions at the German landesbanken, especially LBBW. Are there people out there who understand what is going on? One of those few persons is Nouriel Roubini, economics prof. who runs an excellent blog at RGE monitor. Roubini predicted most of the events of this summer and also made clear that the US bail-out plan only serves a few super-rich families in the US. The average house-buyer who has problems paying for his mortgage gets no protection at all from this.
Let's make money is a new documentary by Erwin Wagenhofer. I have not seen it yet but from comments on the web it looks like it is a must see. It questions the way business is done in a fundamental way. When only 3 percent of the value created in third world countries stays there then something is deeply wrong with the world economic system.
- Security an education problem?
-
In January me and my colleagues attended the talk on Web Security by Stefan Schlott, CCC Ulm. The talk was very good and I learned some new things on DNS-rewriting and that Javascript only tracks the hostname while Java tracks IP numbers.
During the talks PHP got some bad PR due to dangerous features and functions provided (register_global, include_external and so on (sorry for the mistakes but I am not a PHP crack and have a hard time remembering the names of those features). Anyway, a young software developer started to defend PHP and declared the use of those features as a matter of discipline and knowledge and a short discussion on the ability of software developers to use those functions securely emerged.
I was pleased to notice that most of the people in the room (and it was a large audience) did not share his oppinion. Of course there is always the question of whether something falls into the responsibility of a person or not. Some technical concepts necessarily have to be taken care of by programmers or users. Others are better hidden in the machine.
My experience of working in the software for more than 20 years now made me rather humble: We do NOT know how to handle pairwise functions. We do NOT realize security consequences behind convenience functions and so on. Right now I am pleading for a better separation of user/programmer conceptual models and machine/language functions. We need to realize better what we can do and what we really can't. It does not matter here if some very talented and experienced developers really can avoid most problems. They can't do so consistently as the buffer-overflows with the bind protocol has shown several times.
And the same goes for regular users and commercial operating systems. We need to clearly establish responsibility and we cannot push it towards the users when they obviously can't do it right. The Microsoft approach of security by admonition (Ka-Ping Yee) is clearly exclusively driven by marketing and legal departments.
I hope to be able to do some research on usability and security in the winter term.
- Trends in the Internet of the World
-
Recently I've been interviewed by a journalist working on an overview of the Internet, its world-wide structure and some current trends. We talked about the topology, social distribution, access modes, abuse cases and so on. I've collected a number of links during the preparations (some from my colleague Prof. Roland Kiefer and his students) which I would like to share.
Is Internet access everywhere the same or do we have some differences on a worldwide scale? It turns out that Africa seems to be falling behind more and more. I noticed this in several cases, e.g. when companies were presenting their worldwide locations for research and devcelopment. Africa always comes up as a white space.
How do you know how the Internet traffic really flows? Some idea for the physical base of the internet can come from maps on sea-cables and satellites.
A very nice way to view the current distribution of traffic is to take a look at the dimes project. This project collects internet traffic data and Chris Harrison has created wonderful graphics from those data.
 It is not really a suprise that the most connections are between the US and Europe. But internally the connectivity in Europe seems to be much more distributed than in the US where we see only strong connectivity between some location s on the east coast with some on the west coast leaving the country in between almost empty.
It is not really a suprise that the most connections are between the US and Europe. But internally the connectivity in Europe seems to be much more distributed than in the US where we see only strong connectivity between some location s on the east coast with some on the west coast leaving the country in between almost empty.Information on the physical topology and structure can be found for sea cables here or here.
The next topic was backbones and their possible influence on data. I mentioned the FBI Carnivore project which was supposed to scan all mail on the internet. This project has been discontinued but smaller versions which only concentrate on network addresses are becoming standard in the EU too. But where are the points all traffic goes through? One of them surely is a Frankfort peering-point . This is where ISPs (more information on the largest ISPs can be found at the homepage of Russ Haynals homepage) route data into networks from other ISPs. I learned that till 1995 all Internet traffic was routed through the US no matter where in Europe it was supposed to end. But this does not really come as a surprise: Echelon and SWIFT tracking are well known cases where the US are spying on Europe.
I guess I should also mention here the increasing possibilities to de-anonymize previously anonymous data through cross-linking. AOL gave out some search queries for scientific studies and the scientists were able to correlate the queries with other data and to de-anonymize the data quickly. An anonymous database of movie renters had recently been decoded by cross-correlation with a movie-rating database (from Schneiers Cryptogram).
Then a difficult question came up: the digital divide - does it still exist? I had talked to one of my students who came from Indonesia and she told me that in many parts of Indonesia people only have slow dial-up connections to the internet and are therefore excluded from certain services.
