Development of an Enterprise Logging and Log Analysis Framework
Frequently students of our Computer Science and Media faculty write their thesis at some development lab in the industry. This often results in excellent work that combines theoretical and practical aspects and which is well received by our industry partners. At the same time it allows us to measure our work at the faculty by the success of our students.
Frequently though this work is at least in parts company confidential and not suited for publishing. Luckily Michael Zender's thesis on "Entwicklung eines Frameworks zum Loggen und Auswerten applikationsspezifischer Parameter" is under no restrictions and I am using this opportunity to show some aspects of enterprise logging that have plagued me for some years and which could be solved using Michael's approach.
I'd like to structure this article as follows:
| Technical Aspects of Logging |
| Log Analysis in the Enterprise |
| A framework for logging and analysis of application specific parameters: architecture and implementation |
Technical Aspects of Logging
For me, logging has come up several times during my career and I have noticed quite a lot of confusion about what logging is and how it should be done. And of course a lot of alternatives with respect to technology. So let's first raise a couple of questions about what logging is.
-
Logging is used to protocol business events
-
Logging is done with printf/println statements
-
Logging is for application developers to find bugs
-
Logging is inherently application specific
-
Logging is a performance hog - don't do it.
The first statement is clearly wrong. Recording of business events is called auditing and usually requires different handling with respect to channels and storage. But it can use the same API that is also used for logging. Logging is to record technical application state, possibly at a granularity that is configurable. An example how auditing is NOT done is again privided by the never ending story of e-voting machines by Diebold, now Premier Election Solutions, who apparently lost votes (recorded by logging) but nothing showed up in the audit log (or was deleted). Hat tip: Bernhard Scheffold.
Logging today is NOT done with printf/println statements. Today the API of a logging framework is used, e.g. log4j or the Java logging API which is not so much different. The reasons are simple: Only by going through a logging API the log statements can be transparently sent over different channels, formatted in a different way and last but not least become independent of platform specifics like windows event log vs. unix syslog. Another approach is to even avoid putting logging calls into your application at all. Aspect Oriented Programming allows the injection of log statements at a later time and at specific places like the begin of method calls of a certain class. But notice that the decision to log something is NOT automatic. It requires a conscious decision by an application programmer on what is deemed important to record.
Sometimes bugs are found by application programmers when they go through logs. In fact in most cases bug hunting starts with the log files sent from operations to development in case the people at operations could not figure out what is wrong. So log statements can have different recipients! And different people will need different things logged because they have a different understanding. And last but not least: what about machines as recipients? But what we are talking here are exceptional conditions which require actions, e.g. a table space that got full. Logging at a granularity that would allow software developers to find bugs is a) way to heavy to be done at runtime, b) done with debuggers or manually inserted, temporary statements and c) is called tracing.
It is true that log statements come from applications but are these statements necessarily all application specific? My favourite IBM log statement of the past was "file not found" - after installing software consisting of zillions of files! Now wouldn't this statement be usable in other applications too? Perhaps with one additional parameter? There are many different applications but when you take a closer look many of them do some form of CRUD processing and their log statements are not so much different, at least in many cases. Wouldn't it be nice to have common syntax and semantics for log statements? This would allow us to build parsers that work even after changes to log statements in the applications.
To much logging at runtime certainly can affect your performance. Measure what you are losing and adjust the log level accordingly. A slightly more subtle point is how to process the log statements: Use a fire and forget logic to transport the statements from busy application servers to dedicated logging servers with attached storage. Use proper buffering to adjust message sizes etc. Fill databases asynchronously from serving requests to clients. When logging turns out to damage performance it is done the wrong way.
Log Analysis in the Enterprise
When you add "Enterprise" to logging it means: many applications, many machines, many developers, a huge operations department, frequently changing personnel and a long, long lifetime for applications. For good measure you can also throw in many different platforms, security rules for firewalls and network bottlenecks caused by the transfer of large files.
And very likely nobody will look at all those log statements created (how many times did you look at the firewall logs in your DSL router? Still running it with the default password and the default settings? I knew it..)
Given these facts 12 years ago I thought I had the solution for a huge project supposed to build the new backbone of a large bank: Let's create a repository with all log statements defined for all log applications. Together with meta-data on the semantics of the statement and its values. Lets create a common syntax for all log statements which would allow us to use one parser only for initial processing. Developers would put their new log statements into the repository and the log framework would load them during application startup. The log framework would also enforce the use of registered statements and prevent developers from creating unknown and undefined log statements.
Machines would be able to process statements automatically, driven by meta-data and enabled through the common syntax which would make processing independent of the concrete order of statements e.g.
Much to my surprise my ideas were received with less enthusiasm than I had expected. "too slow, too big, to cumbersome, putting a cramp on my creative phases etc.." I guess it is more fun to change your parser every time a developer decides on small changes to log statements or to take a look at a log file of an application uttering "I have no bloody idea what this value means...".
And also the analysis side had some surprises in store. In many cases departments needed some kind of data really quickly and they were ready to trade elaborate analysis functions for a simple but effective way to get those results. And to have that system under their control without being dependent on other departments or global analysis projects.
Clearly the successful analysis of log files depends heavily on the way the log statements are created, especially on the available semantics. And the willingness to supply this information as well as the willingness to look at the results depends on the availabilty of a system that allows this in an easy, convenient and customizable way.
There is little doubt that clearly defined, semantically rich logging information will be a major advantage for the system monitoring and management systems of the future. While currently most logging statements are processed long after they were issued, Complex Event Processing (CEP) will lead to realtime processing of application events. This is turn requires a transformation from simple messages or log statements into semantically rich events based on clear definitions. But first we need a logging system that allows us to define, write, collect and analyze statements in a robust and easy way. And this leads over to the Michael Zender's thesis project.
A framework for logging and analysis of application specific parameters: architecture and implementation
During the requirements analysis phase of the thesis Micheal made a number of core decisions. Usability got first priority and the whole system would be based on Open Source software as much as possible to avoid re-inventing the wheel (and of course to save development time). A possible first user of the logging and analysis system was a larger enterprise search project.
The following paragraphs show only the core architecture and the mapping to software components like log4j and BIRT. Interested readers should read the excellent thesis paper (in German).
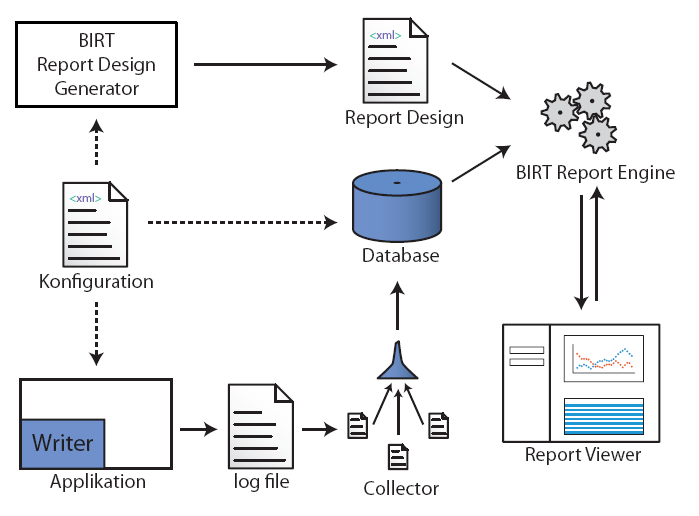 The diagram shows the core architecture. Application developers create a central configuration file which defines the structure of log entries and all the information needed to display results later on. The configuration file is created with the help of a wizard (eclipse plug-in using velocity templating). The main driver for report generation - the BIRT report design specification - is generated automatically, again using an eclipse plug-in. The same goes for the derived log4j configuration file and the database schema to load the log data. Reports are generated automatically by the BIRT reporting engine and uploaded to a web server which allows convenient access. Developers only specify the main configuration file and need not worry about access to the reports.
The diagram shows the core architecture. Application developers create a central configuration file which defines the structure of log entries and all the information needed to display results later on. The configuration file is created with the help of a wizard (eclipse plug-in using velocity templating). The main driver for report generation - the BIRT report design specification - is generated automatically, again using an eclipse plug-in. The same goes for the derived log4j configuration file and the database schema to load the log data. Reports are generated automatically by the BIRT reporting engine and uploaded to a web server which allows convenient access. Developers only specify the main configuration file and need not worry about access to the reports.
 This diagram shows a section from the main config file, especially the definition of a log record (CollectFiles). This record definition will later be mapped to a log4j logger class specifically created (automatically) for this record type. All the log statements for this record can end up in a separate file which makes the collection and insert process rather easy.
This diagram shows a section from the main config file, especially the definition of a log record (CollectFiles). This record definition will later be mapped to a log4j logger class specifically created (automatically) for this record type. All the log statements for this record can end up in a separate file which makes the collection and insert process rather easy.
Michael also created a writer API which allows developers to fill in log records in a convenient way. A record can contain several key/value pairs which can be added at different places within a class. The code simply states "Logger.getLogger("Name_Of_Log_Record_From_Config") to get the proper log4j logger class. Logging is done with the follwing code:  . The developers simply add key/value pairs to a map and hand it over to the logger. All features of log4j to define format, channels, log levels or inheritance between loggers can be used. After that a collector daemon runs and collects the log files, parses the XML and inserts the log records into the MySQL database. Finally the BIRT report engine will extract the data, create the report and make it accessible through a web interface..
. The developers simply add key/value pairs to a map and hand it over to the logger. All features of log4j to define format, channels, log levels or inheritance between loggers can be used. After that a collector daemon runs and collects the log files, parses the XML and inserts the log records into the MySQL database. Finally the BIRT report engine will extract the data, create the report and make it accessible through a web interface..
The whole solution is fully functional. A few areas for improvement exist though. There is no global repository yet which would lead to a proliferation of log record entry definitions across the enterprise. The wizard that creates configuration files would need an interface to the repository that allows developers to browse existing definitions. Perhaps a template/inheritance mechanism would be needed to prevent unnecessary duplication. The repository could contain additional meta-data about entries and should also mention possible monitoring processes which understand certain types of records. The XML syntax of the log files might require a more robust parsing process which is able to deal with incomplete records due to buffering errors etc.
Another question would be: when will the solution show scaling problems? The database is certainly something that is critical and would need a regular cleanup process. The number of files to collect? Facebook.com uses a rather interesting architecture called Scribe - a server for aggregating streaming log data .
Last but not least the documentation of the solution in the thesis paper includes a working example of all the steps needed to create a report. The assumptions about the importance of usability and open source components proved correct and the solution has been received with praise.