This may be the case in other parts of the world too but in general I think the question of digital divide is one of eduction and not so much of technical or financial means for access to the Internet. We see the better educated move to the internet (the new "here-is-everybody" movement described by Clay Shirky). But in fact it is not everybody. The lower social groups are stuck with TV.
Access ways to the Internet was the next question and the answer here simply is: Google. With over 60% of world-wide search queries Google is the sole leader in providing access to web content, with MS and Yahoo and some other large portals trailing..
What are the consequences of search engines? A study from the University of Graz (Prof. Maurer) bitterly complains about the Google monopoly being a danger for Europe (which is certainly true) and why Google needs to be disassembled. And about the increasing plagiarism especially in the humanities. The latter point does not really convince me: how many times can one tell the history of the internet? The development of civil rights etc.? Perhaps the knowledge in the humanities does not increase as much as the number of students? Maybe the lecturers ask the wrong questions? Jeopardy style questions can be answered by google and are therefore not really an instrument to judge a students effort.
I am convinced that we need to realize that pure facts are no longer knowledge.
We also discussed manipulations of Internet data through search engines. I mentioned that the group from Graz detected that Google constantly returned higher rankings for Wikipedia pages than e.g. Microsofts search engine. The team read this as a secret collaboration between Google and Wikepedia. Shortly after the paper was written Google announced plans for its own version of a wikipedia. This would allow Google to place ads even within the wiki pages.
My personal oppinion is that pushing the ranking of Wikipedia pages makes sense as most people like to see them at the top positions. And it allows Google to show Microsoft the ropes: that Google can destroy any MS product (e.g. Encarta) easily if they want to.
- Sex, Lies and Appliances
-
Did you ever find a piece of technical information repulsive or revolting? I recently ran into a white paper by STBERNARD, a US security company . The title "Anonymizers - The Latest Threat to your Web Security" caught my attention. The article starts with the usual scare tactics ("what you don't know can hurt you") setting the stage for the ever vigiliant wannabe sheriff - your typical US manager in charge of something.
Next come some paragraphs on how anonymizers work. The problem of "one-off" anonymizers which are simply privately run proxy servers is discussed as a rather difficult one as those anonymizers are hard to detect. The article then tries to sound neutral: there are some good reasons for anonymizers, for example in coutnries where civil rights and liberties are not respected (the damned chinks of course..) and in general anonymizers are not illegal.
Bad anomymizers are of course those who violate YOUR accepted use policy (AUP) or somebody elses. Like some child protection law. This starts the next phase of the pattern: scare the user silly! Imagine what would happen if a colleague got a picture with some naked boobs on his or her desktop? You know, the Janet Jackson kind of picture which are now prevented from TV by requiring live-transmissions to show things with a certain delay (physicists probably call this the Jackson constant and it is measured in boob units). Think about the LEGAL consequences and financial damages!
The next phase goes some more into the "dangers" of anonymizers: "A. are the fastest growing threat", A. are used by students to access "top social destinations" like YouTube, mySpace and Facebook (where the sexual predators wait, sic.). But that is not enough of the dangers: network bottlenecks with "video snacks", malware introduced etc. and a comment on helpless firewalls finish the picture.
But help is not far! The problem now is to explain why STBERNARD has a solution for something so difficult to detect as anonymizers. And how such a beast could be maintained and driven by yours truly without any knowledge in security and IT. The solution is simple: an appliance (a black box) bought from STBERNARD will do the job for you. It even detects zero-day-attacks, knows which URLs lead to private anonymizers and does not need any amount of your precious time to run and maintain. this is done with the help of artificial intelligence agents running on the appliance. They perform "data forensics" by trying to detect suspicious patterns in the URL. What URL? If a client runs SSL to the anonymizer there is little left to detect for an agent without super-natural abilities. And if the solution implies breaking the SSL connections locally (SCIP proxies) then we are talking a host of new problems here. (see Internet Security
This could all be just general marketing bullshit. But there is this undercurrent of an almost religious rightousness. An emphasis on your job being the sheriff for others. And finally: STBERNARD offers a categorization of web pages. Of course they need such a thing to allow customized blocking of pages by yours truly. The biggest section there is of course everything to do with sexuality.
The whole thing just follows the typical security sales pattern: scare them and then sell them the wonderbox. This pattern is used by many security companies. But the rightousness in excluding other people form access to information or the right to assemble (which is btw. one of the core rights in the constitution, like free speech), has become typical for the US.
On another note: when you hired the last person for your company - you did a complete background check on that person, supported by a trusted security company, didn't you? Just think about the legal consequences if this person does something questionable! The hard questions you will have to answer!
- Service Level Agreements - or how to turn friends into enemies.
-
The ideas of those educated in economics never cease to surprise me. The following thoughts cam up during my latest project - an enterprise search platform architecture - which we decided to build in an agile way. The agile manifesto tells you that business is not your enemy. A representative of the business should be on-site at all times to discuss the priorities quickly. This allows you to make progess without wasting too much time in trying to capture every possible interest of the business in writing.
The goal of an agile method is to come to a good understanding between IT an business, in other words: to share a vision. To nurture informal relations which can solve problems much faster usually. The agile approach accepts the fact that business usallly cannot specify things correctly - they need help from IT doing so. And it also accepts the truth that IT cannot do everything that comes to mind. Some requirements turn out to be unrealistic. Some turn out to be a problem at the current stage and sometimes developers simply know better what to do next.
The base of a good, working relation with little overhead is trust NOT an SLA. SLA's are preparations for legal disputes. But you can't sue your own business - and the means of the business to really do hurt IT are also quite limited often. Agile methods are trust building devices. SLAs destroy trust and create enemies.
Does anybody really believe that the use of SLAs between departments is effective? And more: Has anybody EVER seen SLAs really working and making things better? Has anybody EVER seen perfect requirements specifications?
My interpretation: SLAs are the final acknowledgement by management that it is unable to create a productive, informally strong working environment within a company.
- Joe Weizenbaum or the hunt for natural intelligence
-
Joe Weizenbaum (a leading member of FIFF btw.) is dead. He wrote one of the first books that I read about computers and computer science: The power of computers and human reason - translated into german as "die Macht der Computer und die Ohnmacht der Vernunft". It is still in my bookshelf, right next to Ross Asby's Introdcution to Cybernetics, Gregory Bateson's steps to an ecology of mind and of course Doug Hofstadters famous "Gödel, Escher, Bach". Those were the times when computer science looked soooo exciting and still had the touch of innocence (disregarding its military background of course).
Joe Weizenbaum warned of misunderstanding the capabilities of computers. His "Eliza" simulation of a human shrink was naive and funny. Who would have thought that Eliza could pass the touring test. Nowadays, in the time of severe cutbacks in medicine for the lower classes I am just waiting for the next politician to demand "electronic support" for the human mind of poor citizens.
Joe Weizenbaum made me aware of the difference between "information" and "data" - the first requires a human to acquire meaning, the second a purely technical artifact that needed to be transportet without loss over noisy channels. That little example already showed the problematic relation of computer scientists to real life: a purely technical view of things can avoid the social and human side of things. Life is much easier this way as the first scientists building nuclear bombs realized early on.
But there weren't any real threats. Spiegel Magazine hat an article series on how the state would take control over citizens using computers ("Das Stahlnetz stülpt sich über uns"). But this and Joe Weizenbaums warnings were almost like a good horror movie - lots of suspense but not real danger in sight. I started working as a Unix system engineer and completely changed from a learned socialogist into a dedicated hacker. No questions asked. Life was gold.
Then the next phase of computer science started: the complete commercialization and the turn into "IT". IT is the braindead version of computerscience - nowadays. I am talking about fast going projects with new technologies that invariably failed at horrible costs. About really bad project management of software projects. About all kinds of (broken) promises for re-use, programmer productivity etc. Not to forget things like CEBIT keynotes from politicians or CEOs - we need to preserve those or our grandchildren won't believe us. I got some benefits from my previous education, mostly being able to explain the social reasons behind those drastic failures. And perhaps in being less convinced about the future of IT then my fellow hacker colleagues were.
The second phase was a lot of fun too: the internet was detected by the masses. Free downloads, chats and many other things became available for the masses. Microsoft enabled millions of people and made billions in turn.
But then the third phase started. And it started before 9/11 but that event became the starting point for what I call the quest for total control. Now Computer Science and its results are used by states and companies against citizens at a frightening pace. Permanent supervision through video cameras, total awareness of ones financial transactions (even across the ocean as the US is always listening in), automatic cat licenseplate scanning are just a few examples. RFIDs without the ability to be canceled (it would make reclamations harder!). No argument is too stupid to be used against civil rights. And in the worst case: if the superior court revokes some laws the reaction of our politicians is always the same: who cares! This was just shown
Total control in the eyes of the economy means something different: being able to control the use of things down to the last bit: toner cartridges that stop working after the defined amount of pages printed were only the beginning: Just imagine the possibilities: there is no longer the concept of "property". You don't get "property" by buying things. You get a tightly controlled lease on usage.
How do you make people completely dependent in an age of endless technical progress? Take a look at Monsanto. This company shows how the control of seeds turns into a control of food. Monsanto buys seed producers and vendors to shut them down later. This way farmers cannot escape the market dominance of Monsanto products. "Roundup" and "BT" are transgenes which start to rule, contaminate and dominate all other forms of seeds throughout the world. At the price of throusands of suicides of Indian farmers every year who cannot pay the high prices for Monsanto products anymore. (The promises by Monsanto that the farmers could use less fertilizers and insectizides because of the genetically modified cotton etc. turned out to be wrong of course).
The total control phase has another advantage for management and bureaucracy: it allows you do hide behind the computer. It is not the manager who decides to not hire an employee, or to fire one. It is the computer who detected something in the past of a person and called it a risk.
IT allows a completely different way of dealing with problems. It allows going after everybody just ot weed out a few. The un-targeted search is the basic instrument of total control. An example: management suspects that some employees are cheating with their labor time. Just slap a time control system on everybody and you don't have to deal with individuals anymore. The fact that this hurts 95% of people whe did not do anything wrong is called collateral damage.
Another example for the total control approach: the EU requires from 2010 every car to be equipped with a GSM autodial unit. This is for emergency reasons only of course and also for your best. This GSM unit may be actually quite useful FOR SOME CITIZENS. But why is EVERYBODY forced to drive with such a unit? Opt-out approaches are a typical sign of abuse of power. The EU just showed another case. Verizone and ohter US providers have special machines set up with gigabit-cables running right into the offices of CIA and FBI - again it is "everybody" who becomes a victom of the total control possible through IT. The reaction from the US-goverment: announcing a general amnesty law for all companies and specialist helpful in violating everybodies civil rights.
This has been a bit of a digression from Joe Weizenbaum. But he planted the seed of criticism against IT and computer science, always in search of reason in the human mind. I don't know if he really could imagine in th 70s where we would end up today.
By a funny coincidence Clay Shirky has just written a book on "here comes everybody". He writes about the group-forming abilities of the internet as a successfull weapon for citizens against companies and governments. And at ETECH 2008 Lawrence Lessig held a talk on how to control lobbyism in congress via the collaborative web. (I will comment on ETECH and Shirky's new book in a separate posting).
It looks like Joe Weizenbaum was not the only compter scientist with a clear view on technology and its consequences. And I like the idea of the attack on everybodies rights being countered with the everybody enabling techniques of the web.
- Free your Phone - Iphone and OpenMoko
-
Last week Apple announced the IPHONE SDK. By a nice coincidence Markus Schlichting finished his Bachelor thesis on OpenMoko giving me a chance to compare several approaches to smartphones and their software.
But is "smartphone" really the right name for those devices? Both run a workstation-class operating system (Mac OS X or Linux) and get ever bigger displays and more hardware than ever (GSM, GPS, Motion-sensors etc.). The demonstration of the new Iphone SDK clearly showed Apples superior marketing skills. The SDK is not really "freeing" the Iphone in the sense of open source. But it allows e.g. Sun to port Java completely to the platform.
Besides marketing and the sensational new touch-based user interface Apples Iphone SDK seems to be quite convenient to use - even for non-Mac developers. Highly integrated, compatible with the bigger brother on Mac OS X and well connected for remote debugging and tracing the SDK brings usability also to the developers.
My colleague Prof. Johannes Maucher - head of the mobile and ambient computing group correctly pointed out that other systems have more features and already since quite some time. Still, with the combination of design and usability for developers and customers the Iphone seems to make a difference for me. (I learned one thing from our Linux Day in January: usability is one area where open source projects REALLY need to get better). And what the vidoe of the SDK presentation makes absolutely clear: the smartphones morph into the "connected everywhere, desktop substitute" device with the computing power of much larger systems. Ready for games, collaboration applications etc.
But the Iphone is not really "free" in the sense OpenMoko is. Based on a linux kernel OpenMoko supports a huge range of hardware with the "System-on-Chip" (SOC) approach. Programming for OpenMoko takes some time due to a steep learning curve at the beginning. The necessary frameworks are not as smoothly integrated as in the Apple case. Still, successful development based on GTK+ etc. can be done. There are still deficiencies in the areas security, emulation, remote-debugging etc. but this is only a question of time.
In his thesis Markus Schlichting also takes a look at other platforms like Android, Windows mobile, Symbian OS etc. and they all show different strength and weaknesses. I was surprised to learn that the Symbian based platforms are mostly incompatible with each others due to differences in GUIs. The centrally controlled licensing system ist certainly not after everybodys taste.
Android runs a Java VM but is not compatible to Java. The core of Android is another Linux OS but application programming will be done in Java only. This might create a new branch of Java over the time when more and more features are implemented to support smartphone functionality. Control over Android is unclear - at least to me.
Windows Mobile is what MS typically provides: a very good development support through the MS tool chain. It certainly lacks the Apple buzz (;.).
Marc Seeger told me that in the context of the Iphone SDK Jay Freeman (aka "saurik") needs to be mentioned. His "jailbroken" iPhone can run Java, Python and Ruby programs! He even managed to offer Objective-C connectors for the GUI-libraries on Java and Python. He brought the apt packaging system to the iPhone and created an interesting alternative to the popular closed source "Installer.app" - contrary to the "bottum up" approach of Open Moko.
- The future of computer science - 10 years of computer science and media faculty at HDM
 CS&M decided to celebrate its ten year anniversary in two ways: during the morning CS&M alumni will present current work in the industry. This will cover work in internet agencies as well as software development and human interaction e.g. at Fraunhofer IAO.
CS&M decided to celebrate its ten year anniversary in two ways: during the morning CS&M alumni will present current work in the industry. This will cover work in internet agencies as well as software development and human interaction e.g. at Fraunhofer IAO.CS currently does not really shine with its everyday results. It is either abused by sick minds steering towards an Orwellian future of total observation and control. Or it presents itself as responsible for malware, spam, badly designed applications and in general having negative effects on peoples lives.
But then Thomas Suchy and Juergen Butz from our research project "ambient intelligence" will start the track on future perspectives of computer science. How will the intelligent connection between rooms and devices create a better environment for all of us? Stefan Rupp, a well known specialist in computer networks will present the future of mobile networks. He is an old friend of the faculty and much truly visionary work has been done under his guidance.
Finally Stefan Bungart, a philosopher from IBM will speculate on a social, utilitarian future based on computer science paradigms. Yes, CS once had a disruptive quality.
The ten years of computer science and media have shown one thing for sure: computer science is more than ever connected to other sciences. You cannot do successful work on the internet without respect for the social, psychological and economic environment. The same goes for security and many other areas which were traditionally seen as "pure" computer science areas. CS today can either be ignorant of its surroundings, it can behave in a diletantic way or it can work together with other sciences towards a cybernetic view of the futere.
CS&M faculty at HDM Stuttgart is based on a solid foundation in computer science. But at the same time we enjoy excellent relations to many other faculties and disciplines like usability engineering, print, arts and so on. We encourage our students to leverage those connections and create interdisciplinary results. Join us on Thursday to discuss the future of a discipline that is currently having a profound impact on our live and will do so for the near future.
Students of CS&M will present current software and hardware projects like large multi-touch screens as part of the HDM Media Night which begins right after our event.
Note
24. January 2008, HDM Stuttgart, Nobelstrasse 10. 9.00 - 16.30. Free of charge and open to the interested public.Live stream and chat available, see agenda .
- Linux Day at HDM
-
 Our first Linux Day allows everybody to meet the legendary "revolution OS". Many different topics like linux on mobile systems, linux for high-availability, open source strategy, security with reference monitors and last but not least the KDE destop environment will be presented. And you don't have to be interested in the different meanings of "free (like in free beer, freedom etc.) to discover a very capable and feature rich platform for both business and private users. Ever thought about what kind of software private users REALLY need? I guess just about 99.9% of it is available on Linux - and in a very good quality too.
Our first Linux Day allows everybody to meet the legendary "revolution OS". Many different topics like linux on mobile systems, linux for high-availability, open source strategy, security with reference monitors and last but not least the KDE destop environment will be presented. And you don't have to be interested in the different meanings of "free (like in free beer, freedom etc.) to discover a very capable and feature rich platform for both business and private users. Ever thought about what kind of software private users REALLY need? I guess just about 99.9% of it is available on Linux - and in a very good quality too.If you own a small or medium sized business? Then you might be interested in knowing that many very large companies are heavily investing in Linux too. And they might be able to pay the MS license fees more easily...
And because KDE4.0 has just been released there will be a release party starting 18.00 at the S-Bar.
Please use our blog at linux-day.de and check for last minute informations there.
Note
9.00, Friday 18.1.2008 at HDM Stuttgart, Nobelstrasse 10. See HDM homepage for detailed information. Live stream and chat are available.
- Copyright and Copyleft
-
I have changed the copyright for my site to the Creative Commons Attribution License 2.5. To understand why read: Peter Gutmann, the cost of Vista Content Protection and Lawrence Lessig's fight against copyright based monopolies
